





CData JDBC Driver for Twitter を使って SQL でユーザーを検索する
Java コミュニティから、特定のアカウントをフォローしていないが、特定のコンテンツについてツイートしたユーザーを抽出する方法について質問がありました。この記事では、CData JDBC Driver for Twitter を使用してこのような質問に答える方法を説明します。
CData JDBC Driver for Twitter について
CData JDBC Driver for Twitter を使用すると、標準的な SQL ステートメントで Twitter データを操作できます。Twitter ドライバーを使えば、Java アプリケーションや、JDBC 標準をサポートする BI、レポート、ETL ツールから Twitter に簡単に接続できます。CData ドライバーは、ツイート、ダイレクトメッセージ、フォロワー、リプライ、リストなどのデータ操作をサポートしています。
JDBC Driver for Twitter のダウンロードとインストール
まず、Twitter JDBC Driver をダウンロードしてください: (30日間の無料トライアルはこちら)。インストーラーの指示に従ってインストールを完了します。
Java IDE で JDBC を使用して Twitter に接続する
お好みの Java IDE(Eclipse、IntelliJ、NetBeans など)または JDBC をサポートする Java ツールを選択し、ネイティブの JDBC サポートを使用して Twitter への接続を作成します。この記事では NetBeans を使用します。
- 新しい JDBC ドライバーを登録します。
- Driver: ドライバーの JAR ファイル(通常は C:\Program Files\CData\CData JDBC Driver for Twitter\lib にあります)
- Driver Class: cdata.jdbc.twitter.TwitterDriver
