




【ノーコード】MySQL HeatWave にRabbitMQ のデータを統合する方法

CData Sync は、数百のSaaS / DB のデータをMySQL HeatWave をはじめとする各種DB / データウェアハウスにノーコードで統合・レプリケーション(複製)が可能なETL / ELT ツールです。本記事では、RabbitMQ のデータをCData Sync を使ってOracle Cloud Infrastructure(OCI)上のMySQL HeatWave に統合するデータパイプラインを作っていきます。
CData Sync とは?

CData Sync は、レポーティング、アナリティクス、機械学習、AI などで使えるよう、社内のデータを一か所に統合して管理できるデータ基盤をノーコードで構築できるETL ツールで、以下の特徴を持っています。
- RabbitMQ をはじめとする400種類以上のSaaS / DB データに対応
- MySQL HeatWave など多くのレイクハウス、RDB、データレイク、データウェアハウスに同期可能
- 業務データのデータ分析基盤へのETL / ELT 機能に特化し、極限まで設定操作をシンプルに
- 主要なSaaS データの差分更新やCDC(Change Data Capture、変更データキャプチャ)のサポート
- フレキシブルなSQL / dbt 連携での取得データの変換
CData Sync では、1. データソースとしてRabbitMQ の接続を設定、2. 同期先としてMySQL HeatWave の接続を設定、3. RabbitMQ からMySQL HeatWave へのレプリケーションジョブの作成、という3つのステップだけでレプリケーション処理を作成可能です。以下に具体的な設定手順を説明します。
CData Sync をHeatWave に連携する二つの方法
CData Sync を使ってRabbitMQ をHeatWave に連携するには、以下の二つの方法があります。
- OCI 上のLinux インスタンスにCData Sync をインストールして、その環境からSync を操作する
- OCI 上のLinux インスタンスをSSH 踏み台サーバーとして活用して、OCI 以外の環境にインストールしたCData Sync を操作する
今回はより簡単にセットアップ可能な①の方法をご紹介しますが、自社の環境に応じて①と②、どちらの方法を採用するかご検討ください。②の方法でHeatWave と連携する場合は、こちらの記事を参考にしていただけます。
CData Sync は無償トライアルを提供していますので、以下からダウンロードしてお試しください。
無償トライアルへ事前準備
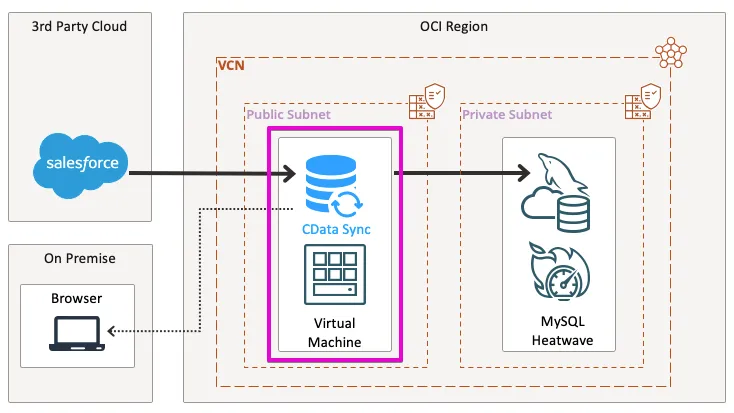
