




RabbitMQ データをHeroku Postgres にレプリケーションして、Salesforce Connect から利用する方法

CData Sync は、いろいろなシナリオのデータレプリケーション(同期)を行うことができるスタンドアロンのアプリケーションです。例えば、sandbox および本番インスタンスのデータをデータベースに同期することができます。RabbitMQ のデータ をHeroku 上のPostgreSQL に同期することで、Salesforce の通常オブジェクトに加えて、Salesforce 外部オブジェクト(Salesforce Connect)としてRabbitMQ のデータへのアクセスが可能になります。
要件
本レプリケーション例では、次が必要です:
- CData Sync (試用版もしくは商用版)、およびRabbitMQ のレプリケーションに必要なライセンス。
- Heroku Postgress を含むHeroku app および、Heroku Connect アドオン許可。
- Salesforce アカウント。
レプリケーション同期先の設定
CData Sync を使って、RabbitMQ のデータ をHeroku 上のPostgreSQL データベースにレプリケーションできます。本記事では、Heroku 上の既存のPostgreSQL を使用します。PostgreSQL データベースをレプリケーション先に指定するには、[接続]タブから進みます。
- [同期先]タブをクリックします。
- PostgreSQL を同期先として選択します。
PostgreSQL への接続には、Port(デフォルトでは5432)、およびデータベース接続プロパティを設定し、サーバーに認証するuser およびpassword を設定します。データベースプロパティが指定されていない場合には、ユーザーのデフォルトデータベースに接続します。
