




【ノーコード】複数のRabbitMQ アカウントのデータを簡単レプリケーション

CData Sync は、いろいろなシナリオのデータレプリケーション(同期)を行うことができるスタンドアロンのアプリケーションです。例えば、sandbox および本番インスタンスのデータをデータベースに同期することができます。CData Sync のウェブインターフェースは複数のRabbitMQ コネクションを簡単に管理できます。本記事では、複数のRabbitMQ アカウントを一つのデータベースに同期する方法を説明します。
レプリケーションの同期先を設定
CData Sync では、RabbitMQ のデータ を何台のデータベースにでも複製できます。データベースはクラウドおよびオンプレミスの双方に対応しています。レプリケーションの同期先の設定には、[接続]タブから行います。
- [同期先]タブを選択します。
- 同期先のアイコンをクリックします。本記事では、SQLite を使います。
- 必要な接続プロパティを入力します。RabbitMQ をSQLite に複製するには、データソースボックスにファイルパスを指定します。
- [接続のテスト]をクリックして、正しく接続できているかをテストします。
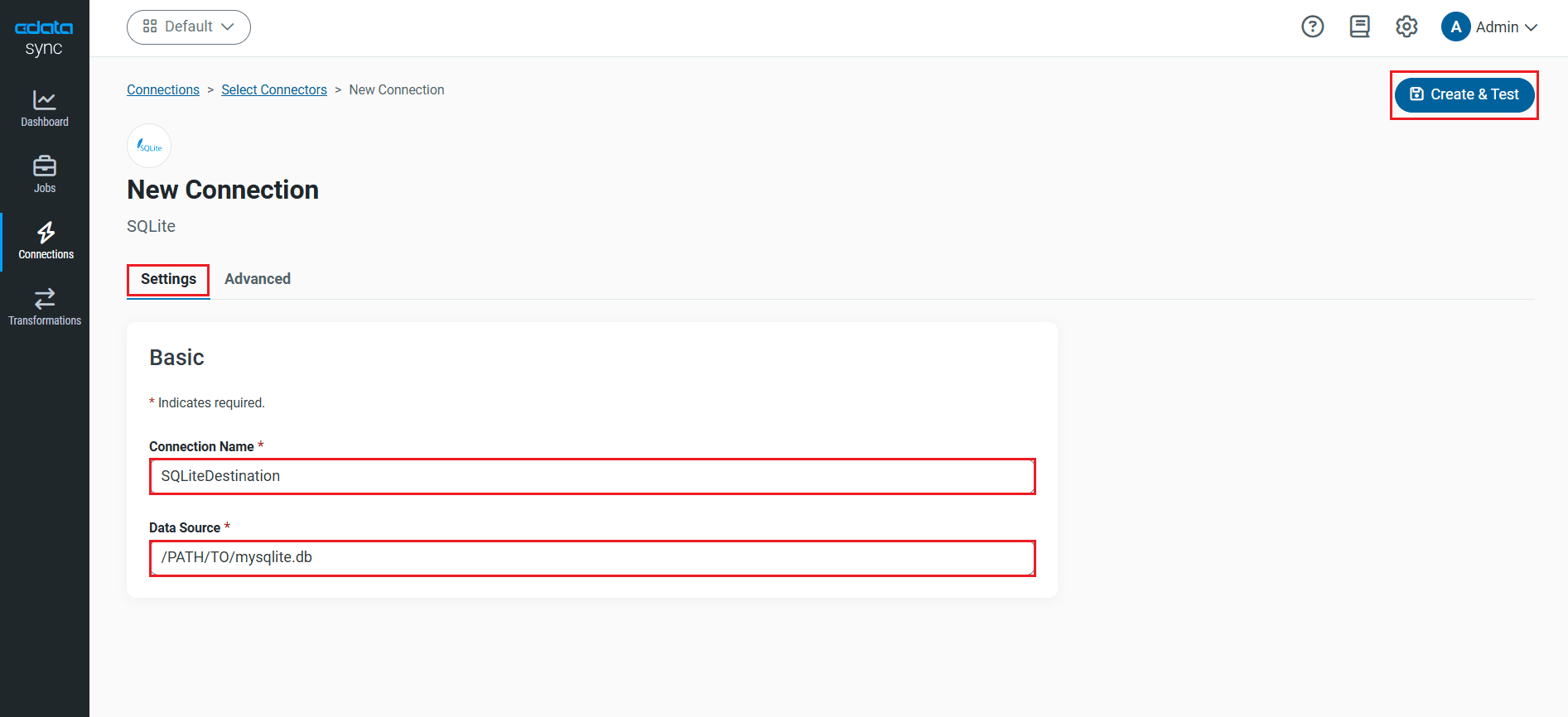
- [変更を保存]をクリックします。
RabbitMQ 接続の設定
データソース側にRabbitMQ を設定します。[接続]タブをクリックします。
- [接続の追加]セクションで[データソース]タブを選択します。