本手順では、Oracle Cloud Infrastructure(以下、OCI)上にMySQL HeatWave、およびCData Sync を用いたデータパイプラインを構築します。構成は以下のとおりです。
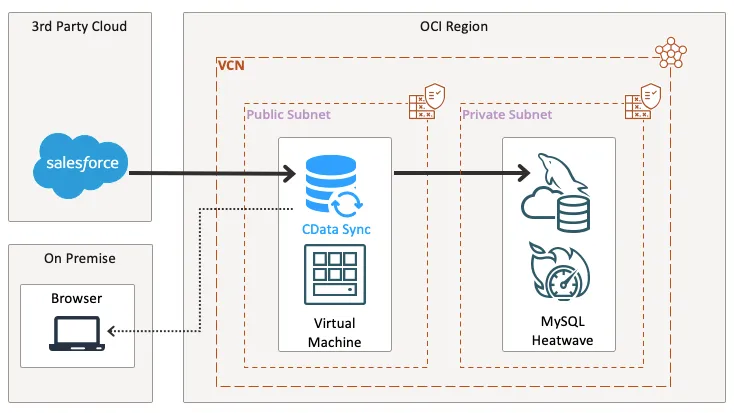
MySQL HeatWave のインスタンスについては、事前に作成しているものとして進めていきます。未作成の場合は、OCI の記事を参考に作成してみてください。
それでは、OCI に接続に使用するLinux インスタンスを作ってみましょう。
外部からのアクセスポートはssh 接続のみ許容していて、予めssh キーのキー・ペアを生成しておき、秘密キーをダウンロードしています。
また、Linux 上のCData Sync へのアクセスにはOCI 上の仮想ファイアウォール、およびOS 上のファイアウォールの設定が必要になります。設定には、スマートスタイル社のこちらの記事を参考にしていただけます。
次に、MySQL HeatWave に今回使用するテーブルを作成して、Linux インスタンスにCData Sync をインストールしていきます。
HeatWave インスタンスに今回使用するデータベースを作る
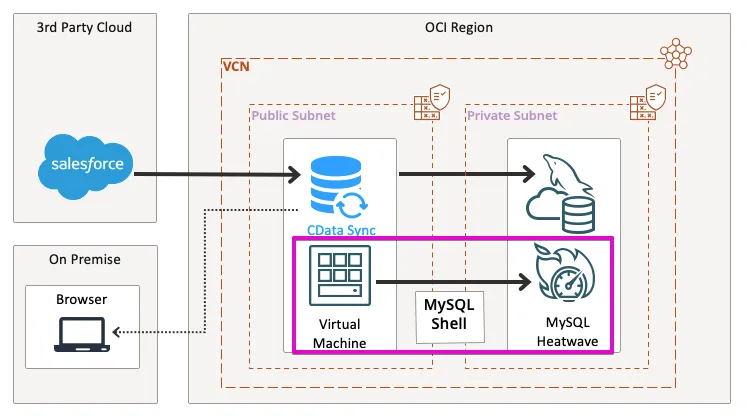
まずは、MySQL 上に今回RabbitMQ のデータを同期するテーブルを作っていきます。
最初に作成したLinux インスタンスに接続しましょう。各環境でのインスタンスへの接続方法はOCI の記事が参考になります。
yum install mysql などのコマンドでMySQL をインストールしたら、MySQL にHeatWave のプライベートIP アドレスを指定して接続します。
mysql -u root -p -h
接続出来たら、以下のコマンドでテーブルを作成しましょう(例としてsync を使用)。
mysql> CREATE DATABASE sync;
以下のコマンドを実行して、作成したテーブルが含まれていればOKです。
mysql> SHOW DATABASES;
Linux インスタンスにCData Sync をインストール
次に、クロスプラットフォーム版CData Sync をダウンロードして、Linux インスタンスにscp コマンドなどでコピーしておきましょう。
Sync はこちらのページから30日間無償トライアルがダウンロードできますので、お気軽にお試しください。
インスタンスにssh 接続してCData Sync をインストールしていきます。
コピーしておいたCDataSync.tar.gz ファイルをtar コマンドで任意のディレクトリに展開します。
tar -xvzf CDataSync.tar.gz -C CDataSync
それでは、CData Sync を起動してみましょう!