- 接続のテスト]をクリックして、正しく接続できているかをテストします。
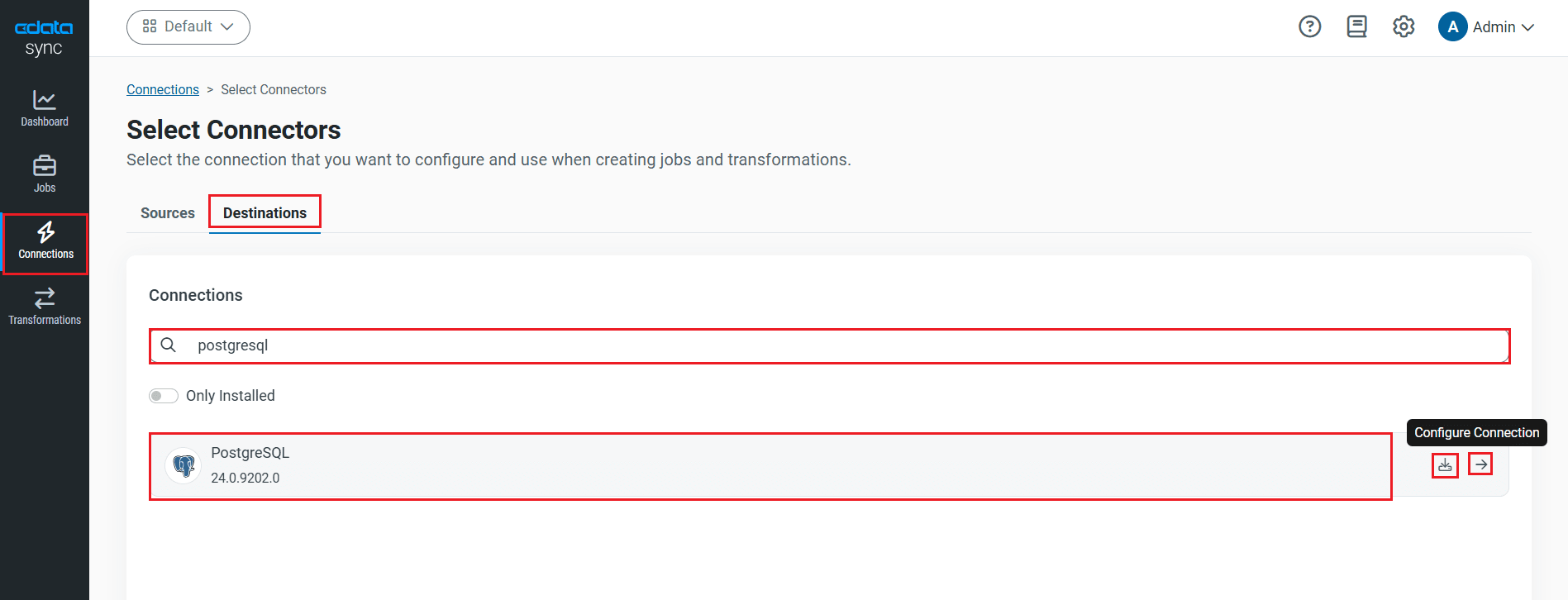
- [変更を保存]をクリックします。
RabbitMQ 接続の設定
データソース側にRabbitMQ を設定します。[接続]タブをクリックします。
- [接続の追加]セクションで[データソース]タブを選択します。
- RabbitMQ アイコンをデータソースとして選択します。プリインストールされたソースにRabbitMQ がない場合には、追加データソースとしてダウンロードします。
- 接続プロパティに入力をします。
RabbitMQ Management HTTP API について
RabbitMQ は、複数のメッセージングプロトコルをサポートするオープンソースのメッセージブローカーです。RabbitMQ Management HTTP API は、RabbitMQ サーバーの管理データと監視データに HTTP 経由でアクセスする手段を提供します。この API では、仮想ホスト、エクスチェンジ、キュー、バインディング、コネクション、チャネル、コンシューマー、ユーザー、権限、ポリシー、クラスター全体の統計情報を取得できます。
HTTP API を利用するには、RabbitMQ サーバーで Management プラグインを有効化する必要があります。デフォルトでは、管理インターフェースはポート 15672 でリッスンします。
Basic 認証の設定
RabbitMQ Management HTTP API は HTTP Basic 認証を使用します。RabbitMQ 管理ユーザーのユーザー名とパスワードを指定する必要があります。
