株式会社I-ne はシャンプーなどのヘアケア製品や美容家電、スキンケア製品などの開発、販売を行うファブレスメーカーです。
同社ではこれまで売上や経費、マーケティングのKPI に関わるデータを部門ごとに活用してきました。しかし、既存の運用では手作業やRPA で対応している部分も多く、追加の連携のための工数も嵩んでしまうことから、事業の急成長に合わせた効率的なデータ分析基盤の整備が急務となっていました。
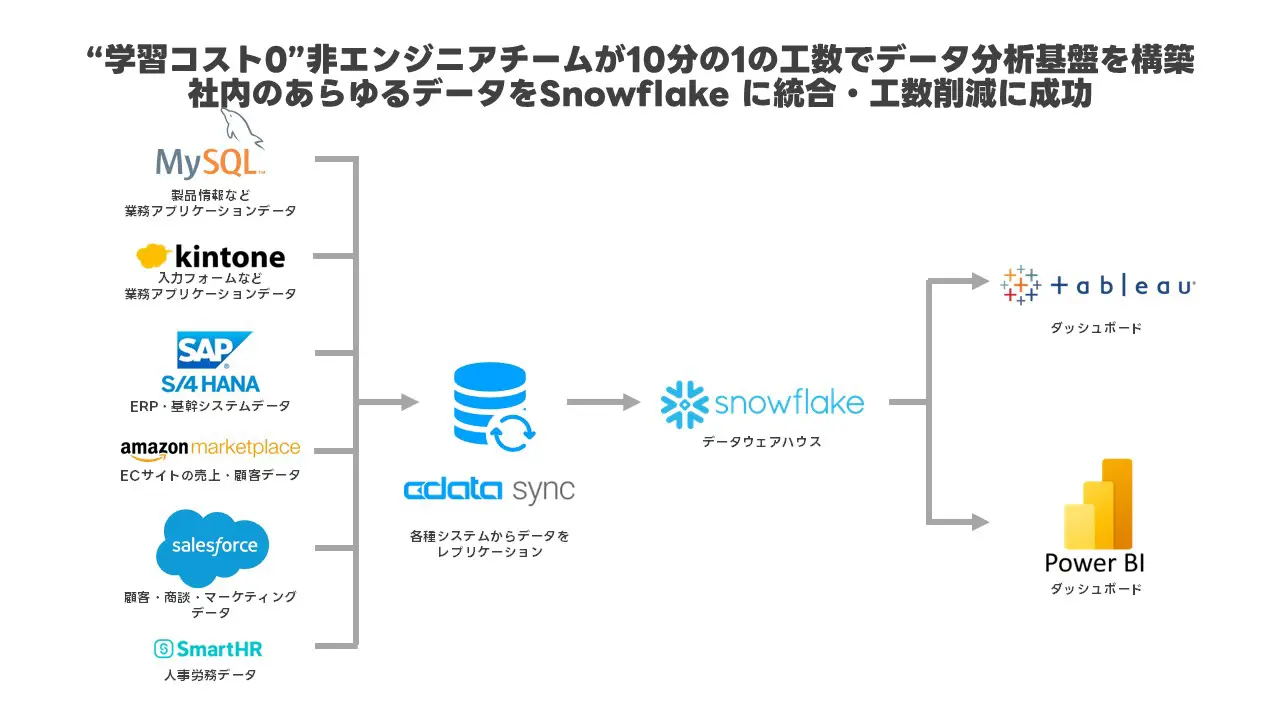
そこで、データ分析基盤のDWH として新しくSnowflake を導入するとともに、データ統合にはノーコードのデータパイプラインツールである『CData Sync』を採用。エンジニアの少ない環境下においても内製でデータ連携基盤の構築を実現するとともに、運用工数の削減と連携頻度・連携対象データの大幅な増加に成功しました。
Challenges:
スパゲッティ状態になっていたデータ連携のアーキテクチャから脱却し、事業部門からのリクエストに迅速に対応できるデータ分析基盤の整備
手作業やRPA で対応していた非効率なデータ収集作業の効率化
非エンジニアチームによるスピーディなデータ分析基盤の構築・内製化
Solutions:
Snowflake を中心としたデータ収集・分析基盤のアーキテクチャをELT 方式で刷新。連携頻度・連携対象データの種類を大幅増
『CData Sync』に各種SaaS・ERP・RDB からの連携処理を集約することでデータパイプラインを効率化。連携処理の安定化とメンテナンス工数の削減に成功
学習コストが0のノーコードベースの製品を使用することで、想定の10分の1の期間でデータ分析基盤の構築を実現
本件をリードされた、IT ストラテジー室室長の川本佳希氏にお話をお伺いしました。
Q:今回のプロジェクトに取り組まれた背景を教えてください。
川本氏:当社は急激に人数基盤を増やしてきた会社です。各チームでデータを駆使してビジネスを推進していくカルチャーがあり、これまで各分野のスペシャリティを持つメンバーがそれぞれセルフサービスで分析業務を行っていました。しかし、急激な成長に従い、より効率的なデータの整備が必要となり、分析基盤のアーキテクチャの見直しが求められました。
具体的なアーキテクチャの課題は以下の三点です。
まず一点目は、既存の業務では手作業やRPA で集計処理を行ったものをDWH にインポートしなおすような作業が発生していた点です。手作業は労力がかかりますし、RPA は管理も煩雑になり継続性に懸念がありました。
二点目は上述のRPA に関するものです。RPA は一覧の取得やCSV のエクスポートといった画面操作を行うものも多くあり、動作が不安定でメンテナンスに工数がかかるなど、安定的な運用に課題がありました。
三点目は、全体のデータ分析基盤に関する課題です。当社ではIT に強い人材が少なかったということもあり、既存の基幹システムからDWH へのデータ連携処理は処理が複雑に入り組み、いわゆるスパゲッティ状態になっていました。そのため既存の仕様の読み解きが困難で、メンテナンスや変更要望があっても調査だけで多大な工数がかかる状態でした。
実は昨年、基幹システムの刷新とそれに付随するシステムの入れ替えを実施し、データ分析基盤については既存のDWH を廃止してSnowflake で再構築を行っていました。そういった取り組みが進む中で、ボトルネックとなっていたデータ連携に関しても早急な改善が必要という状況だったのです。