CData Sync をインストールしたディレクトリに移動したら以下のコマンドを実行して、Sync を起動します。
java -jar sync.jar
以下のメッセージが表示されていれば、起動は成功です。
INFO: Sync is now running. Please visit http://localhost:8181 to login.それでは、以下のアドレスにクライアントからアクセスして、Sync にアクセスしてみましょう。
http://<インスタンスのパブリックip アドレス>:8181以下のようなユーザー作成画面が表示されたら準備完了です!ユーザーを作成して、Sync にログインしてみましょう。
CData Sync のデータソースとしてRabbitMQ の接続を設定
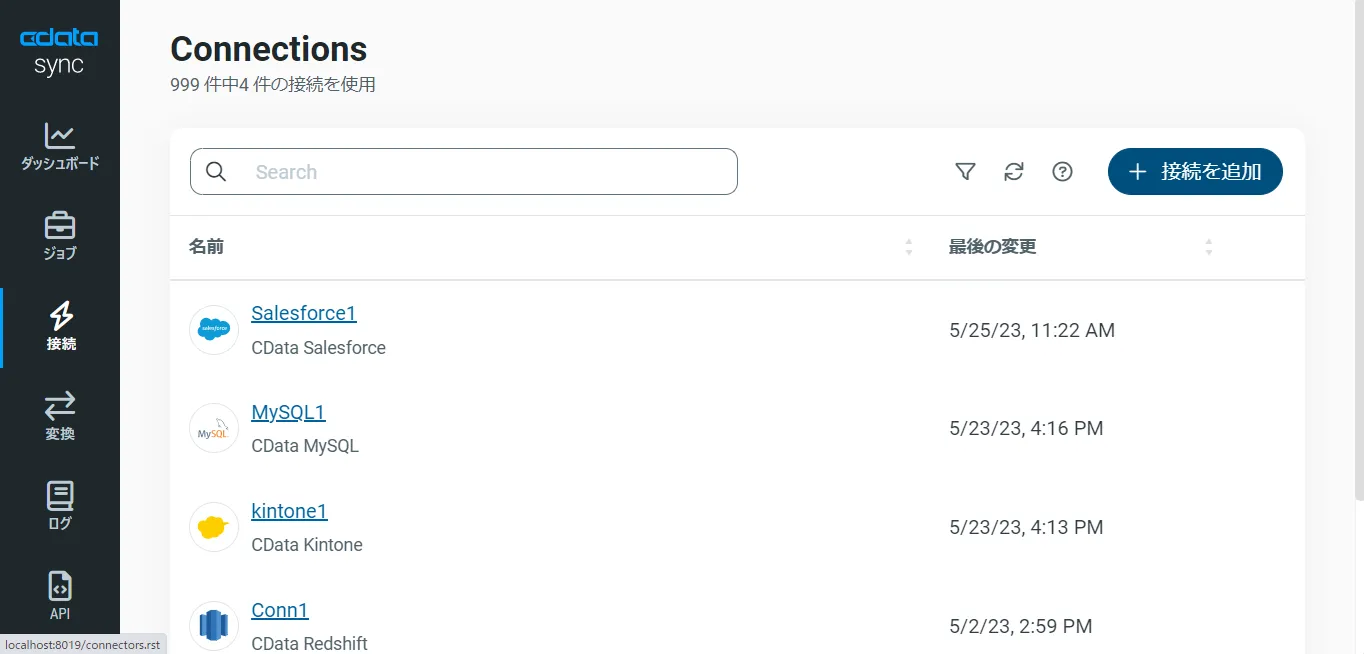
ユーザーを作成してCData Sync にログインしたら、データソースとしてRabbitMQ を設定していきましょう。左の[接続]タブをクリックします。
- [+接続の追加]ボタンをクリックします。
- [データソース]タブを選択して、リスト表示されるデータソースを選ぶか、検索バーにデータソース名を入力して、RabbitMQ を見つけます。
- RabbitMQ の右側の[→]をクリックして、RabbitMQ アカウントへの接続画面を開きます。もし、RabbitMQ のコネクタがデフォルトでCData Sync にインストールされていない場合には、ダウンロードアイコン(コネクタのアップロードアイコン)をクリックし、[ダウンロード]をクリックすると、CData Sync にコネクタがインストールされます。
- 接続プロパティにRabbitMQ に接続するアカウント情報を入力をします。
RabbitMQ Management HTTP API について
RabbitMQ は、複数のメッセージングプロトコルをサポートするオープンソースのメッセージブローカーです。RabbitMQ Management HTTP API は、RabbitMQ サーバーの管理データと監視データに HTTP 経由でアクセスする手段を提供します。この API では、仮想ホスト、エクスチェンジ、キュー、バインディング、コネクション、チャネル、コンシューマー、ユーザー、権限、ポリシー、クラスター全体の統計情報を取得できます。
