





Qlik Sense Cloud のSpark からアプリを作成

Qlik Sense Cloud を使用すると、データのビジュアライゼーションを作成および共有して、新しい方法で情報を操作できます。CData API Server は、Spark の仮想データベースを作成し、Spark のOData API(Qlik Sense Cloud でネイティブに使用可能)を生成するために使用できます。Qlik Sense Cloud をCData API Server とペアリングすることで、すべてのSaaS およびビッグデータとNoSQL ソースへの接続が可能になります。データを移行したり統合したりする必要はありません。ほかのREST サービスと同様に、Qlik Sense Cloud からAPI Server に接続するだけで、Spark のデータに瞬時にライブアクセスできます。
この記事では、二つの接続について説明します。
- API Server からSpark への接続。
- Qlik Sense Cloud からAPI Server に接続してモデルを作成し、シンプルなダッシュボードを構築。
API Server の設定
以下のリンクからAPI Server の無償トライアルをスタートしたら、セキュアなSpark OData サービスを作成していきましょう。
Spark への接続
Qlik Cloud からSpark のデータを操作するには、まずSpark への接続を作成・設定します。
- API Server にログインして、「Connections」をクリック、さらに「接続を追加」をクリックします。
- 「接続を追加」をクリックして、データソースがAPI Server に事前にインストールされている場合は、一覧から「Spark」を選択します。
- 事前にインストールされていない場合は、コネクタを追加していきます。コネクタ追加の手順は以下の記事にまとめてありますので、ご確認ください。
CData コネクタの追加方法はこちら >> - それでは、Spark への接続設定を行っていきましょう!
-
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
- 接続情報の入力が完了したら、「保存およびテスト」をクリックします。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
API Server のユーザー設定
次に、API Server 経由でSpark にアクセスするユーザーを作成します。「Users」ページでユーザーを追加・設定できます。やってみましょう。
- 「Users」ページで ユーザーを追加をクリックすると、「ユーザーを追加」ポップアップが開きます。
-
次に、「ロール」、「ユーザー名」、「権限」プロパティを設定し、「ユーザーを追加」をクリックします。

-
その後、ユーザーの認証トークンが生成されます。各ユーザーの認証トークンとその他の情報は「Users」ページで確認できます。