- RabbitMQ アイコンをデータソースとして選択します。プリインストールされたソースにRabbitMQ がない場合には、追加データソースとしてダウンロードします。
- 接続プロパティに入力をします。
RabbitMQ Management HTTP API について
RabbitMQ は、複数のメッセージングプロトコルをサポートするオープンソースのメッセージブローカーです。RabbitMQ Management HTTP API は、RabbitMQ サーバーの管理データと監視データに HTTP 経由でアクセスする手段を提供します。この API では、仮想ホスト、エクスチェンジ、キュー、バインディング、コネクション、チャネル、コンシューマー、ユーザー、権限、ポリシー、クラスター全体の統計情報を取得できます。
HTTP API を利用するには、RabbitMQ サーバーで Management プラグインを有効化する必要があります。デフォルトでは、管理インターフェースはポート 15672 でリッスンします。
Basic 認証の設定
RabbitMQ Management HTTP API は HTTP Basic 認証を使用します。RabbitMQ 管理ユーザーのユーザー名とパスワードを指定する必要があります。
管理 API へのアクセスを有効にするには、以下のステップで進めます:
- サーバーで RabbitMQ Management プラグインが有効になっていることを確認します(rabbitmq-plugins enable rabbitmq_management)。
- 既存の管理ユーザーを使用するか、適切な管理タグ(management、policymaker、monitoring、または administrator)を持つユーザーを作成します。
- RabbitMQ Management HTTP API の完全なベース URL を控えておきます(例:http://localhost:15672)。
RabbitMQ サーバーを設定したら、以下の接続プロパティを設定して接続します:
- AuthScheme:Basic に設定します。
- URL:RabbitMQ Management HTTP API のベース URL に設定します(例:http://localhost:15672)。
- User:RabbitMQ の管理ユーザー名に設定します(例:guest)。
- Password:RabbitMQ の管理パスワードに設定します。
接続文字列の例:
Profile=C:\profiles\RabbitMQ.apip;AuthScheme=Basic;URL=http://localhost:15672;User=guest;Password=guest;
利用可能なテーブル
RabbitMQ プロファイルでは、以下のテーブルにアクセスできます:
- Overview - クラスター全体の統計情報と RabbitMQ ノードに関する情報
- Nodes - RabbitMQ クラスター内の個々のノードに関する情報
- NodeMemory - 特定のクラスターノードの詳細なメモリ使用状況の内訳
- Connections - ブローカーへのすべてのオープンな AMQP コネクションの一覧
- Channels - すべてのコネクションにわたるオープンな AMQP チャネルの一覧