HTTP API を利用するには、RabbitMQ サーバーで Management プラグインを有効化する必要があります。デフォルトでは、管理インターフェースはポート 15672 でリッスンします。
Basic 認証の設定
RabbitMQ Management HTTP API は HTTP Basic 認証を使用します。RabbitMQ 管理ユーザーのユーザー名とパスワードを指定する必要があります。
管理 API へのアクセスを有効にするには、以下のステップで進めます:
- サーバーで RabbitMQ Management プラグインが有効になっていることを確認します(rabbitmq-plugins enable rabbitmq_management)。
- 既存の管理ユーザーを使用するか、適切な管理タグ(management、policymaker、monitoring、または administrator)を持つユーザーを作成します。
- RabbitMQ Management HTTP API の完全なベース URL を控えておきます(例:http://localhost:15672)。
RabbitMQ サーバーを設定したら、以下の接続プロパティを設定して接続します:
- AuthScheme:Basic に設定します。
- URL:RabbitMQ Management HTTP API のベース URL に設定します(例:http://localhost:15672)。
- User:RabbitMQ の管理ユーザー名に設定します(例:guest)。
- Password:RabbitMQ の管理パスワードに設定します。
接続文字列の例:
Profile=C:\profiles\RabbitMQ.apip;AuthScheme=Basic;URL=http://localhost:15672;User=guest;Password=guest;
利用可能なテーブル
RabbitMQ プロファイルでは、以下のテーブルにアクセスできます:
- Overview - クラスター全体の統計情報と RabbitMQ ノードに関する情報
- Nodes - RabbitMQ クラスター内の個々のノードに関する情報
- NodeMemory - 特定のクラスターノードの詳細なメモリ使用状況の内訳
- Connections - ブローカーへのすべてのオープンな AMQP コネクションの一覧
- Channels - すべてのコネクションにわたるオープンな AMQP チャネルの一覧
