





CData Connect AI 経由でMicroStrategy からSpark のデータにリアルタイム連携

MicroStrategy は、データドリブンイノベーションを可能にする分析およびモバイルプラットフォームです。MicroStrategy とCData Connect AI を組み合わせると、MicroStrategy からデータベースと同じ感覚でリアルタイムSpark のデータにアクセスできるようになり、レポート機能と分析機能が拡張されます。この記事では、Connect AI でSpark に接続し、MicroStrategy でConnect AI に接続してSpark のデータの簡単なビジュアライゼーションを作成する方法について説明します。
クラウドベースの統合プラットフォームであるConnect AI は、クラウドベースのBI ツールや分析ツールの使用に理想的です。構成するサーバーやセットアップするデータプロキシがないため、Web ベースのUI を使用してSpark へのリアルタイム接続を作成し、MicroStrategy から接続してSpark のデータに基づくリアルタイムでの分析を開始できます。
Connect AI からSpark に接続する
CData Connect AI は直感的なクリック操作ベースのインターフェースを使ってデータソースに接続します。- Connect AI にログインし、 Add Connection をクリックします。
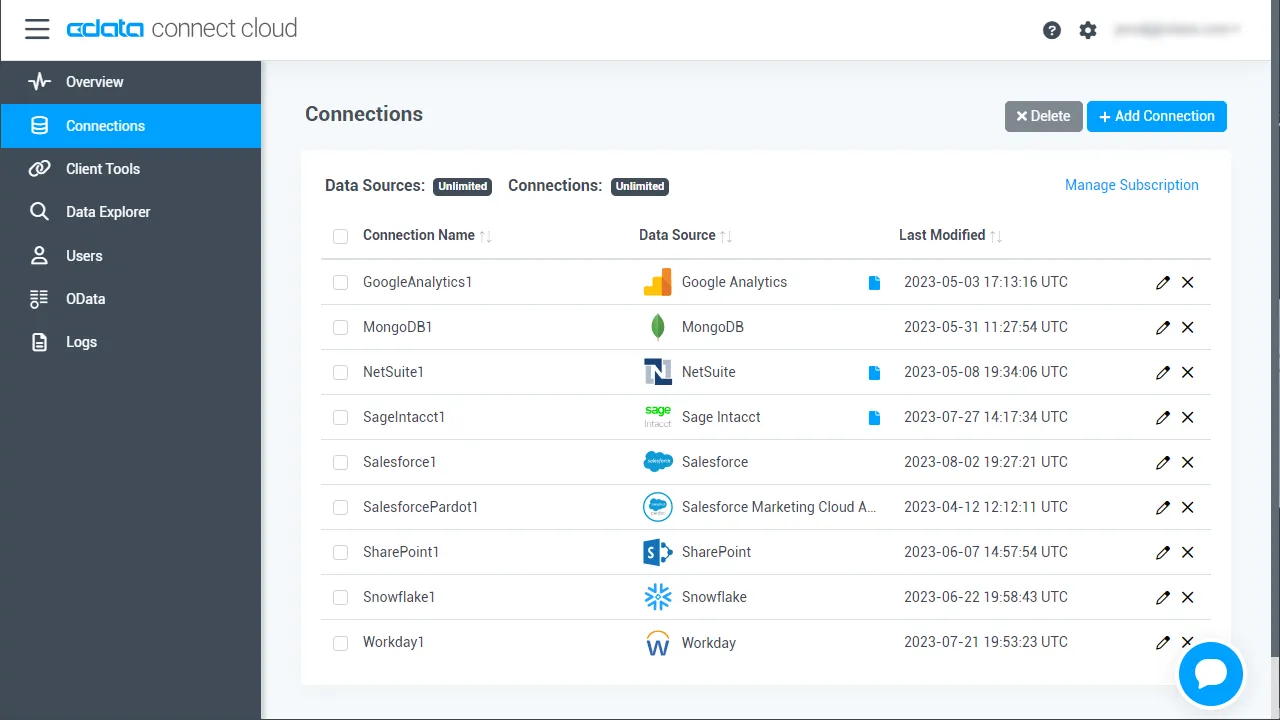
- Add Connection パネルから「Spark」を選択します。
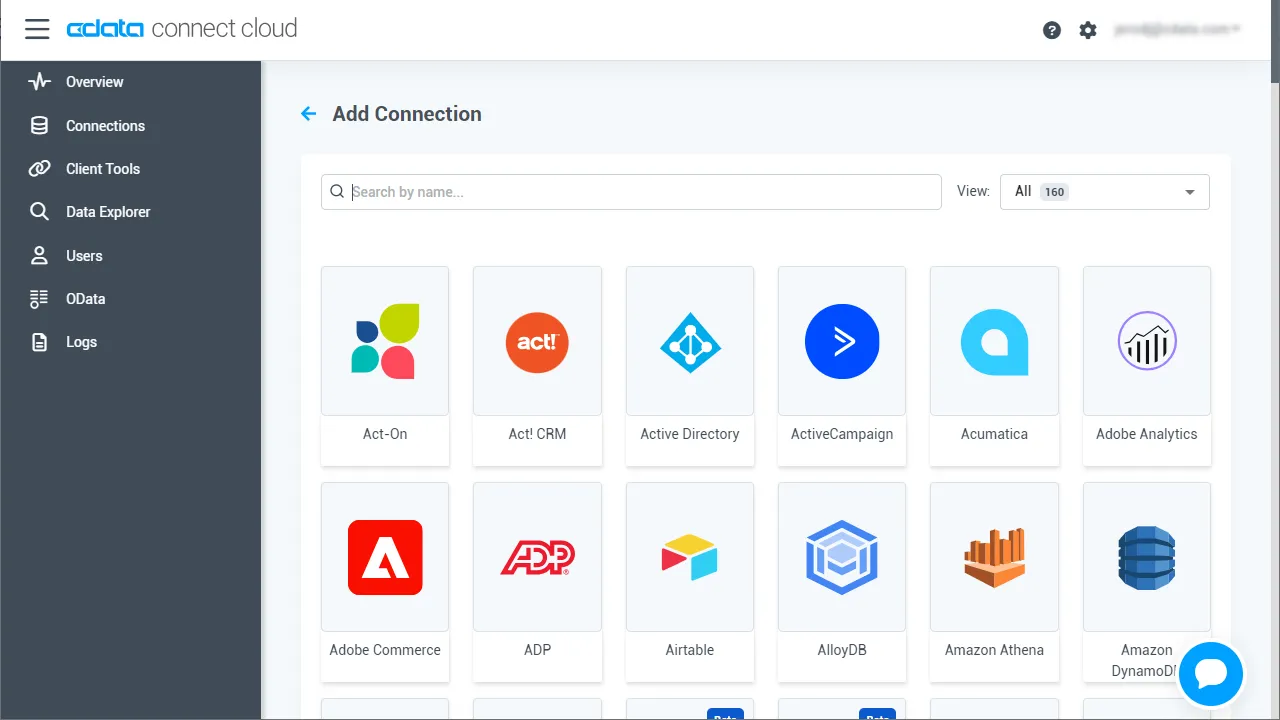
-
必要な認証情報を入力し、Spark に接続します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
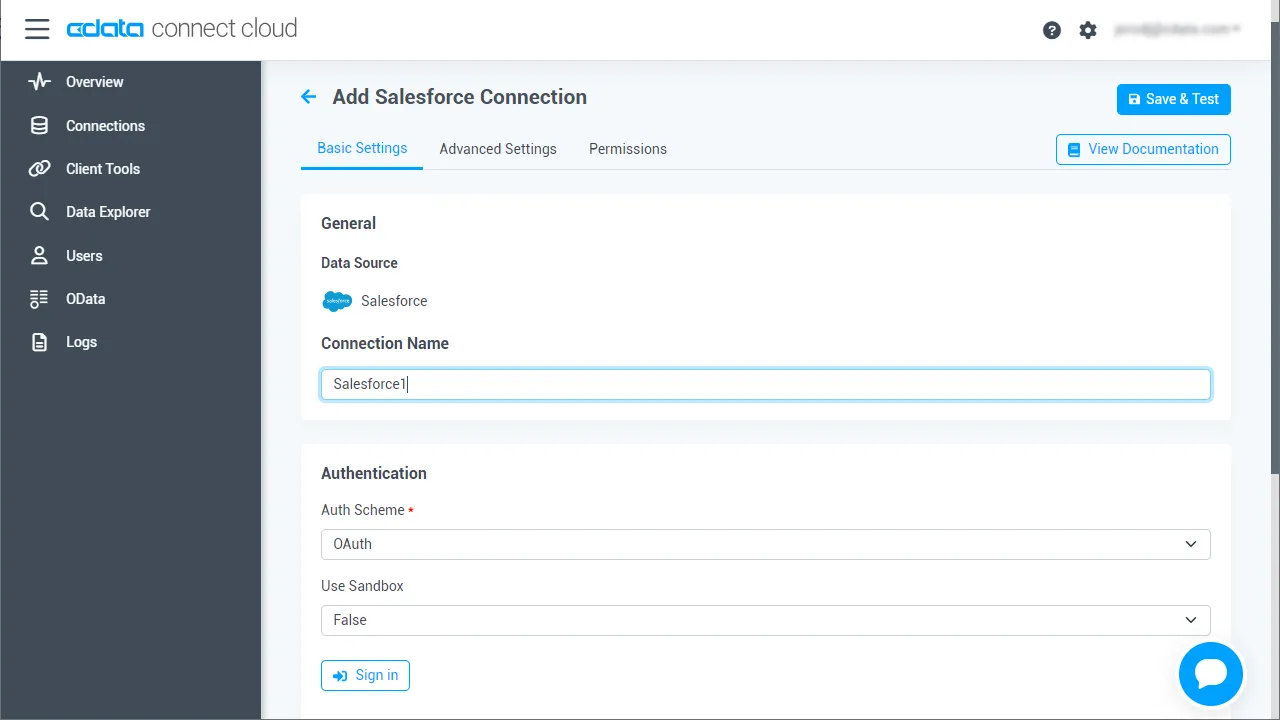
- Create & Test をクリックします。
- Add Spark Connection ページのPermissions タブに移動し、ユーザーベースのアクセス許可を更新します。
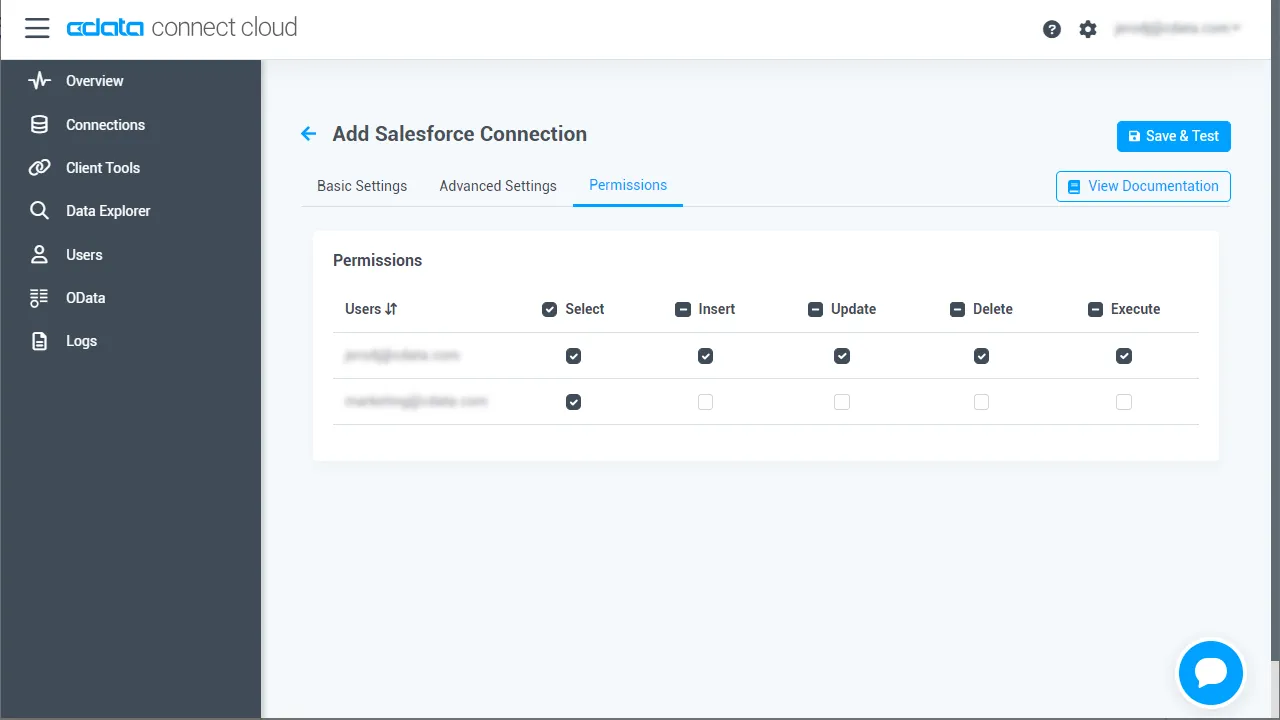
パーソナルアクセストークンを追加する