Spark 用のAPI エンドポイントの作成
ユーザーを作成したら、Spark のデータ用のAPI エンドポイントを作成していきます。
-
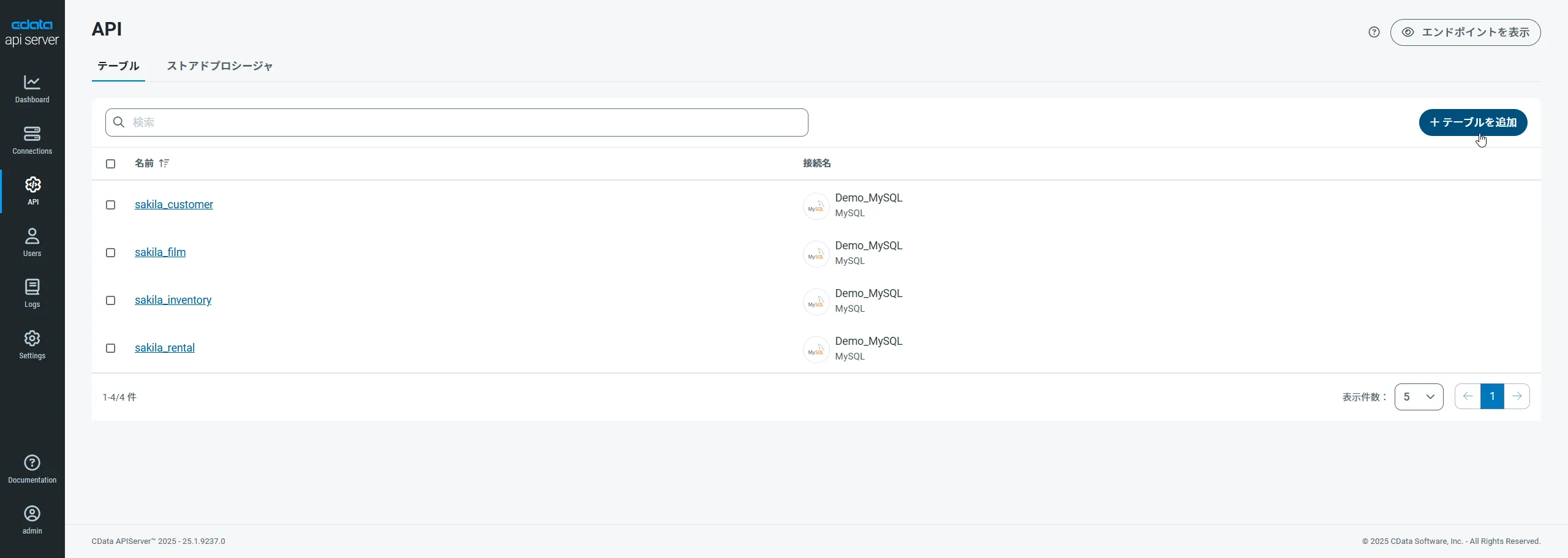
まず、「API」ページに移動し、
「 テーブルを追加」をクリックします。
-
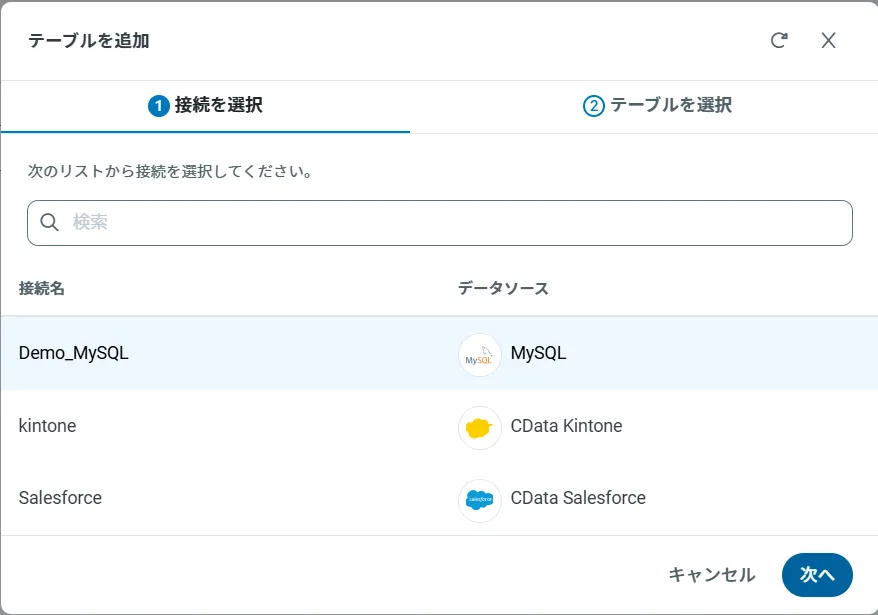
アクセスしたい接続を選択し、次へをクリックします。
-
接続を選択した状態で、各テーブルを選択して確認をクリックすることでエンドポイントを作成します。

OData のエンドポイントを取得
以上でSpark への接続を設定してユーザーを作成し、API Server でSpark データのAPI を追加しました。これで、OData 形式のSpark データをREST API で利用できます。API Server の「API」ページから、API のエンドポイントを表示およびコピーできます。

(オプション)Cross-Origin Resource Sharing (CORS) を構成
Ajax などのアプリケーションから複数のドメインにアクセスして接続すると、クロスサイトスクリプティングの制限に違反する恐れがあります。その場合には、[OData]->[Settings]でCORS 設定を構成します。
- Enable cross-origin resource sharing (CORS):ON
- Allow all domains without '*':ON