- Consumers - すべてのキューに登録されたコンシューマーの一覧
- Exchanges - すべての仮想ホストで宣言されたエクスチェンジの一覧
- Queues - すべての仮想ホストで宣言されたキューの一覧
- Bindings - エクスチェンジとキュー間のすべてのバインディングの一覧
- VirtualHosts - ブローカーに設定された仮想ホストの一覧
- VhostPermissions - 特定の仮想ホスト内のユーザー権限
- Users - すべての RabbitMQ ユーザーの一覧
- Permissions - すべての仮想ホストにわたる全ユーザーの権限レコード
- TopicPermissions - 全ユーザーのトピックレベルの権限レコード
- Policies - 仮想ホスト内のキューおよびエクスチェンジに適用されたポリシーの一覧
- OperatorPolicies - 仮想ホスト内のキューに適用されたオペレーターポリシーの一覧
- Parameters - 仮想ホストごとのコンポーネントパラメータ(例:federation、shovel)の一覧
- GlobalParameters - すべての仮想ホストに適用されるグローバルパラメータの一覧
- VhostLimits - 特定の仮想ホストに設定されたリソース制限
- UserLimits - 特定のユーザーに設定されたリソース制限
- FeatureFlags - フィーチャーフラグの一覧と、ノード上での有効/無効の状態
- DeprecatedFeatures - 非推奨機能の一覧と、その使用状態
- AuthAttempts - ノードの認証試行統計
- ClusterName - RabbitMQ クラスターの名前
- WhoAmI - 現在認証されている管理ユーザーに関する情報
- ExchangeBindingsSource - 特定のエクスチェンジがソースとなっているバインディング
- ExchangeBindingsDestination - 特定のエクスチェンジが宛先となっているバインディング
- QueueBindings - 仮想ホスト内の特定のキューのバインディング
- [作成およびテスト]をクリックして、正しくRabbitMQ に接続できているかをテストして保存します。これでレプリケーションのデータソースとしてRabbitMQ への接続が設定されました。