管理 API へのアクセスを有効にするには、以下のステップで進めます:
- サーバーで RabbitMQ Management プラグインが有効になっていることを確認します(rabbitmq-plugins enable rabbitmq_management)。
- 既存の管理ユーザーを使用するか、適切な管理タグ(management、policymaker、monitoring、または administrator)を持つユーザーを作成します。
- RabbitMQ Management HTTP API の完全なベース URL を控えておきます(例:http://localhost:15672)。
RabbitMQ サーバーを設定したら、以下の接続プロパティを設定して接続します:
- AuthScheme:Basic に設定します。
- URL:RabbitMQ Management HTTP API のベース URL に設定します(例:http://localhost:15672)。
- User:RabbitMQ の管理ユーザー名に設定します(例:guest)。
- Password:RabbitMQ の管理パスワードに設定します。
接続文字列の例:
Profile=C:\profiles\RabbitMQ.apip;AuthScheme=Basic;URL=http://localhost:15672;User=guest;Password=guest;
利用可能なテーブル
RabbitMQ プロファイルでは、以下のテーブルにアクセスできます:
- Overview - クラスター全体の統計情報と RabbitMQ ノードに関する情報
- Nodes - RabbitMQ クラスター内の個々のノードに関する情報
- NodeMemory - 特定のクラスターノードの詳細なメモリ使用状況の内訳
- Connections - ブローカーへのすべてのオープンな AMQP コネクションの一覧
- Channels - すべてのコネクションにわたるオープンな AMQP チャネルの一覧
- Consumers - すべてのキューに登録されたコンシューマーの一覧
- Exchanges - すべての仮想ホストで宣言されたエクスチェンジの一覧
- Queues - すべての仮想ホストで宣言されたキューの一覧
- Bindings - エクスチェンジとキュー間のすべてのバインディングの一覧
- VirtualHosts - ブローカーに設定された仮想ホストの一覧
- VhostPermissions - 特定の仮想ホスト内のユーザー権限
- Users - すべての RabbitMQ ユーザーの一覧
- Permissions - すべての仮想ホストにわたる全ユーザーの権限レコード
- TopicPermissions - 全ユーザーのトピックレベルの権限レコード
- Policies - 仮想ホスト内のキューおよびエクスチェンジに適用されたポリシーの一覧
- OperatorPolicies - 仮想ホスト内のキューに適用されたオペレーターポリシーの一覧
- Parameters - 仮想ホストごとのコンポーネントパラメータ(例:federation、shovel)の一覧
- GlobalParameters - すべての仮想ホストに適用されるグローバルパラメータの一覧
- VhostLimits - 特定の仮想ホストに設定されたリソース制限
- UserLimits - 特定のユーザーに設定されたリソース制限
- FeatureFlags - フィーチャーフラグの一覧と、ノード上での有効/無効の状態