- Access-Control-Allow-Methods:GET, PUT, POST, OPTIONS
- Access-Control-Allow-Headers:Authorization
Spark のデータからQlik Sense アプリケーションを作成
Spark への接続と構成されたOData エンドポイントがあれば、Spark のデータを追加してQlik Sense でビジュアライズ、分析、レポートなどを行うことができます。
新しいアプリケーションの作成とデータのアップロード
- Qlik Sense インスタンスにログインし、ボタンをクリックして新しいアプリケーション新しいアプリケーションを作成します。
- 新しいアプリケーションに名前を付けて構成し、「Create」をクリックします。
- ワークスペース内で、新しいアプリケーションをクリックして開きます。
- クリックして、ファイルやその他のソースからデータを追加します。
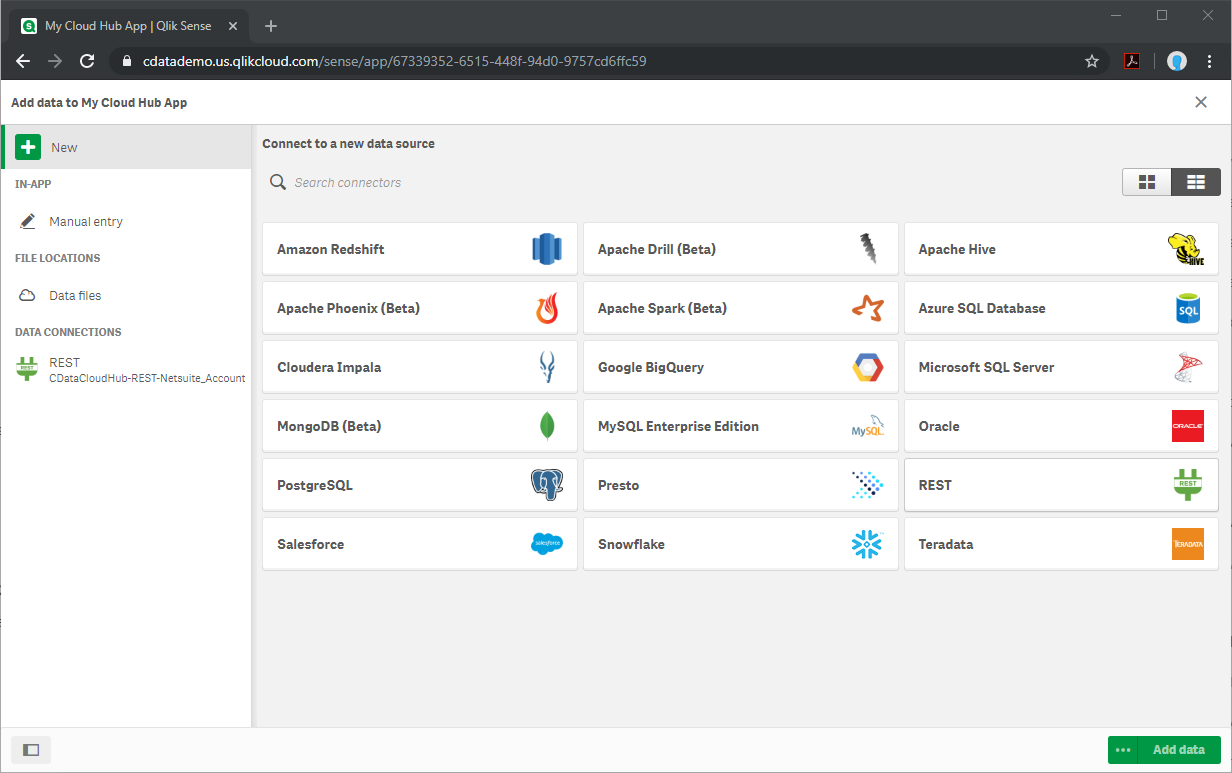
- REST コネクタを選択し、構成プロパティを設定します。次の箇所以外では、ほとんどの箇所でデフォルト値を使用します。
- URL:これをSpark テーブルのAPI エンドポイントに設定します。@CSV URL パラメーターを使用することで、CSV レスポンスを確実に取得できます。(例: https://myserver/api.rsc/SparkSQL_Customers?@CSV)