ちなみにデータ分析基盤の構築については、スピード感をもってビジネスを展開するため外注に依頼することなく社内でコントロールできる環境をつくることを理想としていました。しかし、社内にエンジニアが少ないという状況でどのように内製化を実現するか、その方法を模索しているところでした。
Q:CData Sync をお選びいただけたポイントをお聞かせください。
川本氏:もともと当社ではSAP S/4HANA の連携のためにCData のコネクタを導入しており、CData にはコネクタの種類が豊富という印象を持っていました。CData がスポンサーとして出展していたイベントでブースを見つけて立ち寄った際に、SaaS やDB からSnowflake へのデータ連携を行いたいという話をしたところ『CData Sync』の提案があり、そこから検討を開始しました。
CData Sync を採用したポイントは三点あります。
まず一点目は、ノーコードベースの製品のため、学習コストをかけずに使うことができること。
二点目は、Amazon Marketplace やSmartHR など、コネクタが豊富なところです。ものによっては処理の作成自体は簡単にできるものもありますが、それでも監視や運用面まで考慮するとツールで対応している方が楽なうえに安心感が違います。
三点目ですが、当社では点在しているデータをまるっとSnowflake に集約し、そこから先で処理を行うという方針でDWH の設計をしていました。その点、シンプルにデータをレプリケーションできるCData Sync が当社のニーズにフィットしていると感じました。
Q:CData Sync 導入効果はいかがでしょうか?
川本氏:非エンジニアばかりのチームでもスムーズに導入することができました。
導入に関しては、内製で対応する場合半年程度かかる想定でしたが、CData Sync の場合は実稼働5~10日程度で導入できました。導入のためにかかった学習コストが0で、その点が本当に素晴らしかったです。
導入後の運用においても、品質やメンテナンスの心配がないため、削減した工数で別の業務に注力できるようになりました。わからないことなどがあればテクニカルサポートに問い合わせることもありますが、その場合もすぐに解決できています。
CData Sync の導入によって、これまで手作業が発生するためボトルネックとなっていたデータ連携が改善されました。また、RPA を使った処理ではメモリ不足となってしまうためできることが限られていましたが、CData Sync でデータ連携を行うようになったことでそのような制約がなくなり、気兼ねなくデータを取り込めるようになったため、連携の頻度と連携対象データが大幅に増加しました。
Q:よろしければ今後の展望をお聞かせいただけますか?
川本氏:直近では、Snowflake のDWH を社内ユーザーに開放することが決まっています。
これまでダッシュボードの構築はIT 部門が担当していましたが、自社ブランドも増え、分析にスピード感が求められるようになってきています。そこを各チームがセルフサービス・市民開発でスピーディに対応できるようにするための取り組みです。
併せて、ただDWH を開放するだけでなく、各チームが各データやテーブル・項目の意味を理解して、スムーズに分析に繋げやすいように、データカタログも展開いたします。
また、AI の活用についても、競争優位性を確保するため、現在整備を進めています。社内のデータをAI エージェントを通じて活用することにも関心があるため、さまざまなシステムをAI エージェントと連携して、分析・活用することができる『CData MCP Server』にも期待しています。
記事公開日:2025年10月6日