- Consumers - すべてのキューに登録されたコンシューマーの一覧
- Exchanges - すべての仮想ホストで宣言されたエクスチェンジの一覧
- Queues - すべての仮想ホストで宣言されたキューの一覧
- Bindings - エクスチェンジとキュー間のすべてのバインディングの一覧
- VirtualHosts - ブローカーに設定された仮想ホストの一覧
- VhostPermissions - 特定の仮想ホスト内のユーザー権限
- Users - すべての RabbitMQ ユーザーの一覧
- Permissions - すべての仮想ホストにわたる全ユーザーの権限レコード
- TopicPermissions - 全ユーザーのトピックレベルの権限レコード
- Policies - 仮想ホスト内のキューおよびエクスチェンジに適用されたポリシーの一覧
- OperatorPolicies - 仮想ホスト内のキューに適用されたオペレーターポリシーの一覧
- Parameters - 仮想ホストごとのコンポーネントパラメータ(例:federation、shovel)の一覧
- GlobalParameters - すべての仮想ホストに適用されるグローバルパラメータの一覧
- VhostLimits - 特定の仮想ホストに設定されたリソース制限
- UserLimits - 特定のユーザーに設定されたリソース制限
- FeatureFlags - フィーチャーフラグの一覧と、ノード上での有効/無効の状態
- DeprecatedFeatures - 非推奨機能の一覧と、その使用状態