- Authentication Schema:「BASIC」に設定します。
- User Name:上記で構成したユーザー名に設定します。
- Password:上記のユーザー用の認証トークンに設定します。
- 「Create」をクリックしてSpark のデータのAPI Server をクエリします。
- 「CSV has header」をチェックし、「Tables」で「CSV_source」を選択します。
- カラムを選択し、「Add data」をクリックします。
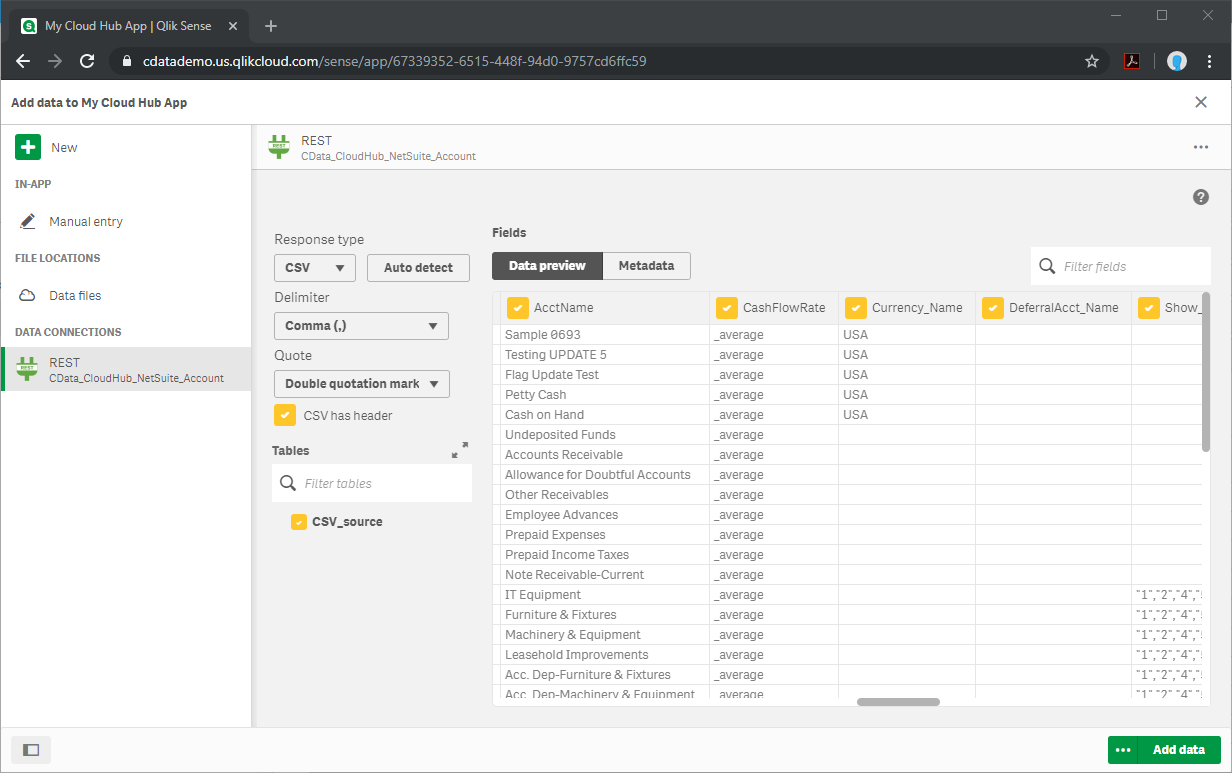
実際にデータを分析する
データがQlik Sense にロードされたので、洞察を引き出すことができます。「Generate insights」をクリックすると、Qlik がデータを分析します。もしくは、Spark のデータを使用してカスタムのビジュアライゼーション、レポート、ダッシュボードを作成できます。
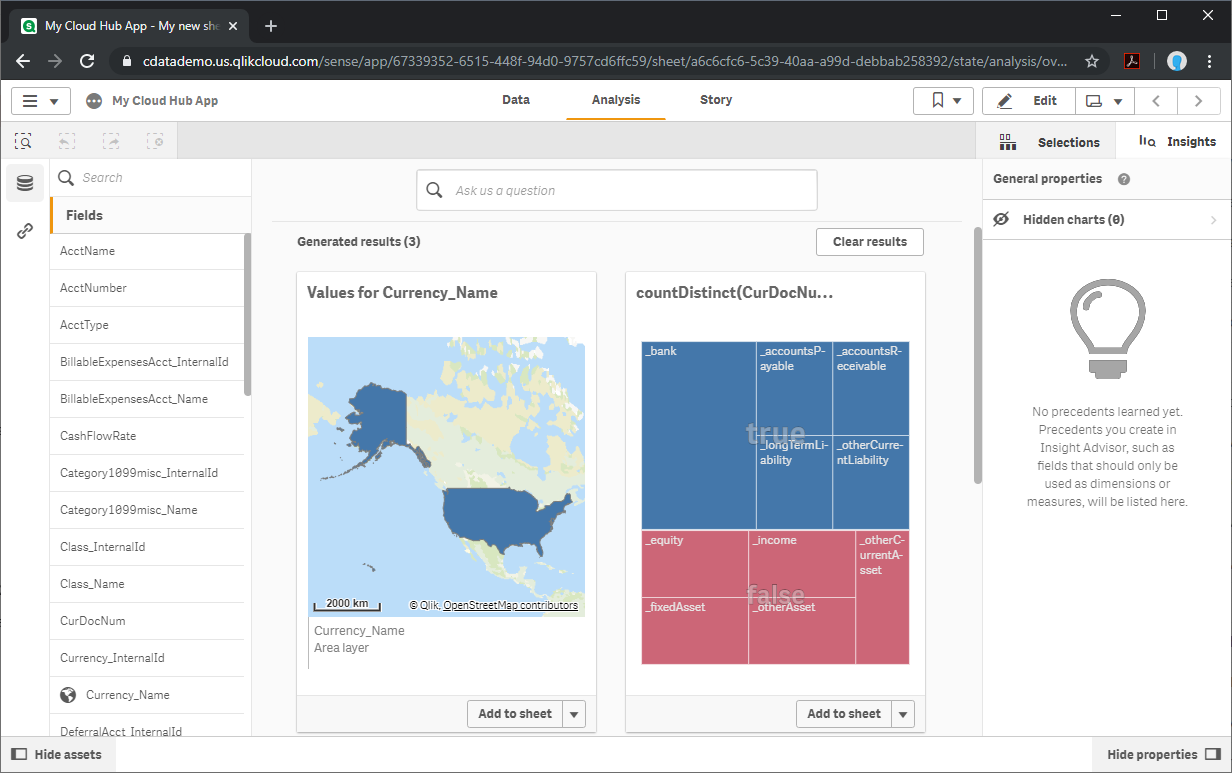
詳細と無料トライアル
これで、リアルタイムSpark のデータから簡単で強力なダッシュボードが作成されました。Spark(および250 以外のデータソース)のOData フィードを作成する方法の詳細については、API Server ページにアクセスしてください。無料トライアルにサインアップして、Qlik Sense Cloud でリアルタイムSpark のデータの操作を開始します。