





OData を介してTIBCO Spotfire でSpark のデータをビジュアライズ

OData は、クラウドベース、モバイル、およびその他のオンラインアプリケーション間のリアルタイム通信を可能にする主要なプロトコルです。CData API Server は、Spark のADO.NET Provider for SparkSQL と組み合わせると、Spark のデータ(またはその他の250+ のADO.NET Providers データ)をTIBCO Spotfire などのOData コンシューマに提供します。この記事では、API Server とSpotfire のOData の組み込みサポートを使用して、Spark のデータにリアルタイムでアクセスする方法を説明します。
API Server の設定
以下のリンクからAPI Server の無償トライアルをスタートしたら、セキュアなSpark OData サービスを作成していきましょう。
Spark への接続
TIBCO Spotfire からSpark のデータを操作するには、まずSpark への接続を作成・設定します。
- API Server にログインして、「Connections」をクリック、さらに「接続を追加」をクリックします。
- 「接続を追加」をクリックして、データソースがAPI Server に事前にインストールされている場合は、一覧から「Spark」を選択します。
- 事前にインストールされていない場合は、コネクタを追加していきます。コネクタ追加の手順は以下の記事にまとめてありますので、ご確認ください。
CData コネクタの追加方法はこちら >> - それでは、Spark への接続設定を行っていきましょう!
-
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
- 接続情報の入力が完了したら、「保存およびテスト」をクリックします。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
API Server のユーザー設定
次に、API Server 経由でSpark にアクセスするユーザーを作成します。「Users」ページでユーザーを追加・設定できます。やってみましょう。
- 「Users」ページで ユーザーを追加をクリックすると、「ユーザーを追加」ポップアップが開きます。
-
次に、「ロール」、「ユーザー名」、「権限」プロパティを設定し、「ユーザーを追加」をクリックします。

