





AWS Lambda でリアルタイムCSV のデータにアクセス(IntelliJ IDEA を使用)

AWS Lambda は、新しい情報やイベントに素早く応答するアプリケーションを構築できるコンピューティングサービスです。CData JDBC Driver for CSV と組み合わせることで、AWS Lambda 関数からリアルタイムCSV のデータを操作できます。この記事では、IntelliJ で Maven を使用して AWS Lambda 関数を構築し、CSV のデータに接続してクエリを実行する方法を説明します。
最適化されたデータ処理機能を組み込んだ CData JDBC ドライバは、リアルタイムCSV のデータとのインタラクションにおいて卓越したパフォーマンスを発揮します。CSV に対して複雑な SQL クエリを発行すると、ドライバーはフィルタや集計などのサポートされている SQL 操作を直接CSVにプッシュし、サポートされていない操作(主に SQL 関数や JOIN 操作)は組み込みの SQL エンジンを使用してクライアント側で処理します。さらに、動的メタデータクエリ機能により、ネイティブのデータ型を使用してCSV のデータの操作・分析が可能です。
ステップ1:接続プロパティの設定と接続文字列の構築
CData JDBC Driver for CSV のインストーラーをダウンロードし、パッケージを解凍して JAR ファイルを実行してドライバーをインストールします。次に、必要な接続プロパティを収集します。
CSV 接続プロパティの取得・設定方法
DataSource プロパティにローカルフォルダ名を設定します。
.csv、.tab、.txt ではない拡張子のファイルを扱う場合には、IncludeFiles 使用する拡張子をカンマ区切りで設定します。Microsoft Jet OLE DB 4.0 driver 準拠の場合にはExtended Properties を設定することができます。別の方法として、Schema.ini ファイルにファイル形式を記述することも可能です。
CSV ファイルの削除や更新を行う場合には、UseRowNumbers をTRUE に設定します。RowNumber はテーブルKey として扱われます。
Amazon S3 内のCSV への接続
URI をバケットおよびフォルダに設定します。さらに、次のプロパティを設定して認証します。
- AWSAccessKey:AWS アクセスキー(username)に設定。
- AWSSecretKey:AWS シークレットキーに設定。
Box 内のCSV への接続
URI をCSV ファイルを含むフォルダへのパスに設定します。Box へ認証するには、OAuth 認証標準を使います。 認証方法については、Box への接続 を参照してください。
Dropbox 内のCSV への接続
URI をCSV ファイルを含むフォルダへのパスに設定します。Dropbox へ認証するには、OAuth 認証標準を使います。 認証方法については、Dropbox への接続 を参照してください。ユーザーアカウントまたはサービスアカウントで認証できます。ユーザーアカウントフローでは、以下の接続文字列で示すように、ユーザー資格情報の接続プロパティを設定する必要はありません。
SharePoint Online SOAP 内のCSV への接続
URI をCSV ファイルを含むドキュメントライブラリに設定します。認証するには、User、Password、およびStorageBaseURL を設定します。
SharePoint Online REST 内のCSV への接続
URI をCSV ファイルを含むドキュメントライブラリに設定します。StorageBaseURL は任意です。指定しない場合、ドライバーはルートドライブで動作します。 認証するには、OAuth 認証標準を使用します。
FTP 内のCSV への接続
URI をルートフォルダとして使用されるフォルダへのパスが付いたサーバーのアドレスに設定します。認証するには、User およびPassword を設定します。
Google Drive 内のCSV への接続
デスクトップアプリケーションからのGoogle への認証には、InitiateOAuth をGETANDREFRESH に設定して、接続してください。詳細はドキュメントの「Google Drive への接続」を参照してください。
NOTE: AWS Lambda 関数で JDBC ドライバーを使用するには、ライセンス(製品版または試用版)とランタイムキー(RTK)が必要です。ライセンス(または試用版)の取得については、弊社営業チームまでお問い合わせください。
組み込みの接続文字列デザイナー
JDBC URL の構築には、CSV JDBC Driver に組み込まれている接続文字列デザイナーを使用できます。JAR ファイルをダブルクリックするか、コマンドラインから JAR ファイルを実行してください。
java -jar cdata.jdbc.csv.jar
")
接続プロパティ(RTK を含む)を入力し、接続文字列をクリップボードにコピーします。
ステップ2:IntelliJ でプロジェクトを作成
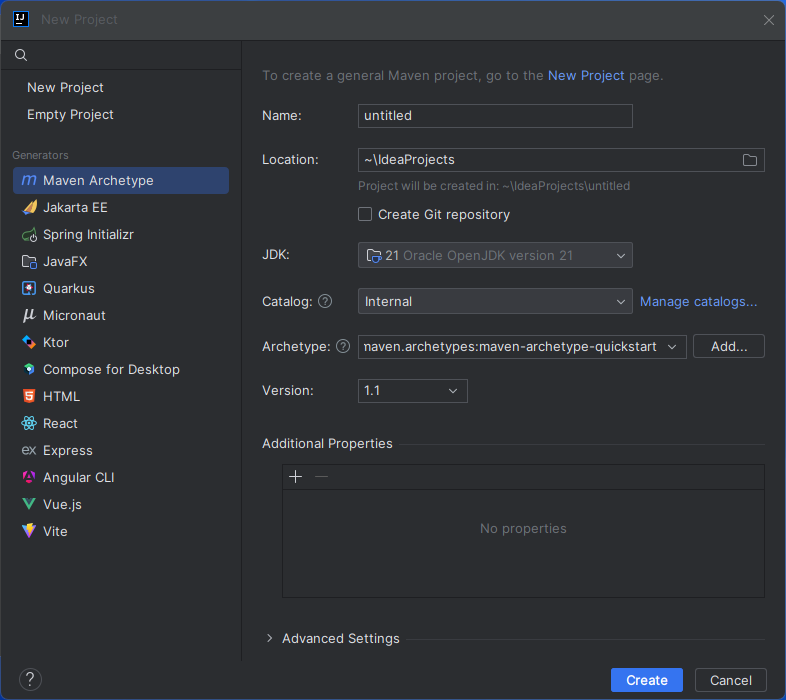