- Name: 任意の名前(ここでは CDataTwitter を使用)
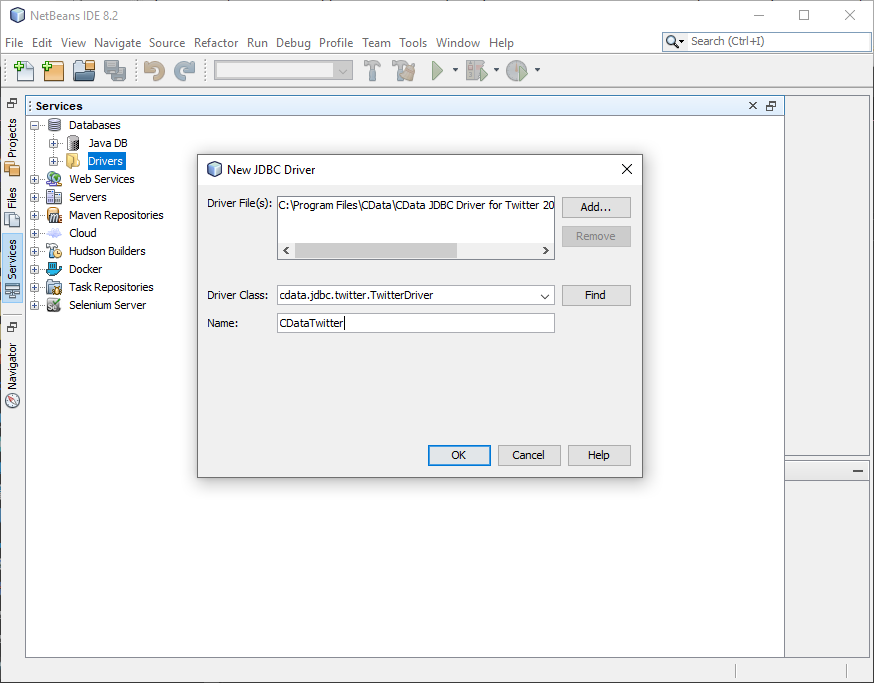
- 「OK」をクリックします。
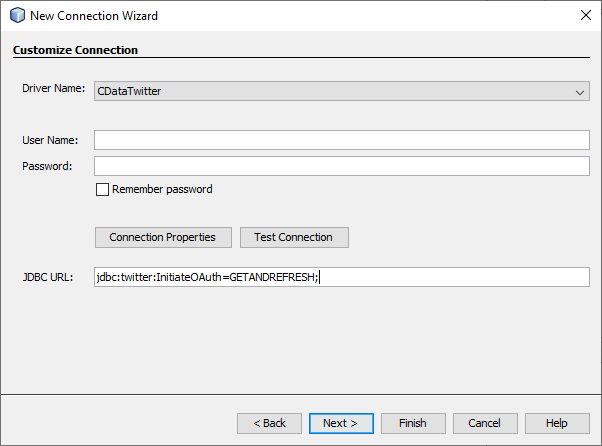
- 新しい接続を作成します。登録したドライバーを選択し、JDBC URL に認証パラメータを入力します。
例: jdbc:twitter:InitiateOAuth=GETANDREFRESH;...;
JDBC Driver for Twitter は認証に OAuth を使用します。詳細については、 Twitter JDBC Driver ヘルプドキュメントを参照してください。
- 接続のテストが成功したら、「Finish」をクリックして接続を確立し、Twitter へのクエリを開始します。
Twitter にクエリを実行する
目的のユーザーリストを取得するには、質問を表す SQL クエリを作成する必要があります。まず質問を個別のパーツに分解し、それぞれのクエリを組み合わせて目的のユーザーを見つけましょう。
自分をフォローしていないユーザーを見つける
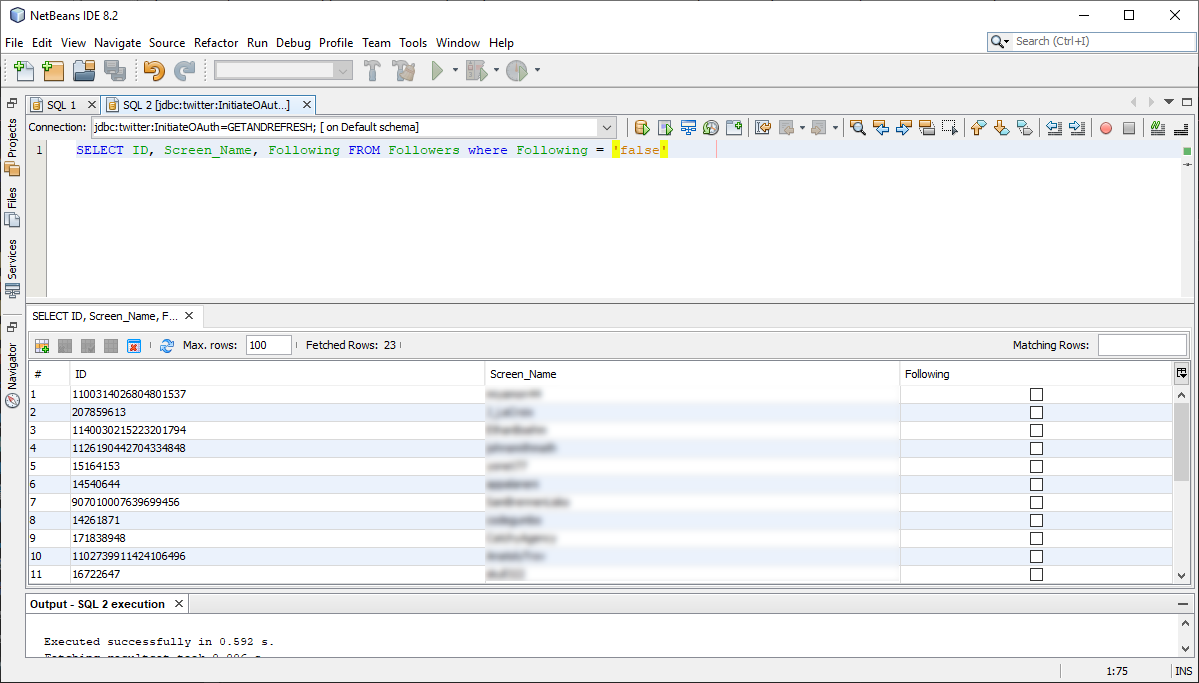
JDBC Driver for Twitter は Follower ビューを公開しており、これは自分のアカウントをフォローしている Twitter アカウントのリストです。Following カラムはブール値で、自分がフォローしているがフォローバックしていないアカウントのリストを取得するのに使用できます:
SELECT ID, Screen_Name, Following FROM Followers WHERE Following = 'false';
特定のコンテンツに関するツイートを見つける
Tweets テーブルでは、ツイートをレコードとして取得できます。SearchTerms という疑似カラムを使用して、特定の文字列を含むツイートを取得します。すべてのツイートが検索対象となるため、(Twitter API のレート制限に達しないように)対象の文字列を含むツイートのみを抽出することが重要です。