-
その後、ユーザーの認証トークンが生成されます。各ユーザーの認証トークンとその他の情報は「Users」ページで確認できます。

Spark 用のAPI エンドポイントの作成
ユーザーを作成したら、Spark のデータ用のAPI エンドポイントを作成していきます。
-
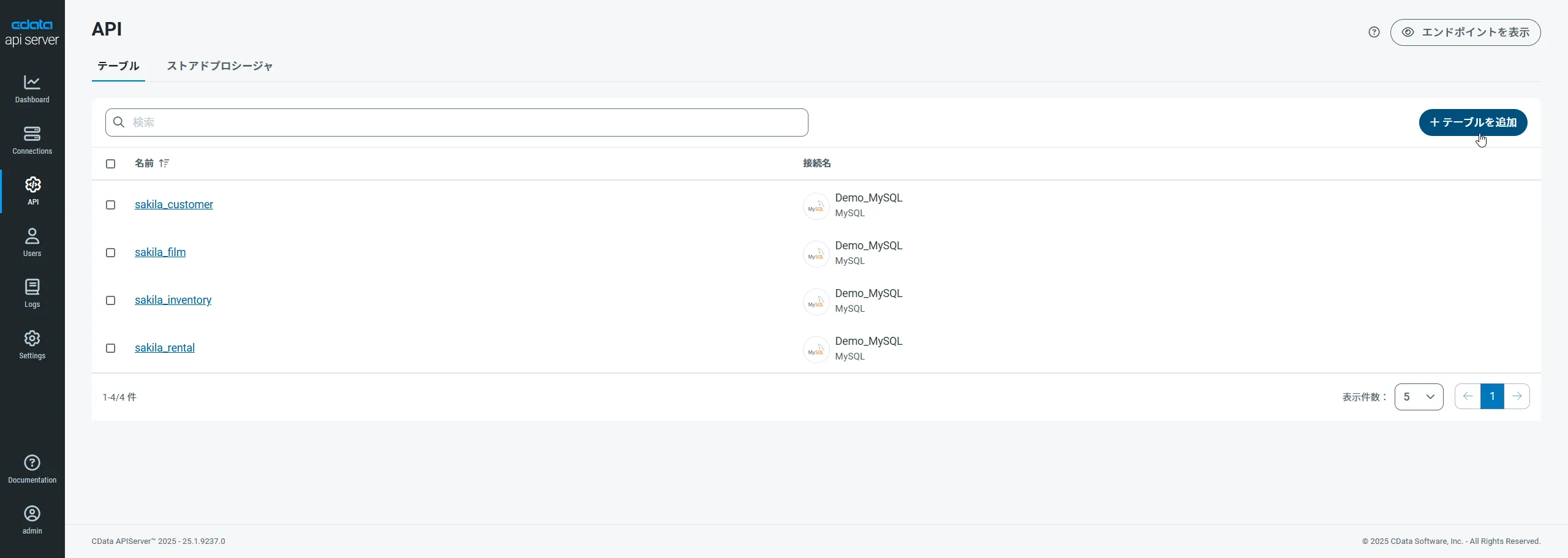
まず、「API」ページに移動し、
「 テーブルを追加」をクリックします。
-
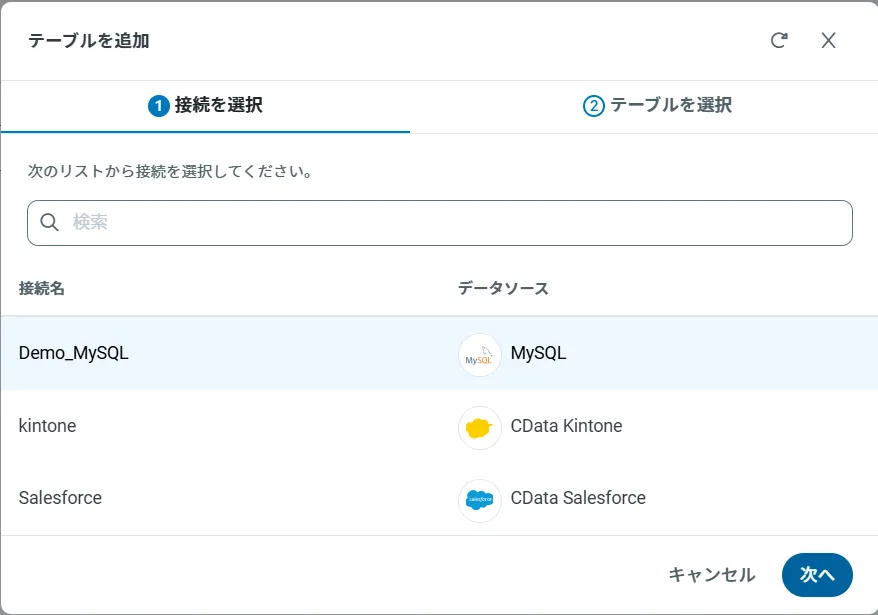
アクセスしたい接続を選択し、次へをクリックします。
-
接続を選択した状態で、各テーブルを選択して確認をクリックすることでエンドポイントを作成します。

OData のエンドポイントを取得
以上でSpark への接続を設定してユーザーを作成し、API Server でSpark データのAPI を追加しました。これで、OData 形式のSpark データをREST API で利用できます。API Server の「API」ページから、API のエンドポイントを表示およびコピーできます。