OAuth 認証をサポートしないサービス、アプリケーション、プラットフォーム、フレームワークから接続する場合、パーソナルアクセストークン(Personal Access Token, PAT)を認証に使用できます。きめ細かくアクセスを管理するために、サービスごとに個別のPAT を作成するのがベストプラクティスです。
- Connect AI アプリの右上にあるユーザー名をクリックし、User Profile をクリックします。
- User Profile ページで、Personal Access Tokens セクションまでスクロールし、Create PAT をクリックします。
- PAT に名前を付け、Create をクリックします。
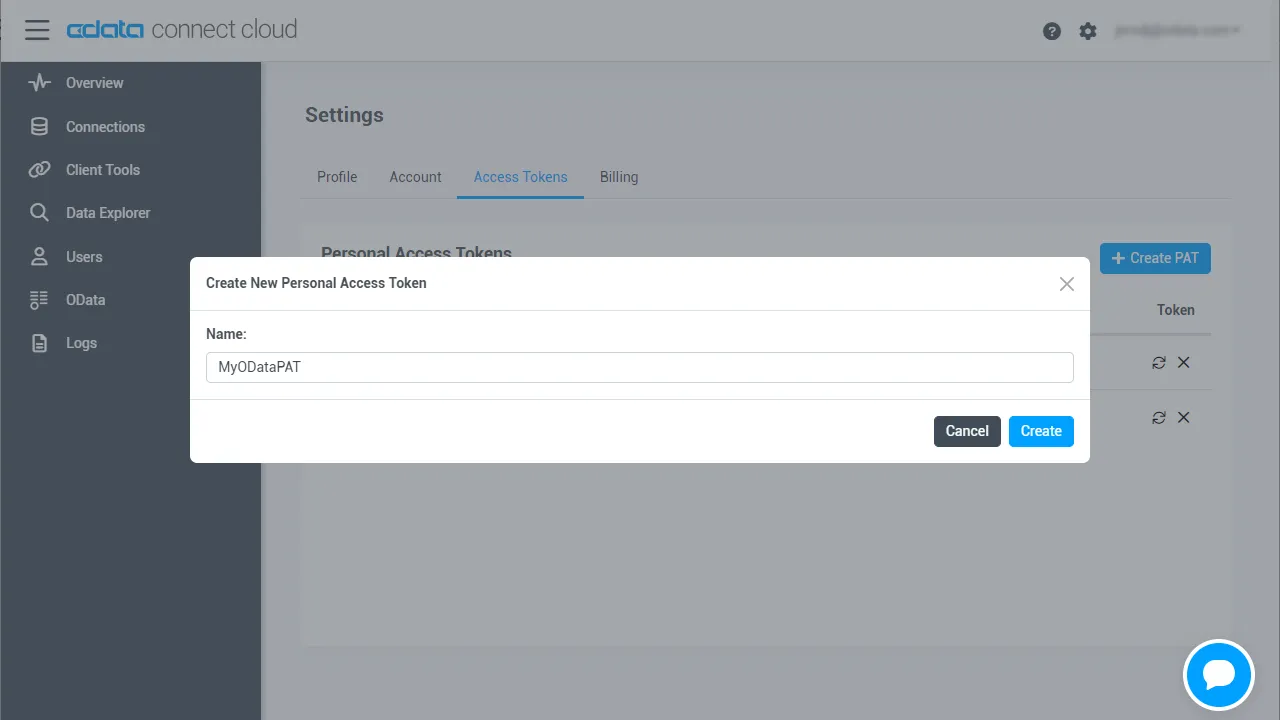
- パーソナルアクセストークンは作成時にしか表示されないため、必ずコピーして安全に保存してください。
接続が構成されたら、MicroStrategy からSpark のデータに接続できるようになります。
MicroStrategy を使用してSpark のデータに接続し、ビジュアライズする