- DeprecatedFeatures - 非推奨機能の一覧と、その使用状態
- AuthAttempts - ノードの認証試行統計
- ClusterName - RabbitMQ クラスターの名前
- WhoAmI - 現在認証されている管理ユーザーに関する情報
- ExchangeBindingsSource - 特定のエクスチェンジがソースとなっているバインディング
- ExchangeBindingsDestination - 特定のエクスチェンジが宛先となっているバインディング
- QueueBindings - 仮想ホスト内の特定のキューのバインディング
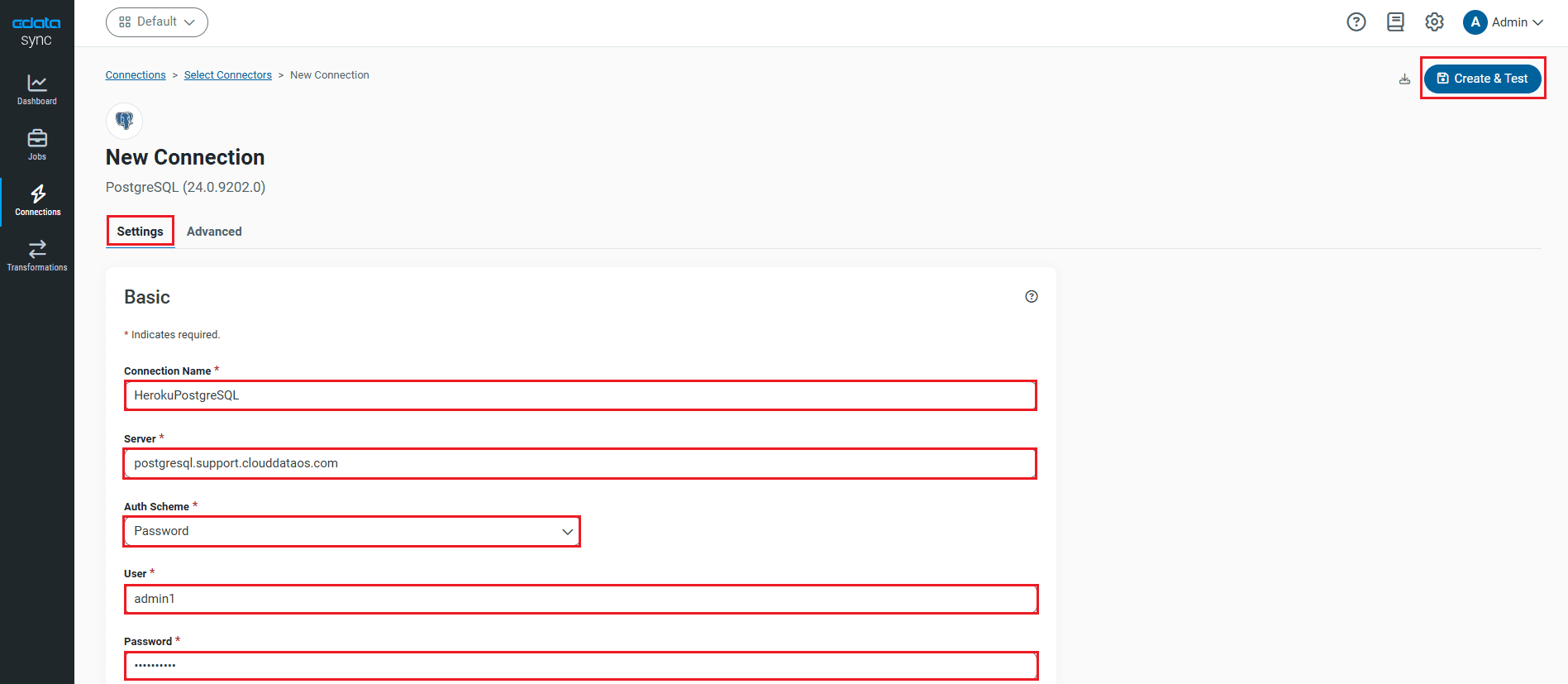
- [接続のテスト]をクリックして、正しく接続できているかをテストします。
- [変更を保存]をクリックします。
RabbitMQ インスタンス毎のクエリの設定
Data Sync はレプリケーションをコントロールするSQL クエリを簡単なGUI 操作で設定できます。
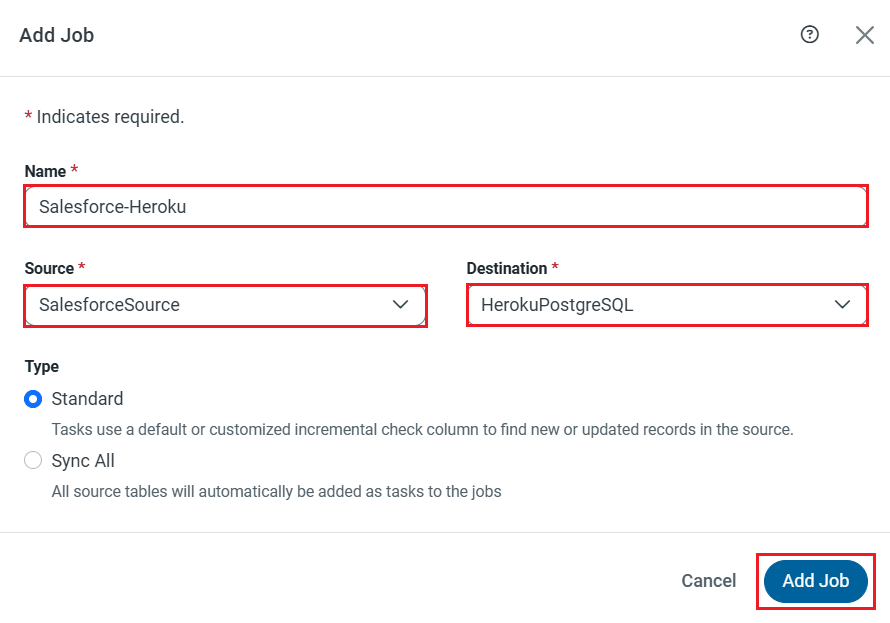
レプリケーションジョブ設定には、[ジョブ]タブに進み、[ジョブを追加]ボタンをクリックします。
次にデータソースおよび同期先をそれぞれドロップダウンから選択します。
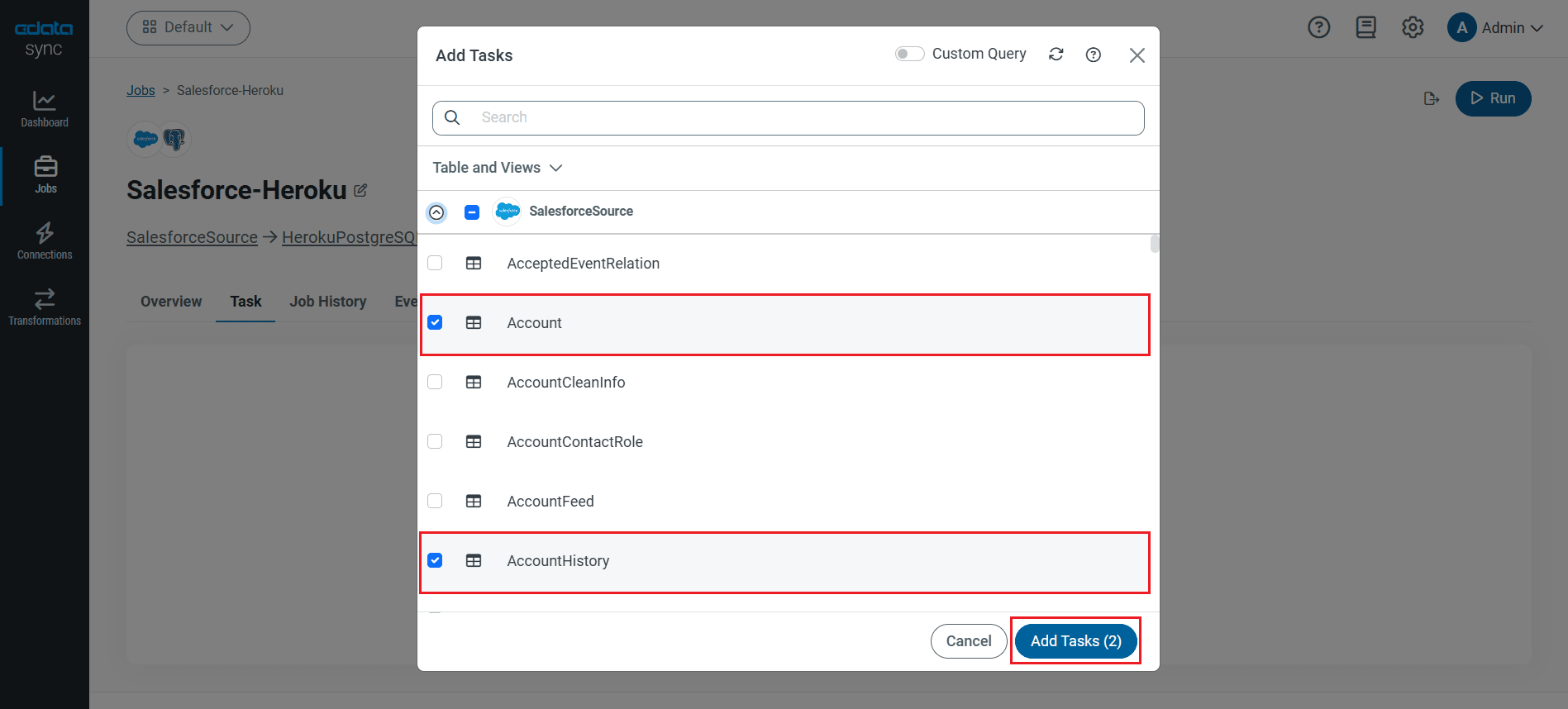
テーブル全体をレプリケーションする
テーブル全体をレプリケーションするには、[テーブル]セクションで[テーブルを追加]をクリックします。表示されたテーブルリストからレプリケーションするテーブルをチェックします。
テーブルをカスタマイズしてレプリケーションする
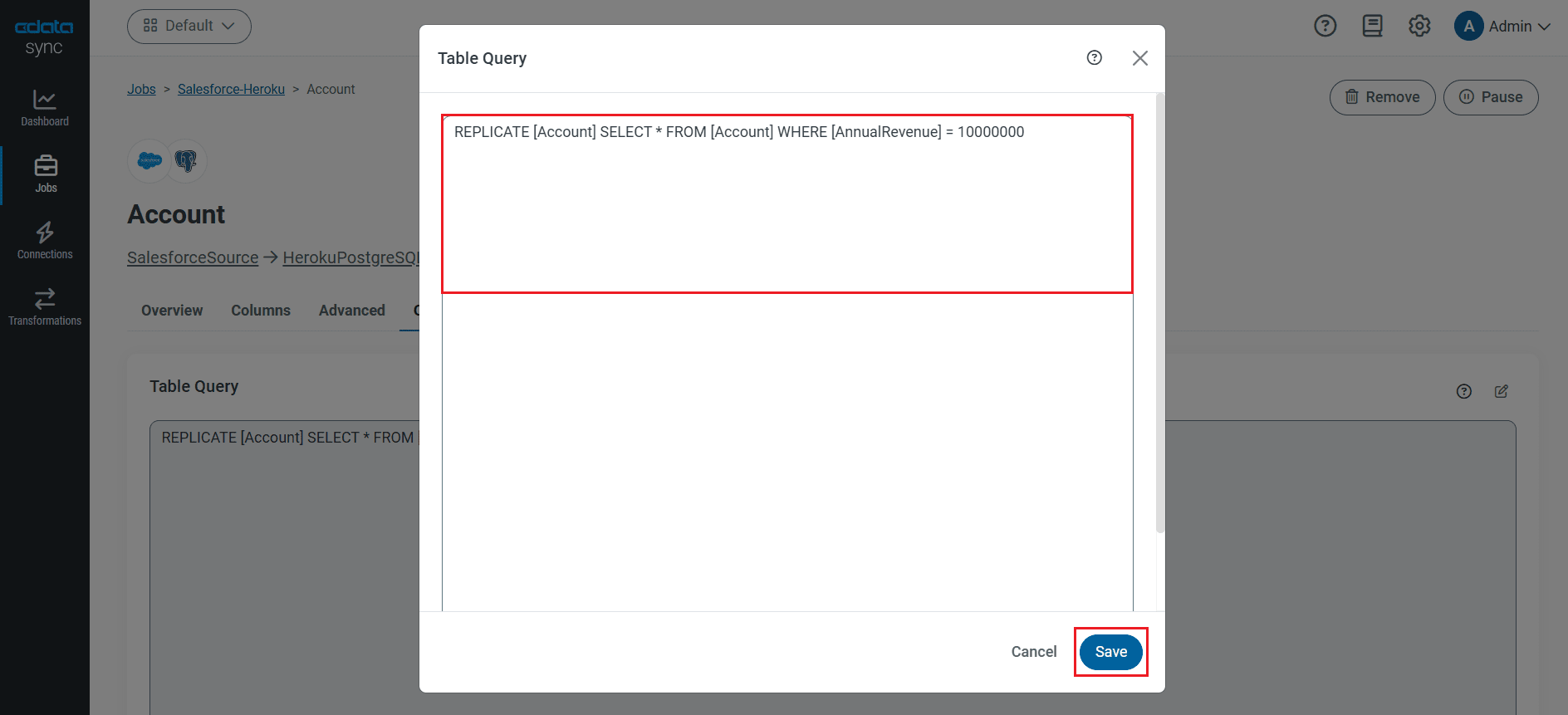