- AuthAttempts - ノードの認証試行統計
- ClusterName - RabbitMQ クラスターの名前
- WhoAmI - 現在認証されている管理ユーザーに関する情報
- ExchangeBindingsSource - 特定のエクスチェンジがソースとなっているバインディング
- ExchangeBindingsDestination - 特定のエクスチェンジが宛先となっているバインディング
- QueueBindings - 仮想ホスト内の特定のキューのバインディング
- [接続のテスト]をクリックして、正しく接続できているかをテストします。
- [変更を保存]をクリックします。
それぞれのRabbitMQ インスタンスのレプリケーションクエリの設定
Data Sync はレプリケーションをコントロールするSQL クエリを簡単なGUI 操作で設定できます。
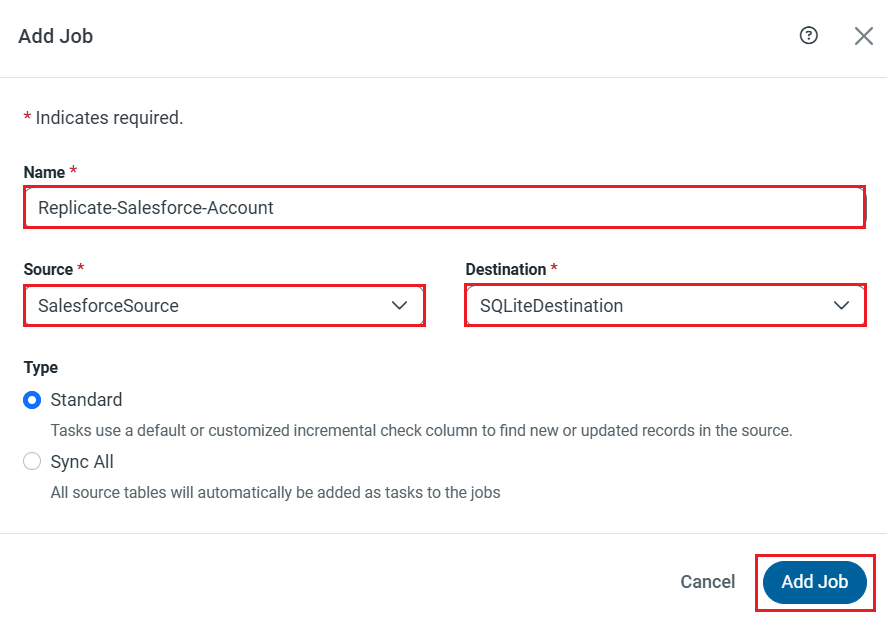
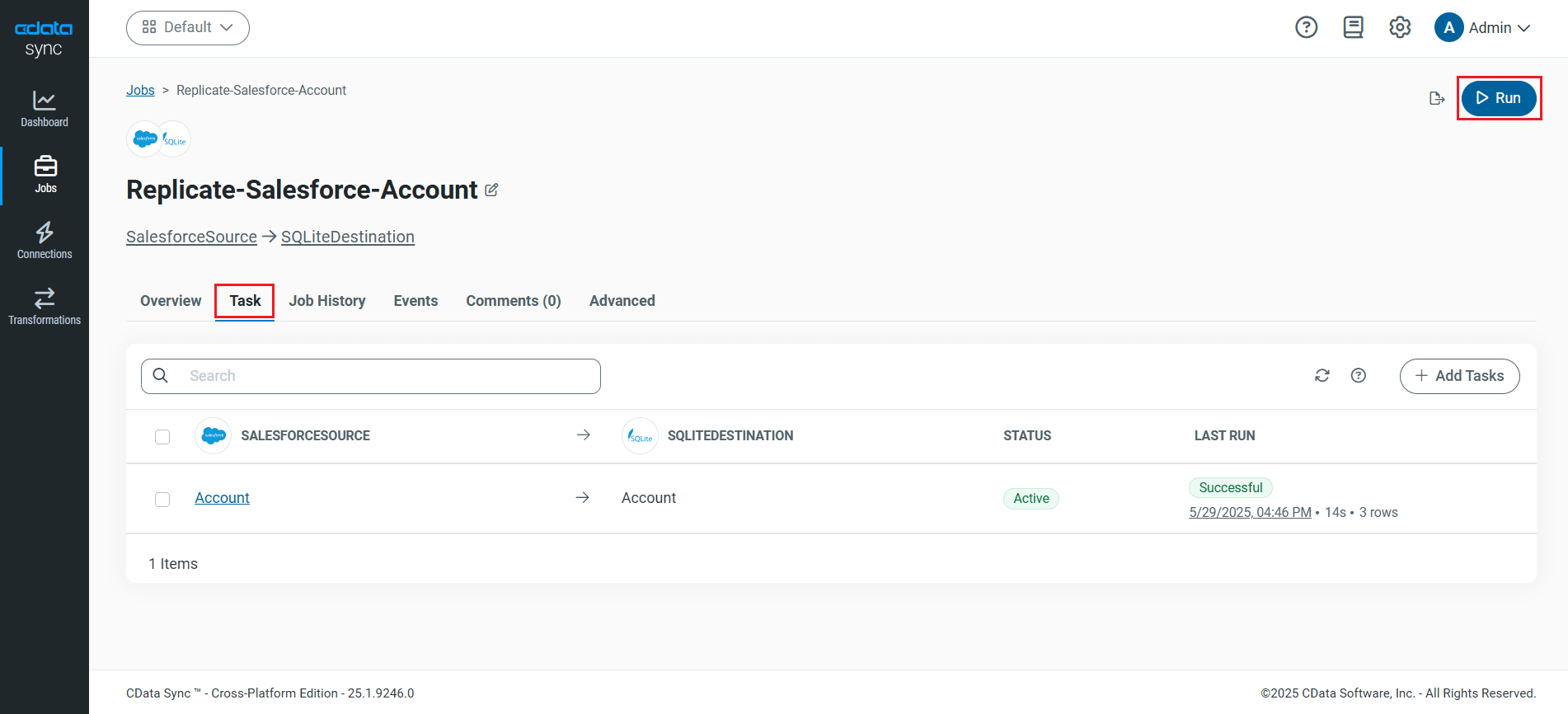
レプリケーションジョブ設定には、[ジョブ]タブに進み、[ジョブを追加]ボタンをクリックします。
次にデータソースおよび同期先をそれぞれドロップダウンから選択します。
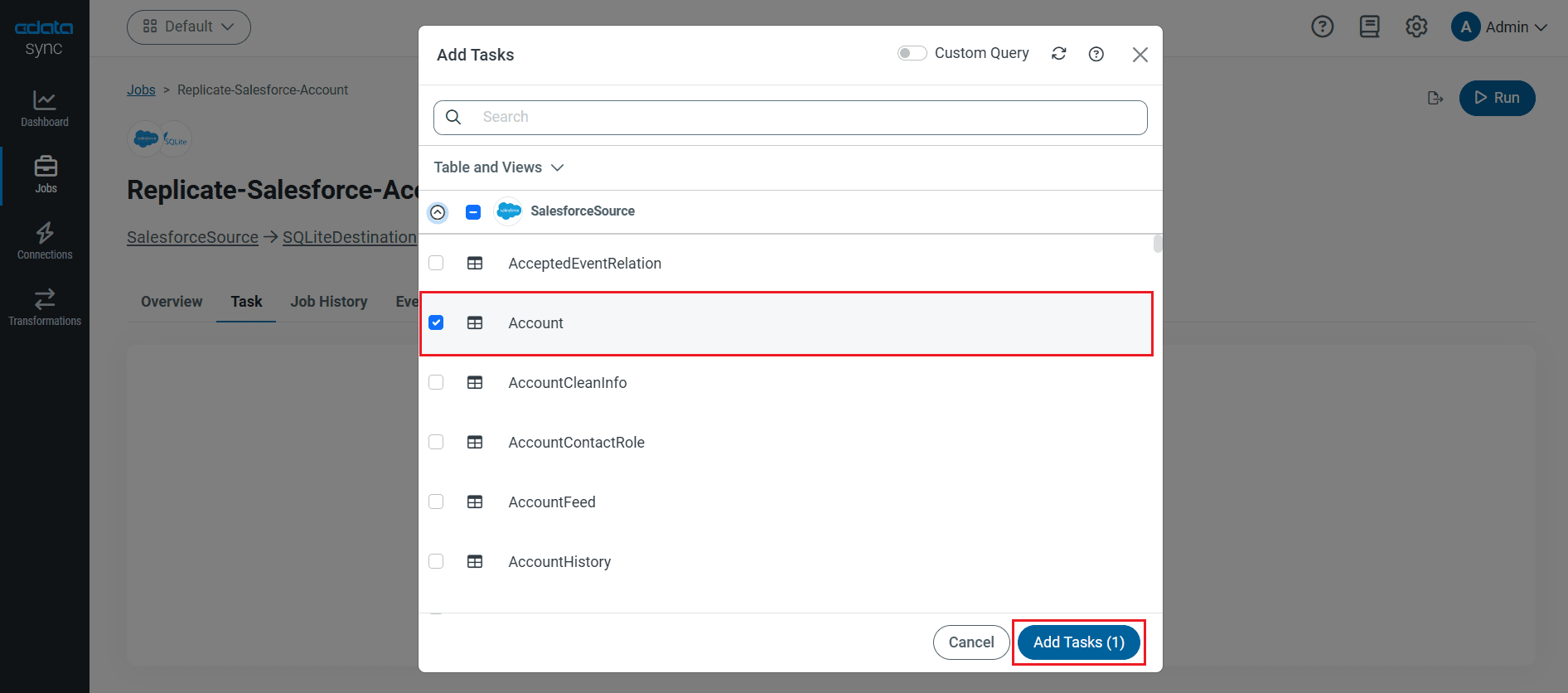
テーブル全体をレプリケーションする
テーブル全体をレプリケーションするには、[テーブル]セクションで[テーブルを追加]をクリックします。表示されたテーブルリストからレプリケーションするテーブルをチェックします。.