SELECT From_User_ID, From_User_Name, Text FROM Tweets WHERE SearchTerms = 'JDBC'
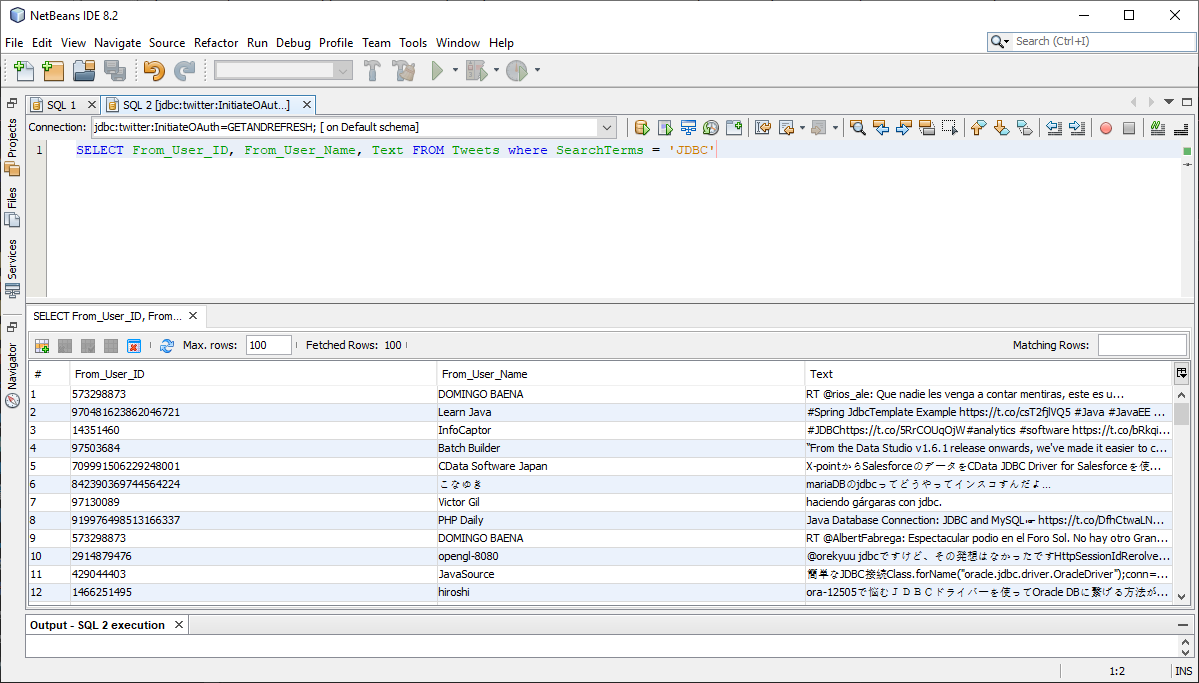
クエリがレート制限を超えてしまう場合は、SQL ステートメントに LIMIT 10000 を追加して結果の数を減らしてください。
SQL クエリを組み合わせる
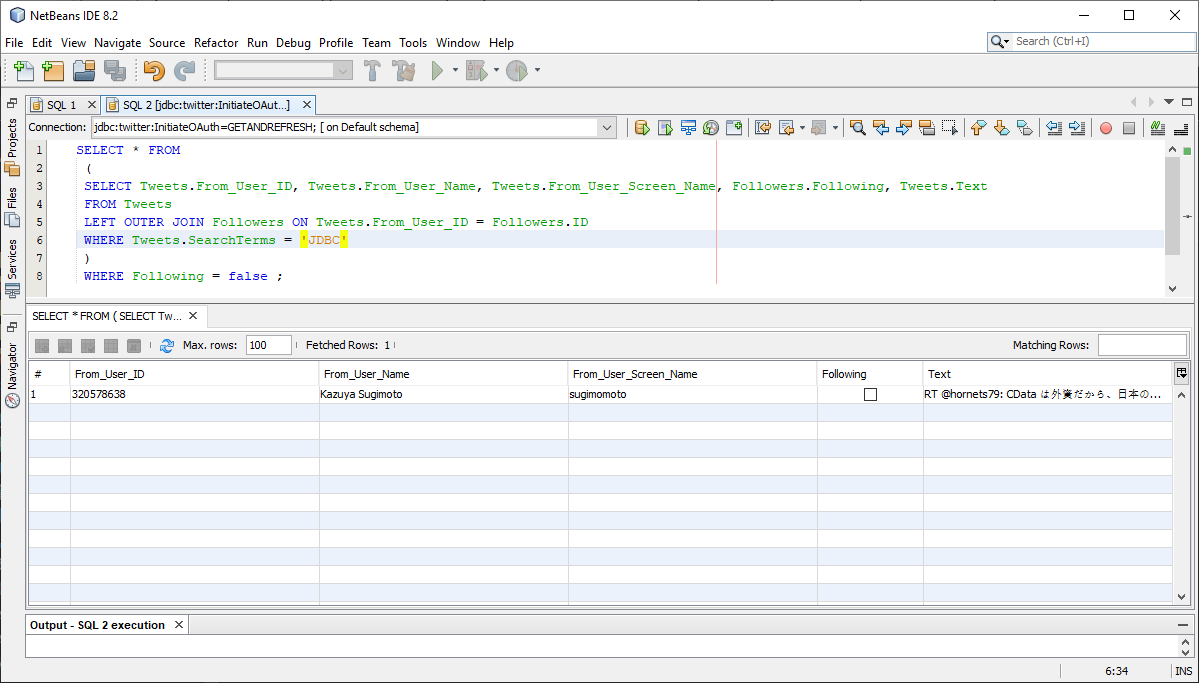
質問の各パーツを解析したら、それらを1つのクエリに組み合わせることができます。以下では、サブセレクトクエリを使用して、フォロワーからの「JDBC」という文字列を含むすべてのツイートを検索します。その結果から、自分のアカウントをフォローしていないアカウントを選択します。
SELECT * FROM
(
SELECT
Tweets.From_User_ID,
Tweets.From_User_Name,
Tweets.From_User_Screen_Name,
Followers.Following,
Tweets.Text
FROM
Tweets
LEFT OUTER JOIN
Followers
ON
Tweets.From_User_ID = Followers.ID
WHERE Tweets.SearchTerms = 'JDBC'
)
WHERE Following = false;
追加の制限事項
前述のとおり、Tweets テーブルの SearchTerms は、多くのツイートから特定の文字列のみを抽出できるため便利です。Text カラム(ツイートの本文)に LIKE 条件を指定すると、API がタイムライン全体をクエリするため、すぐに API レート制限に達してしまいます。Hashtags カラムについても同様です。回避策として、クエリに LIMIT を記述し、さらに Text や Hashtags カラムでフィルタリングしてください。