レプリケーションはテーブル全体ではなく、カスタマイズが可能です。[変更]機能を使えば、レプリケーションするカラムの指定、同期先でのカラム名を変更しての保存、ソースデータの各種加工が可能です。レプリケーションのカスタマイズには、ジョブの[変更]ボタンをクリックしてカスタマイズウィンドウを開いて操作を行います:
- チェックボックスでフィールドを追加もしくは削除
- カラムリストの下に新しく計算されたフィールドを追加する
- フィルタセクションを利用してフィルタを追加する
インターフェースを使って変更を行うと、レプリケーションのSQL クエリは以下のようなシンプルなものから:
REPLICATE [AuthAttempts]
次のような複雑なものになります:
REPLICATE [AuthAttempts] SELECT [], [] FROM [AuthAttempts] WHERE [NodeName] = rabbit@hostname
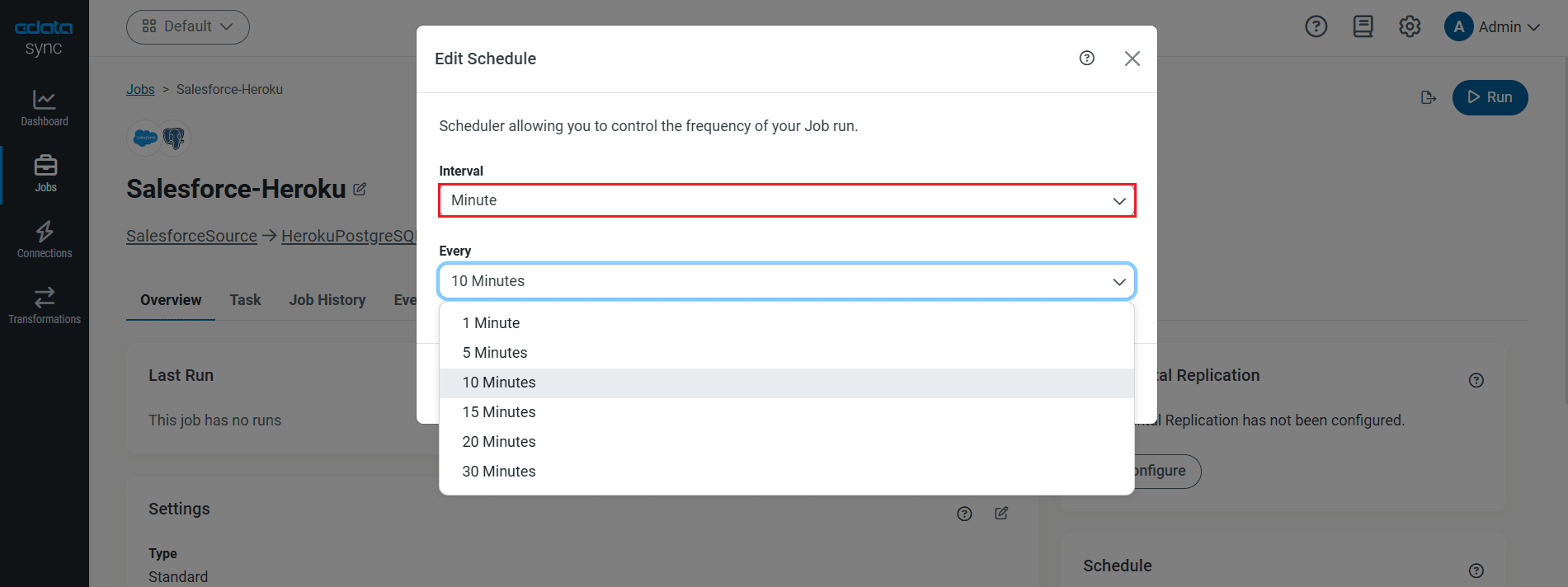
レプリケーションのスケジュール起動設定
[スケジュール]セクションでは、レプリケーションジョブの自動起動スケジュール設定が可能です。反復同期間隔は、15分おきから毎月1回までの間で設定が可能です。
レプリケーションジョブを設定したら、[変更を保存]ボタンを押して保存します。複数のRabbitMQ のデータ のジョブを作成して、Salesforce の外部オブジェクトとして利用可能です。
外部オブジェクトとしてRabbitMQ データレプリケーションにアクセス
RabbitMQ のデータ がHeroku 上のPostgreSQL データベースとしてレプリケーションされたので、Heroku のOData インターフェースを設定し、Salesforce Connect から外部オブジェクトとしてデータ連携できるようにします。
