




増大するデータ断片化の問題
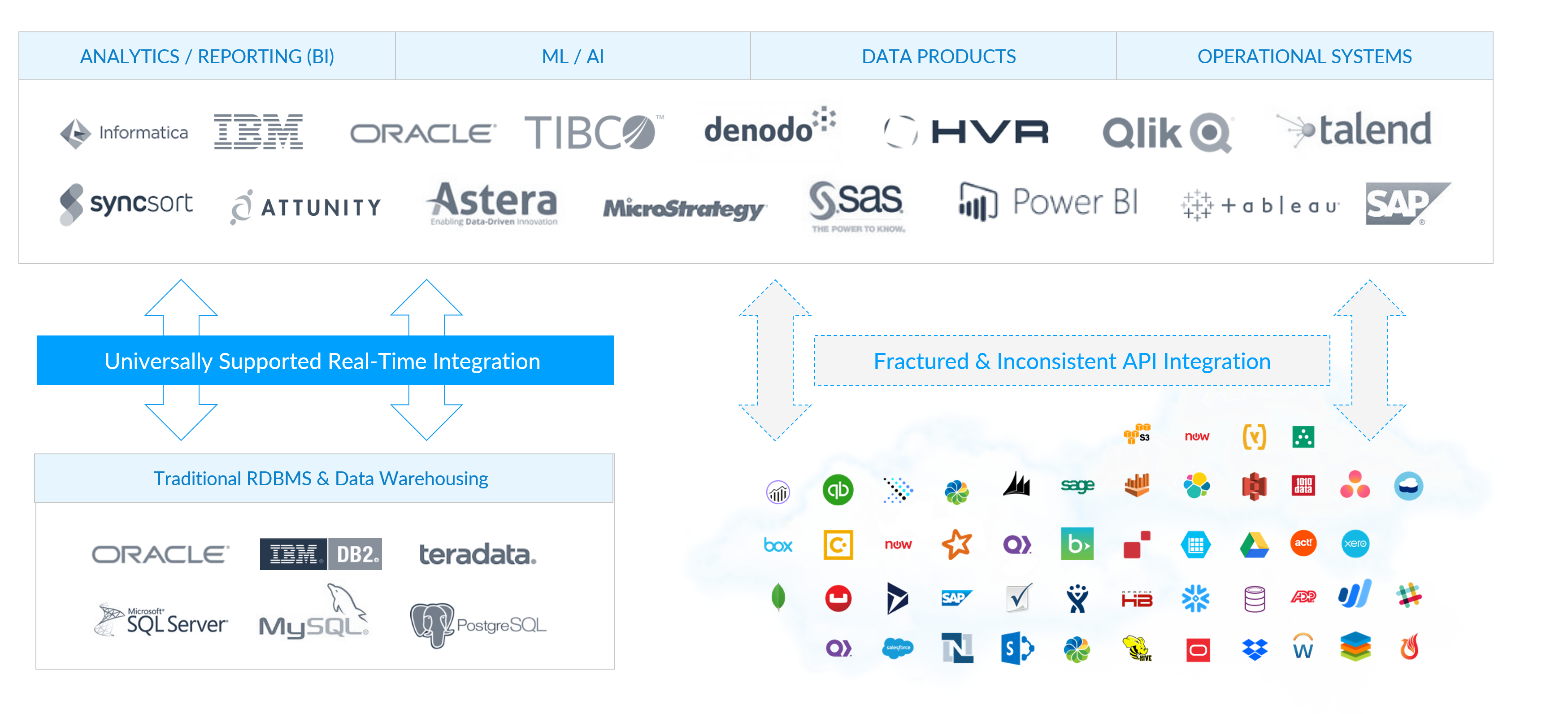
歴史的に、BI およびデータ連携ツールは、連携・接続するデータソースがわずかしかありませんでした。SaaS およびクラウドテクノロジーにより、市場の状況は大きく変わりました。データは複数のクラウド、アプリ、データベース、レガシープラットフォームにロックされ、データサイロが作成されています。
これらの環境でデータを移動することは遅いプロセスであり、ビジネスアナリティクスにとって課題となります。データはレプリケートされ連携される間に変更されることがあり、不正確な分析につながります。
データ仮想化のアプローチ
大量のサイロ化されたデータから価値を引き出すことは困難な作業ですが、データ仮想化はその問題を解決します。データ仮想化は、オンプレミスまたはクラウドの異なるデータソースから、さまざまなビジネスユースケースやワークロードをサポートするための一貫したセルフサービスデータサービスにリアルタイムまたはニアリアルタイムでデータをオーケストレーションする機能です。
データ仮想化の最も一般的なアプローチは、データ接続のための論理データウェアハウスレイヤーとして機能するスタンドアロンサーバーをデプロイすることです。組み込みデータ仮想化は、スタンドアロン DV と同じ特性の多くを共有しています。ただし、1つの外部プラットフォームではなく、共通データアクセスレイヤーでシステムが拡張されます。