外部Spark のデータでデータビジュアライゼーションを作成する
- Spotfire を開き、「Add Data Tables」->「OData」をクリックします。
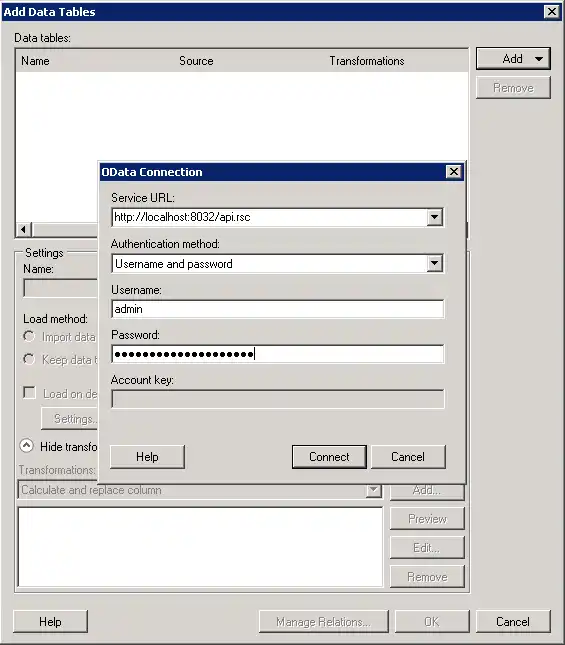
- 「OData Connection」ダイアログで、以下の情報を入力します。
- Service URL:API Server のOData エンドポイントを入力します。例:
http://localhost:8032/api.rsc
- Authentication Method:Username とPassword を選択します。
- Username:API Server ユーザーのユーザー名を入力します。管理コンソールの「Security」タブでAPI ユーザーを作成できます。
- Password:API Server でユーザーの認証トークンを入力します。
- Service URL:API Server のOData エンドポイントを入力します。例:
- ダッシュボードに追加するテーブルとカラムを選択します。この例ではCustomers を使います。
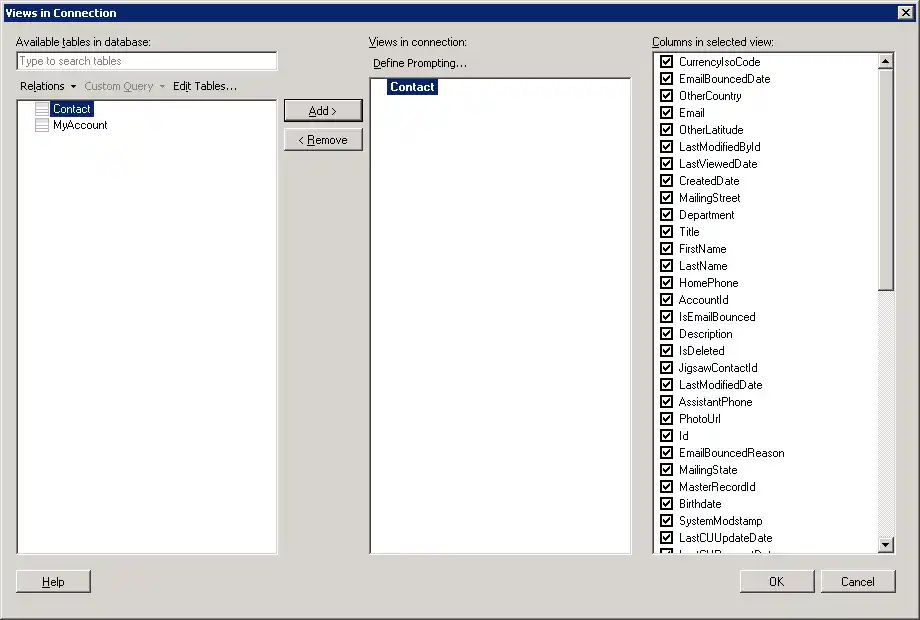
- リアルタイムデータを使いたい場合は、「Keep Data Table External」オプションをクリックします。このオプションは、データの変更をリアルタイムでダッシュボードに反映します。
データをメモリにロードしてローカルで処理したい場合は、「Import Data Table」オプションをクリックします。このオプションは、オフラインでの使用、またはネットワーク接続が遅くダッシュボードとのやり取りが遅延する場合に適しています。
- テーブルを追加すると「Recommended Visualizations」ウィザードが表示されます。テーブルを選択すると、Spotfire はカラムのデータ型を使ってnumber、time、category カラムを検出します。この例ではNumbers セクションでBalance を、Categories セクションでCity を使用しています。
[Recommended Visualizations]ウィザードでいくつかビジュアライズを作成したら、ダッシュボードにその他の修正を加えることができ、例えばフィルタを適用できます。「Filter」ボタンをクリックすると、各クエリで使用可能なフィルタが「Filters」ペインに表示されます。