Heroku のOData Service を設定します
まずは、Heroku 上のPostgreSQL データベースに複製されたRabbitMQ のデータ への接続のために、データベースに対しHeroku External Object を設定します。
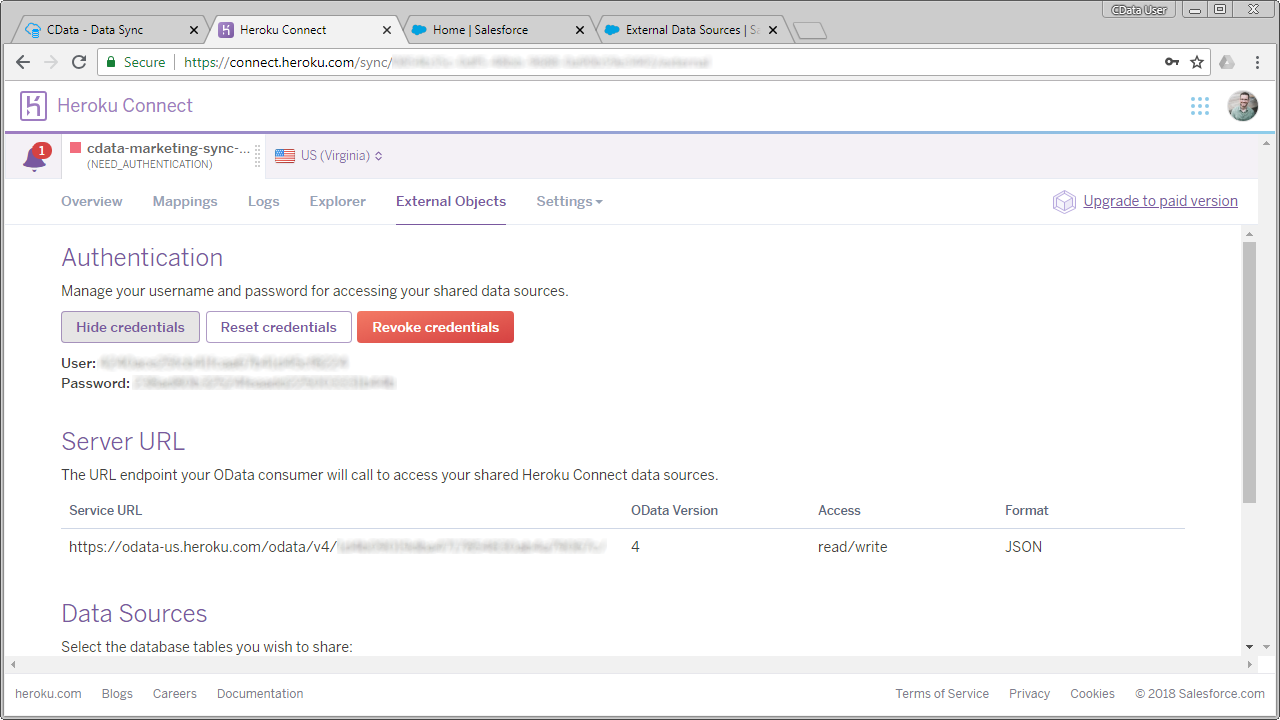
- Heroku ダッシュボードで、[Connect Add-on] をクリックします。
- [External Objects]を指定します。はじめてHeroku External Object を使用する場合には、OData Server のログインクレデンシャルを作成するようにナビゲートされます。
- OData service URL およびクレデンシャルを確認します。このクレデンシャルをSalesforce Connect 接続時に利用します。
- [Data Sources]において、前のプロセスで作成したレプリケーション済みデータベースを設定します。
詳しくは、こちらのHeroku documentation を参照してください。
Salesforce の外部データソースの設定
Heroku のOData サービスの設定が終わったら、Salesforce Connect を使って、複製されたRabbitMQ のデータ のデータに外部データソースとして連携します。
- Salesforce で設定をクリックします。
- Administration (管理)セクションで、[データ]→[外部データソース]をクリック。
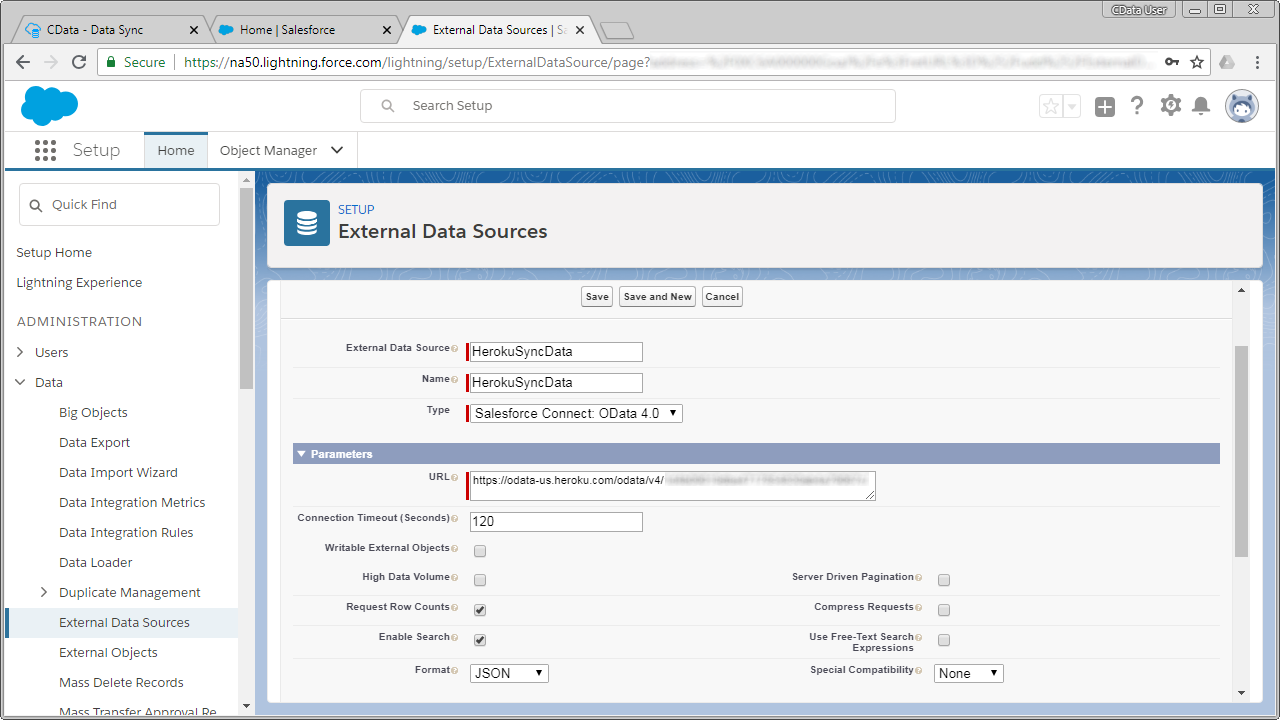