スタンドアロンデータ仮想化ソリューションは、論理データウェアハウジングの一般的なアプローチです。ただし、これらのシステムの多くは大規模で、コストがかかり、メンテナンスが困難です。さらに、この規模のプロジェクトは通常、IT 組織全体の承認が必要です。
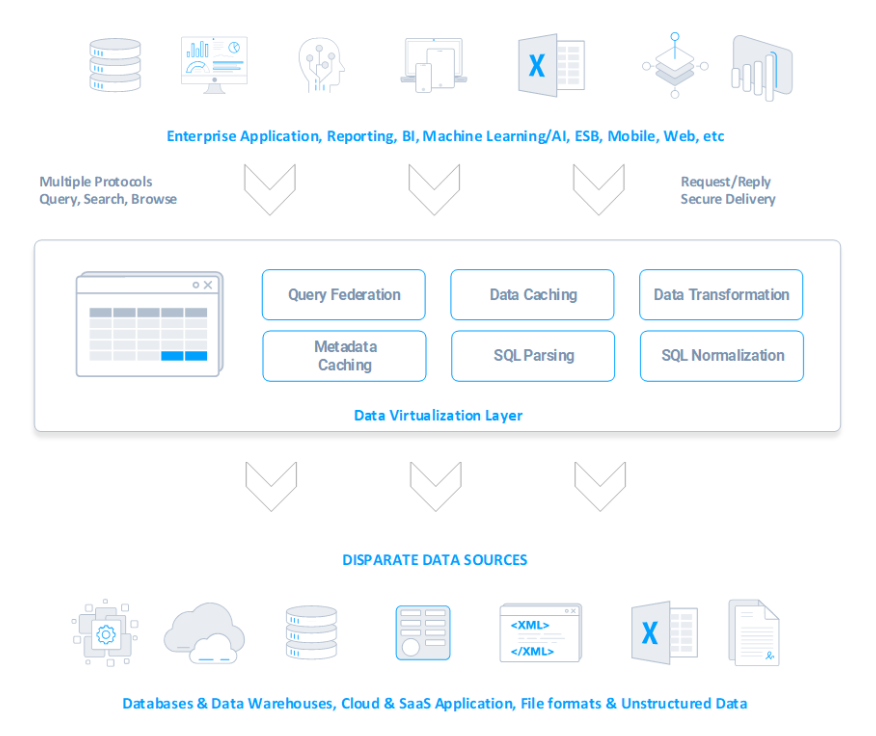
スタンドアロンデータ仮想化ソリューションとは異なり、組み込み DV は他のアプリケーションの戦術的コンポーネントとしてデプロイできます。アナリティクスまたは連携ソリューションは、拡張性のためのインターフェースとして組み込み DV を活用し、アプリケーションにとって最も重要な機能を選択できます。
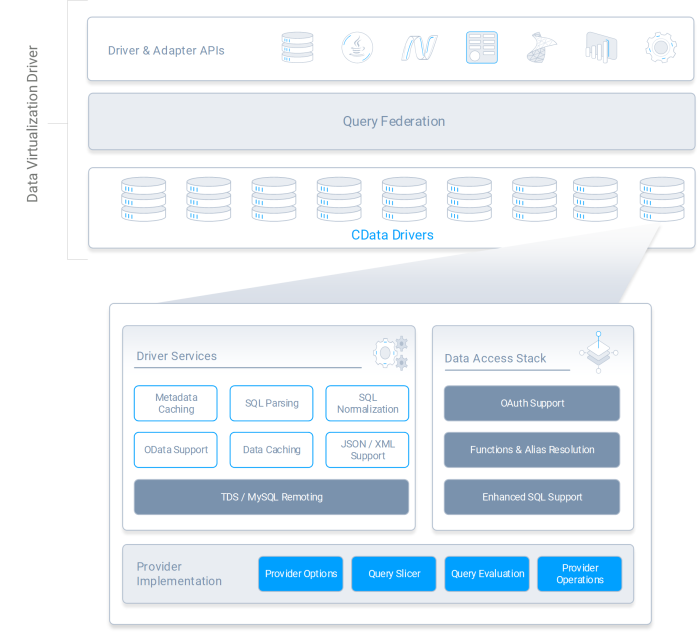
CData Drivers は組み込み DV のコンポーネントの一部を提供し、異なるデータ上に共通の SQL インターフェースを提供します。ソース間でデータを結合する場合は、CData Connect AI を活用できます。
組み込みデータ仮想化のメリット
- アプリケーション開発の簡素化 - 開発者は複数のデータ処理システムを選択し、単一の SQL ベースのインターフェースですべてにアクセスできます。
- 複数システム間でのクエリ - クエリフェデレーションを使用すると、異なるソースからのデータをオンデマンドで直接結合するクエリを記述できます。
- 最大85%高速化 - 従来のデータウェアハウジングや ETL と比較して、より高速で簡単なデータ接続。

組み込み DV の実践
Query Federation Driver の概要動画をご覧いただき、アプリケーションが共通インターフェースを通じてデータ接続をどのように簡素化・一元化できるかをご確認ください。

データ仮想化のためのコネクティビティ
CData ドライバーテクノロジーと一般的なツールを組み合わせて、仮想化データ接続を強化します。
主要なデータ連携・仮想化ソリューションへの組み込みに加え、CData ドライバーテクノロジーは一般的なツールと簡単に組み合わせることができます。ODBC、JDBC、ADO、Python をユニバーサルにサポートし、フェデレーションクエリ、SQL Server リンクサーバー、PolyBase、その他の主要な DV テクノロジーで動作します。