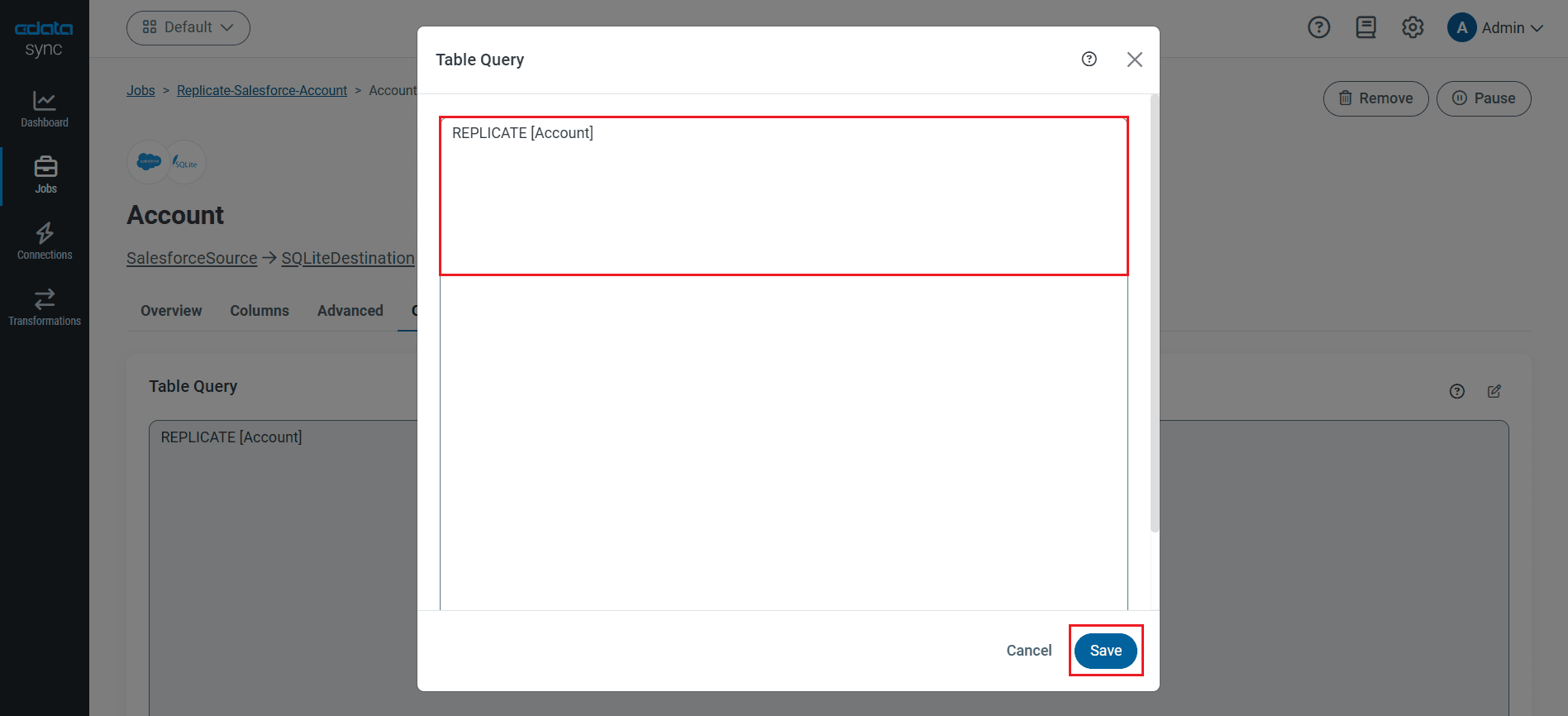
テーブルをカスタマイズしてレプリケーションする
SQL クエリを使って、レプリケーションをカスタマイズできます。REPLICATE 構文はデータベースのテーブルにデータをキャッシュし、保存するハイレベルコマンドです。RabbitMQ API がサポートするSELECT クエリを定義することができます。レプリケーションのカスタマイズにはテーブルセクションで[カスタムクエリの追加]をクリックして、クエリステートメントを記述します。
RabbitMQ のデータ のテーブルを差分更新でキャッシュするステートメントは次のとおり:
REPLICATE AuthAttempts;
使用するレプリケーションクエリを含むファイルを指定することで特定のデータベースを更新することが可能です。レプリケーションステートメントをセミコロンで区切ります。次のオプションは一つのデータベースに複数のRabbitMQ アカウントのデータを同期する例です:
-
REPLICATE SELECT ステートメントで異なるtable prefix を使用する:
REPLICATE PROD_AuthAttempts SELECT * FROM AuthAttempts;
-
別の方法として、異なるスキーマを使うことも可能です:
REPLICATE PROD.AuthAttempts SELECT * FROM AuthAttempts;
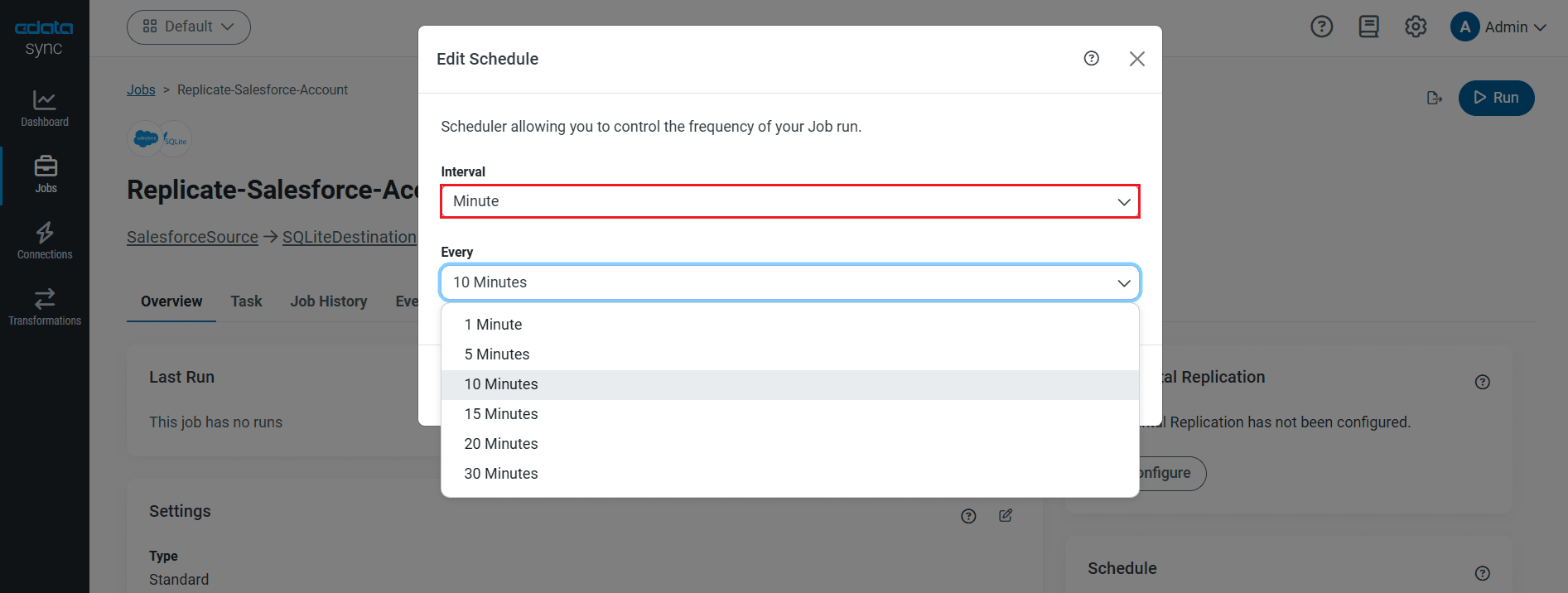
レプリケーションのスケジュール起動
[スケジュール]セクションでは、レプリケーションジョブの自動起動スケジュール設定が可能です。反復同期間隔は、15分おきから毎月1回までの間で設定が可能です。
レプリケーションジョブを設定したら、[変更を保存]します。このように複数のRabbitMQ アカウントのデータを複製するジョブを作成することができました。