- データソースパラメータプロパティを設定します:
- External Data Source: Salesforce UI に表示される名前
- Name: API の一位の識別子
- Type: Salesforce Connect: OData 4.0
- URL: Heroku Connect のOData エンドポイント
- Format: JSON
- 認証の設定:
- Identity Type: Named Principal
- Authentication Protocol: Password Authentication
- Username: Heroku Connect username
- Password: Heroku Connect password
- [保存]をクリック。
RabbitMQ オブジェクトの同期
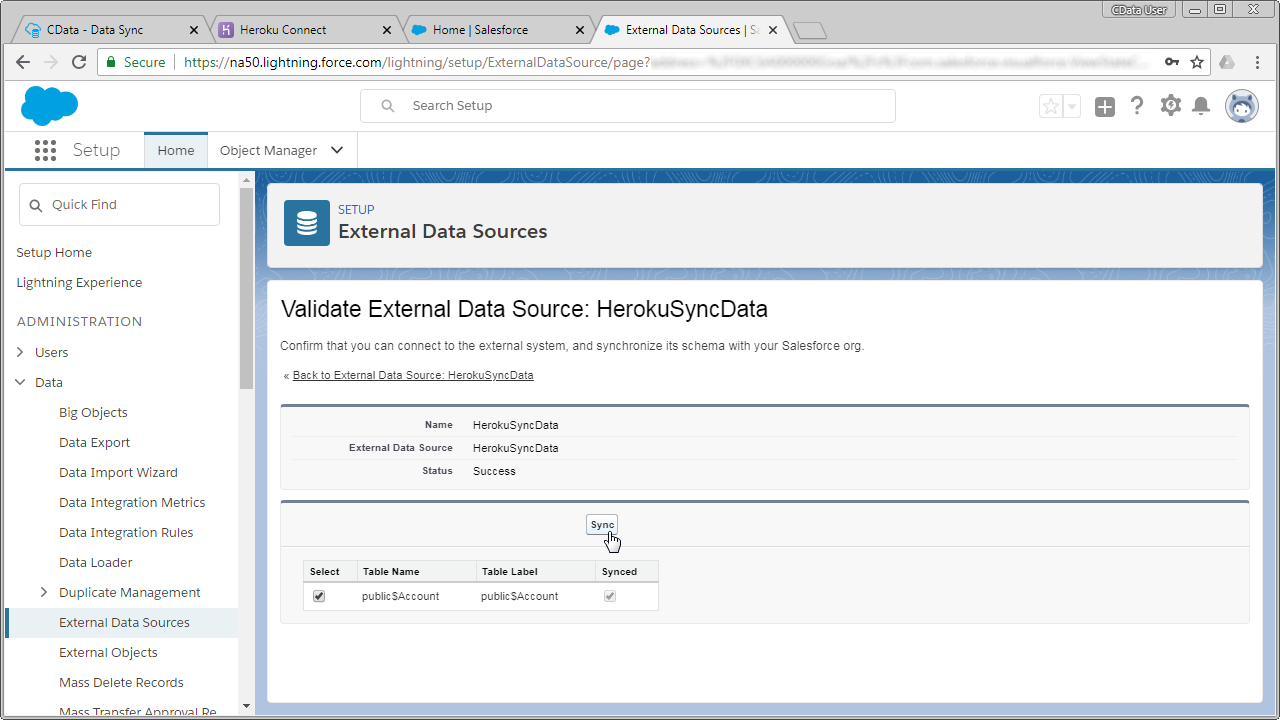
Salesforce の外部データソース登録が終わったら、次の方法でRabbitMQ 外部データソースに変更を反映させます。RabbitMQ テーブルの定義とRabbitMQ 外部オブジェクトの定義を同期します。
- 作成した外部データソースのリンクをクリック。
- [Validate and Sync]をクリック
- RabbitMQ テーブルを選択して、[同期]をクリックします。
Salesforce オブジェクトとしてRabbitMQ データにアクセス
これで、レプリケーションされたRabbitMQ エンティティに対して、Salesforce の通常オブジェクトと同じように外部オブジェクトとしてアクセスが可能になりました。
是非、CData Sync の30日の無償評価版 をダウンロードして、Salesforce との連携をお試しください!