SearchTerms 疑似カラムの制限として、最新のツイートのみ取得できます。これは Twitter API の制限です。デフォルトでは、Twitter は過去7日間の検索からのツイートのみを返すことをサポートしています。ただし、プレミアムアカウントを持つユーザーは、30日間検索またはフルアーカイブ検索を実行して、より古いツイートを取得できます。
結果を制限するには、イベント固有のハッシュタグやフレーズなど、短期間に関連するコンテンツを検索してください。そうでない場合は、7日ごとに Twitter にクエリを実行するプログラムを設定して、完全な結果を取得してください。
注意: SearchTerms は User_Id などのカラムと組み合わせてクエリすることはできません。この制限を回避するには、OUTER JOIN を使用して結果セットを結合してください。
さらなるクエリ
フォロワー ID に基づいて重複のない結果を取得したい場合は、次のクエリを使用できます:
SELECT * FROM
(
SELECT
Tweets.From_User_ID,
Tweets.From_User_Name,
Tweets.From_User_Screen_Name,
Followers.Following
FROM
Tweets
LEFT OUTER JOIN
Followers
ON
Tweets.From_User_ID = Followers.ID
WHERE
Tweets.SearchTerms = 'JDBC'
GROUP BY
Tweets.From_User_ID
)
WHERE Following = false ;
まとめ
CData JDBC Driver for Twitter を使用すると、SQL で Twitter データを操作できます。30日間の無料トライアルをダウンロードして、今すぐ Twitter データの活用を始めましょう。150以上の SaaS、ビッグデータ、NoSQL データソースに SQL でアクセスする方法については、CData JDBC Drivers をご覧ください。