- IntelliJ IDEA で「New Project」をクリックします。
- Generators から「Maven Archetype」を選択します。
- プロジェクトに名前を付け、Archetype として「maven.archetypes:maven-archetype-quickstart」を選択します。
- 「Create」をクリックします。
CData JDBC Driver for CSV JAR ファイルのインストール
プロジェクトのルートフォルダから以下の Maven コマンドを実行して、JAR ファイルをプロジェクトにインストールします。
mvn install:install-file -Dfile="PATH/TO/CData JDBC Driver for CSV 20XX/lib/cdata.jdbc.csv.jar" -DgroupId="org.cdata.connectors" -DartifactId="cdata-csv-connector" -Dversion="23" -Dpackaging=jar
依存関係の追加
Maven プロジェクトの pom.xml ファイル内で、AWS とCData JDBC Driver for CSVを依存関係として追加します(<dependencies> 要素内に以下の XML を追加)。
- AWS
<dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-lambda-java-core</artifactId> <version>1.2.2</version> <!--Replace with the actual version--> </dependency>
- CData JDBC Driver for CSV
<dependency> <groupId>org.cdata.connectors</groupId> <artifactId>cdata-csv-connector</artifactId> <version>25</version> <!--Replace with the actual version--> </dependency>
- Fat JAR 作成用の Maven Shade Plugin
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.4.1</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <createDependencyReducedPom>false</createDependencyReducedPom> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>com.example.CDataLambda</mainClass> <!-- Change to your actual Lambda handler class --> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> </build>
AWS Lambda 関数の作成
このサンプルプロジェクトでは、CDataLambda.java と CDataLambdaTest.java の2つのソースファイルを作成します。
Lambda 関数の定義
- CDataLambda クラスを AWS Lambda SDK の RequestHandler インターフェースを実装するように更新します。handleRequest メソッドを追加する必要があります。このメソッドは、Lambda 関数がトリガーされたときに以下のタスクを実行します:
- 入力を使用して SQL クエリを構築
- CData JDBC Driver for CSV を登録
- JDBC を使用してCSVへの接続を確立
- CSV で SQL クエリを実行
- 結果をコンソールに出力
- 出力メッセージを返す
-
以下の完全な Lambda クラスを使用してください。インポート、クラス定義、handleRequest メソッドが含まれています。DriverManager.getConnection 呼び出し内の接続文字列値は、実際の値に置き換えてください。
package com.example; import com.amazonaws.services.lambda.runtime.Context; import com.amazonaws.services.lambda.runtime.RequestHandler; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.ResultSetMetaData; import java.sql.SQLException; import java.sql.Statement; public class CDataLambda implements RequestHandler < Object, String > { @Override public String handleRequest(Object input, Context context) { String query = "SELECT * FROM " + input; String bucketName = "MY_AWS_BUCKET"; try { Class.forName("cdata.jdbc.csv.CSVDriver"); cdata.jdbc.csv.CSVDriver driver = new cdata.jdbc.csv.CSVDriver(); DriverManager.registerDriver(driver); } catch (SQLException ex) { // Registering the driver failed throw new RuntimeException("Failed to register JDBC driver", ex); } catch (ClassNotFoundException e) { // The driver class was not found in the classpath throw new RuntimeException("JDBC Driver class not found", e); } Connection connection = null; try { connection = DriverManager.getConnection("jdbc:cdata:csv:RTK=52465...;DataSource=MyCSVFilesFolder;"); } catch (SQLException ex) { context.getLogger().log("Error getting connection: " + ex.getMessage()); } catch (Exception ex) { context.getLogger().log("Error: " + ex.getMessage()); } if (connection != null) { context.getLogger().log("Connected Successfully! "); } ResultSet resultSet = null; try { //executing query Statement stmt = connection.createStatement(); resultSet = stmt.executeQuery(query); ResultSetMetaData metaData = resultSet.getMetaData(); int numCols = metaData.getColumnCount(); //printing the results while (resultSet.next()) { for (int i = 1; i <= numCols; i++) { System.out.printf("%-25s", (resultSet.getObject(i) != null) ? resultSet.getObject(i).toString().replaceAll(" ", "") : null); } System.out.print(" "); } } catch (SQLException ex) { System.out.println("SQL Exception: " + ex.getMessage()); } catch (Exception ex) { System.out.println("General exception: " + ex.getMessage()); } return "v24 query: " + query + " complete"; } }
ステップ3:Lambda 関数のデプロイと実行
IntelliJ で関数をビルドしたら、Maven プロジェクト全体を単一の JAR ファイルとしてデプロイする準備が整います。
- IntelliJ で mvn install コマンドを使用して SNAPSHOT JAR ファイルをビルドします。
Note: Maven Shade Plugin は target フォルダに2つの JAR を生成します。AWS Lambda には常に、すべての必要な依存関係を含むサイズの大きい -shaded.jar ファイルをアップロードしてください。
- AWS Lambda で新しい関数を作成します(または既存の関数を開きます)。
- 関数に名前を付け、IAM ロールを選択し、タイムアウト値を関数が完了するのに十分な値に設定します(クエリの結果サイズによって異なります)。
- 「Upload from」->「.zip file」をクリックし、SNAPSHOT JAR ファイルを選択します。

- 「Runtime settings」セクションで「Edit」をクリックし、Handler を handleRequest メソッドに設定します(例:package.class::handleRequest)。

- これで関数をテストできます。「Event JSON」フィールドにテーブル名を設定し、「Test」をクリックします。

無償トライアル・詳細情報
CData JDBC Driver for CSV の30日間の無償トライアルをダウンロードして、AWS Lambda でリアルタイムCSV のデータを活用してみてください。ご不明な点があれば、サポートチームまでお気軽にお問い合わせください。
はじめる準備はできましたか?
CSV Driver の無料トライアルをダウンロードしてお試しください:
ダウンロード