ネイティブSQL Server 機能を使ってデータソースを追加することにより、MicroStrategy からSpark に接続できます。データソースを作成したら、MicroStrategy でSpark のデータの動的なビジュアライゼーションを構築できます。
- MicroStrategy を開き、アカウントを選択します。
- [Add External Data]をクリックし、[Databases]を選択して[Import Option]として[Select Tables]を使用します。

- Import from Tables ウィザードでクリックして新しいデータソースを追加します。
- Database メニューで「SQL Server」を選択し、Version メニューで「SQL Server 2017」を選択します。
- 接続プロパティを以下のように設定します。
- Server Name:tds.cdata.com
- Port Number:14333
- Database Name:Spark コネクションの名前(例: SparkSQL1)
- User:Connect AI ユーザー
- Password:Connect AI ユーザーのPAT
- Data Source Name:「CData Cloud Spark」のような新しい外部データソースの名前
- 新しいデータソースのメニューを展開し、「Edit Catalog Options」を選択します。
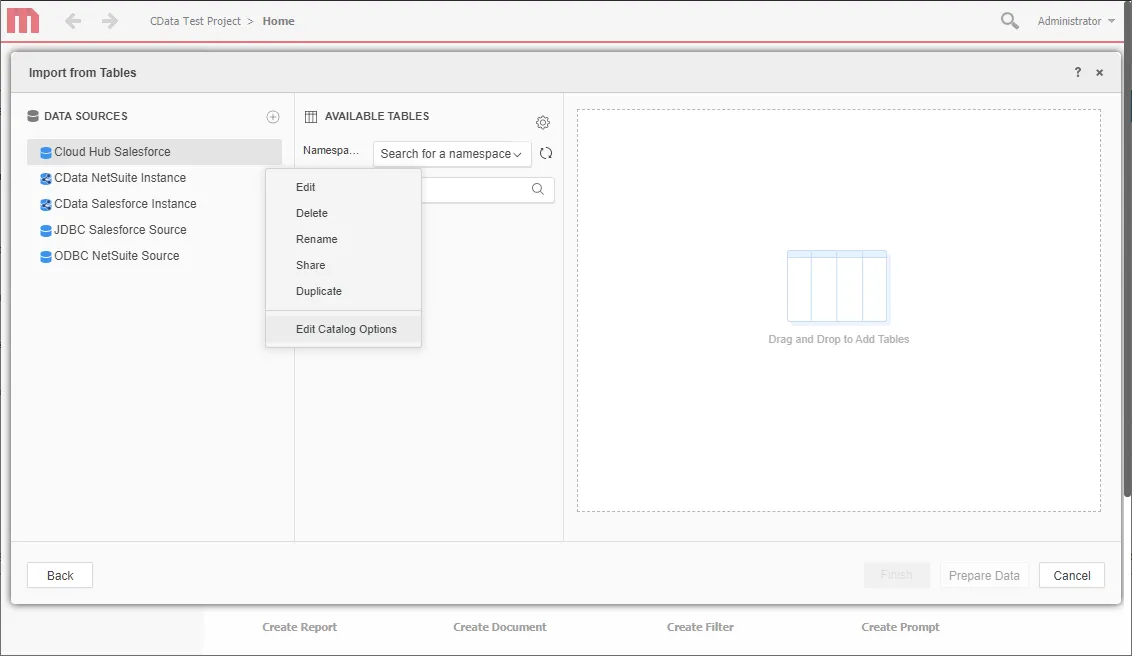
- 「SQL statement retreive columns ...」クエリを編集してWHERE 句にTABLE_SCHEMA = '#?Schema_Name?#' を含め、Apply -> OK の順にクリックします。(以下は完全なクエリです)
SELECT DISTINCT TABLE_SCHEMA NAME_SPACE, TABLE_NAME TAB_NAME, COLUMN_NAME COL_NAME, (CASE WHEN (DATA_TYPE LIKE '%char' AND (CHARACTER_SET_NAME='utf8' OR CHARACTER_SET_NAME='usc2')) THEN CONCAT('a',DATA_TYPE) ELSE DATA_TYPE END) DATA_TYPE, CHARACTER_MAXIMUM_LENGTH DATA_LEN, NUMERIC_PRECISION DATA_PREC, NUMERIC_SCALE DATA_SCALE FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME IN (#TABLE_LIST#) AND TABLE_SCHEMA='#?Schema_Name?#' ORDER BY 1,2,3 - 新しいデータソースを選択し、仮想Spark のデータベースに対応するNamespace を選択します。(SparkSQL1 など)
- テーブルをペインにドラッグして追加します。
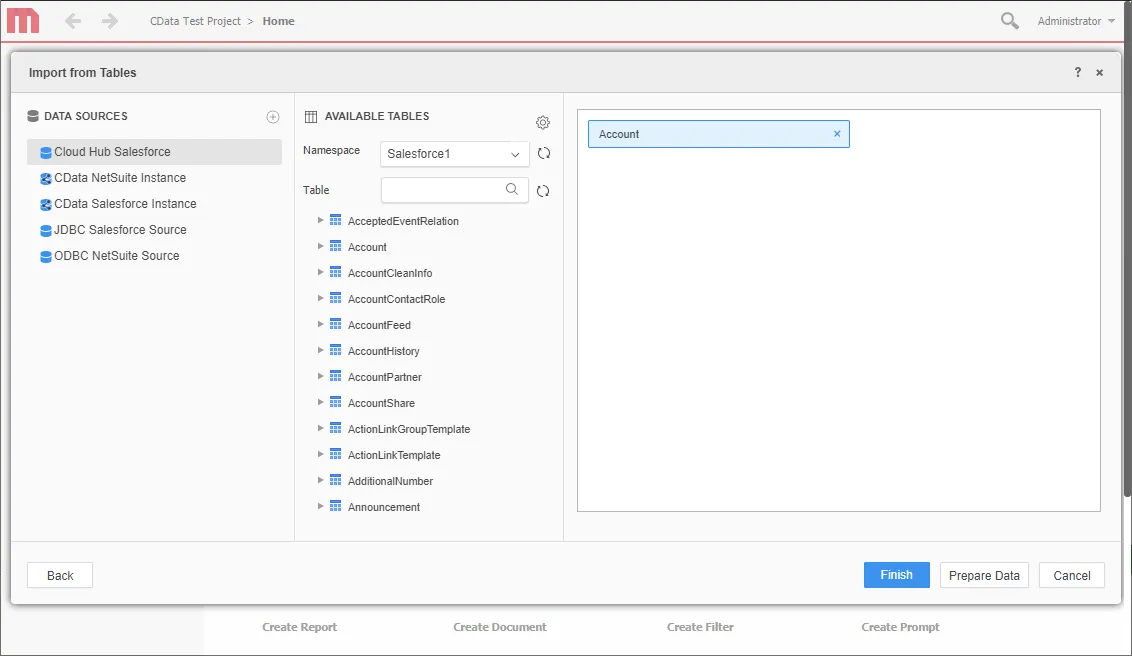 Note:リアルタイム接続を作成するため、テーブル全体を追加し、MicroStrategy 製品に固有のフィルタリングおよび集計機能を利用してデータセットをカスタマイズできます。
Note:リアルタイム接続を作成するため、テーブル全体を追加し、MicroStrategy 製品に固有のフィルタリングおよび集計機能を利用してデータセットをカスタマイズできます。 - [Finish]をクリックして、リアルタイム接続するオプションを選択してクエリを保存し、新しいドシエを作成するオプションを選択します。CData Connect AI の高性能データ処理によってリアルタイム接続が効果的に実現できます。
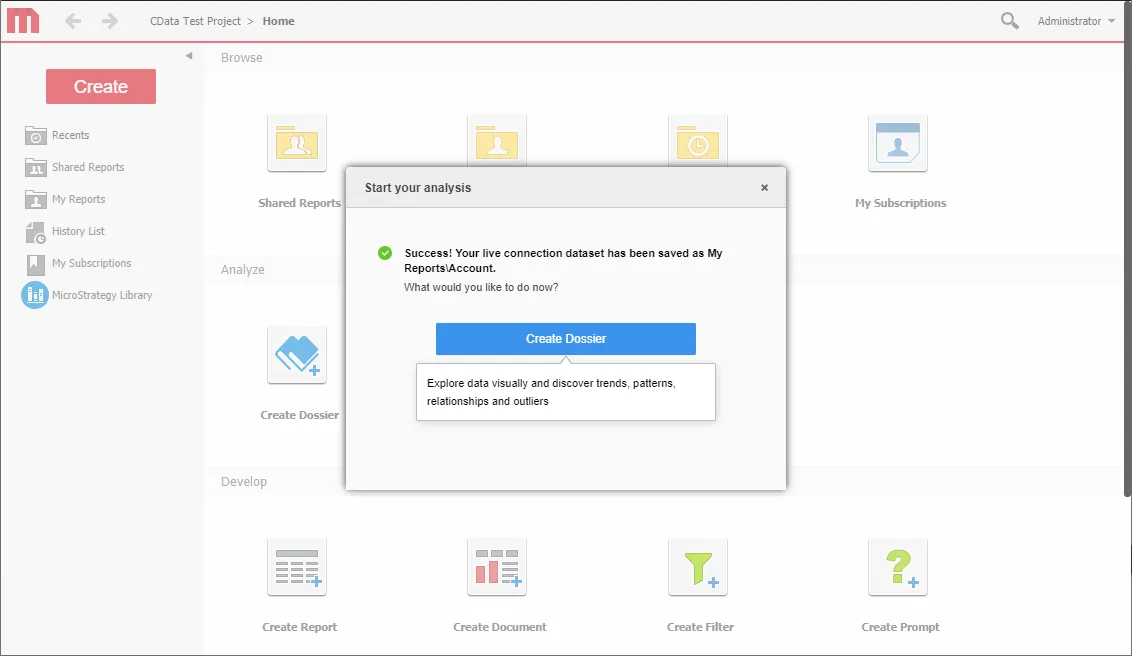
- ビジュアライゼーションを選択して表示するフィールドを選択し、フィルタを適用してSpark のデータの新しいビジュアライゼーションを作成します。データ型は、動的なメタデータ検出によって自動的に検出されます。可能であれば、フィルタと集計によって生成された複雑なクエリはSpark にプッシュダウンされ、サポートされていない操作(SQL 関数とJOIN 操作を含む)は、Connect AI に組み込まれたCData SQL エンジンによって管理されます。
- ドシエの設定が完了したら、File -> Save とクリックします。
MicroStrategy とともにCData Connect AI を使用することで、Spark のデータで強固なビジュアライゼーションとレポートを簡単に作成できます。Spark(および100を超えるほかのデータソース)に接続する方法の詳細については、Connect AI ページにアクセスしてください。無償トライアルにサインアップして、MicroStrategy でリアルタイムSpark のデータの操作をはじめましょう。