同期先としてMySQL HeatWave の接続を設定
次に、RabbitMQ のデータを書き込む先(=同期先)として、MySQL HeatWave を設定します。同じく[接続]タブを開きましょう。
- [+接続の追加]ボタンをクリックします。
- [同期先]タブを選択して、リスト表示されるデータソースを選ぶか、検索バーにデータソース名を入力して、「MySQL」を見つけます。今回接続するのはMySQL HeatWave ですが、Sync での接続ではMySQL を使用してOKです。
- MySQL の右側の[→]をクリックして、MySQL HeatWave データベースへの接続画面を開きます。
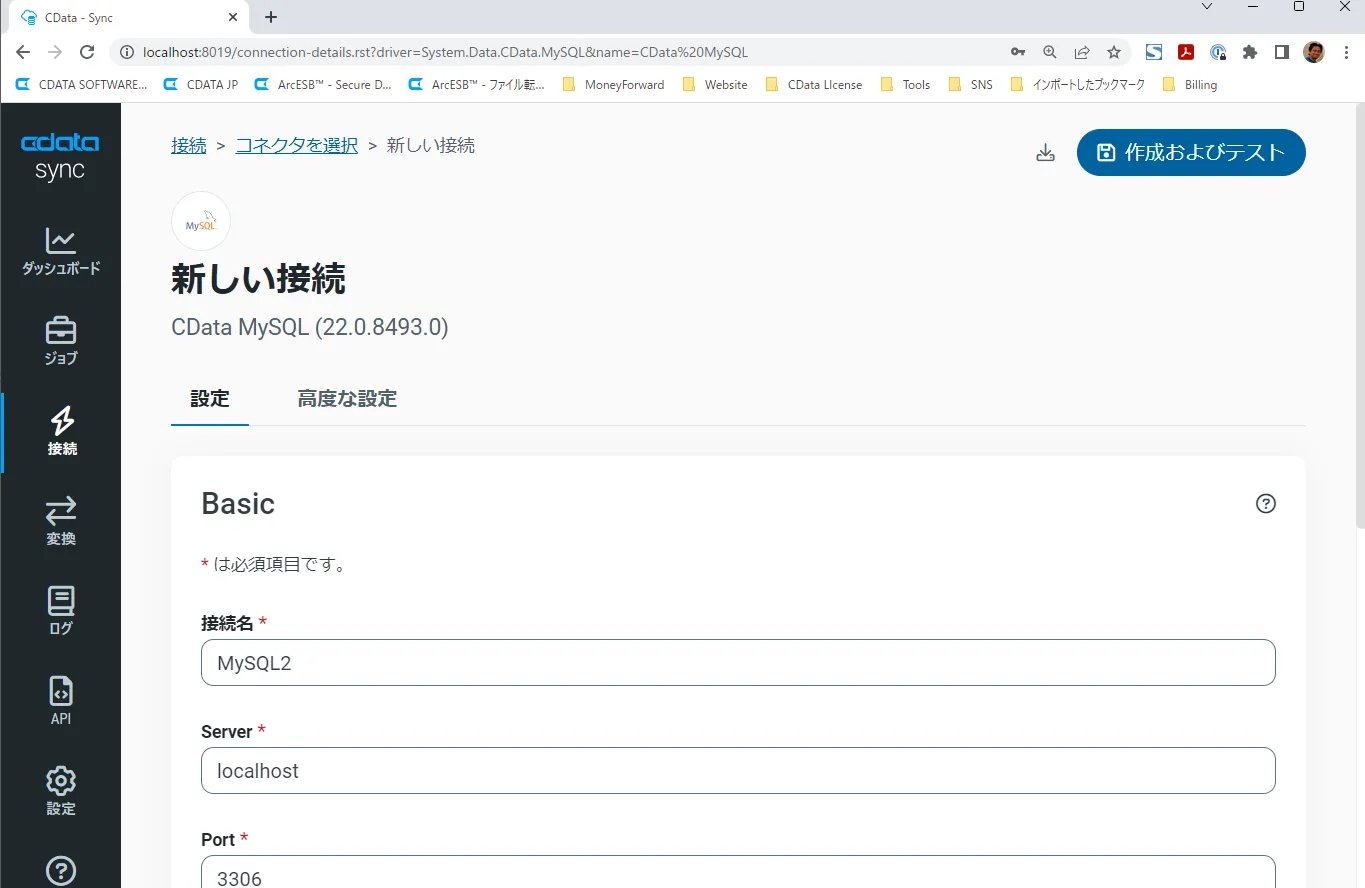
- 必要な接続プロパティを入力します。MySQL HeatWave との接続には、以下のプロパティが必要です:
- Server: HeatWave のプライベートIP アドレス。
- Port: サーバーのポート。デフォルトは3306
- User: HeatWave 構成時に設定したユーザー名。
- Password: HeatWave 構成時に設定したパスワード。
- Database: 同期先のデータベース名(本記事ではsync を使用)。
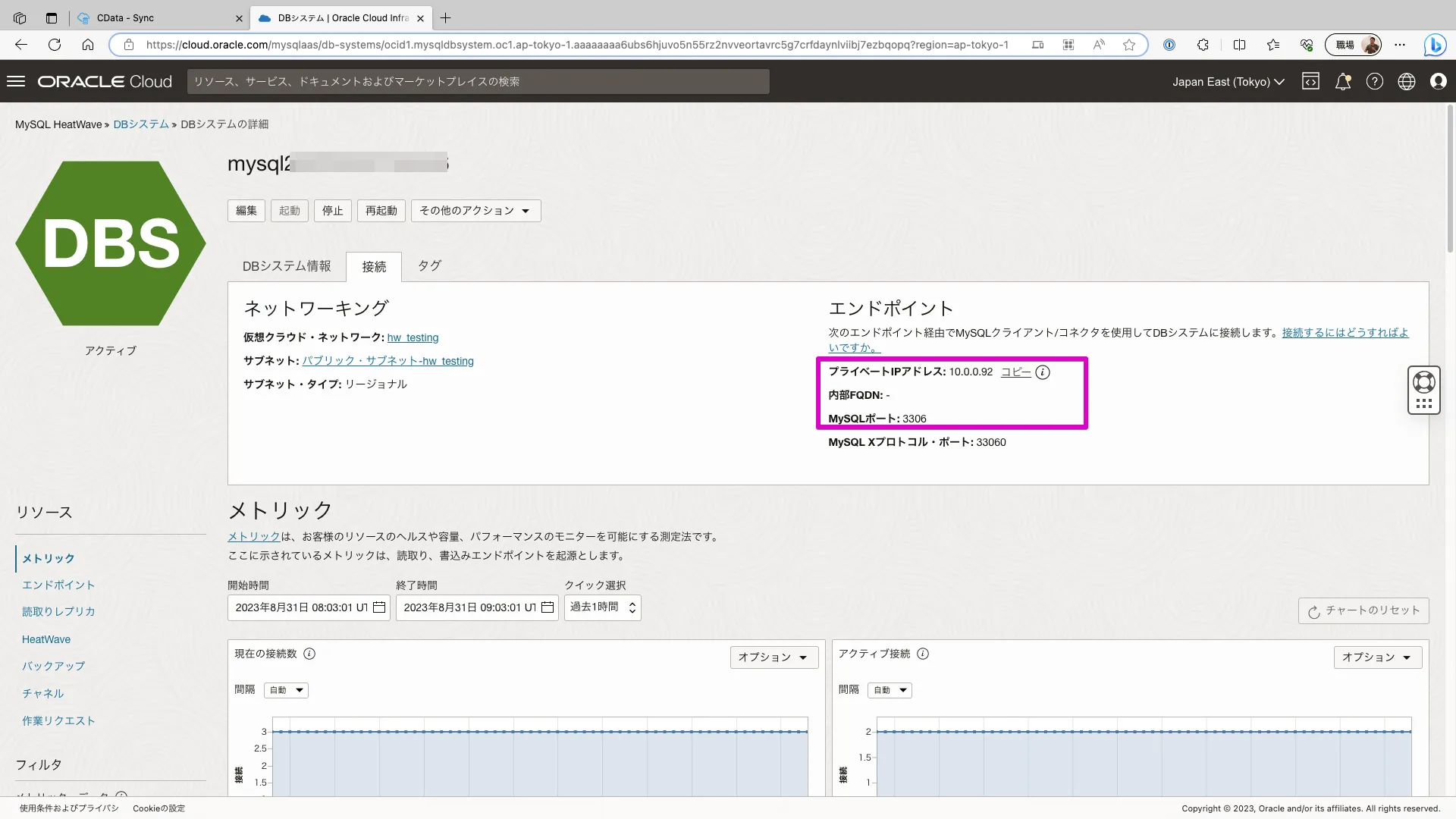
プライベートIPアドレスとポートについてはMySQL Heatwaveの接続タブから確認できます。
- [作成およびテスト]をクリックして、正しく接続できているかをテストします。
- これで同期先としてMySQL HeatWave を設定できました。CData Sync では、MySQL HeatWave のデータベース名を指定するだけで、同期するRabbitMQ に併せたテーブルスキーマを自動的にCREATE TABLE してくれます。同期データに合わせたテーブルを事前に作成するなどの面倒な手順は必要ありません。もちろん、既存テーブルにマッピングを行いデータ同期を行うことも可能です。
RabbitMQ からMySQL HeatWave へのレプリケーションジョブの作成
CData Sync では、レプリケーションをジョブ単位で設定します。ジョブは、RabbitMQ からMySQL という単位で設定し、複数のテーブルを含むことができます。レプリケーションジョブ設定には、[ジョブ]タブに進み、[+ジョブを追加]ボタンをクリックします。
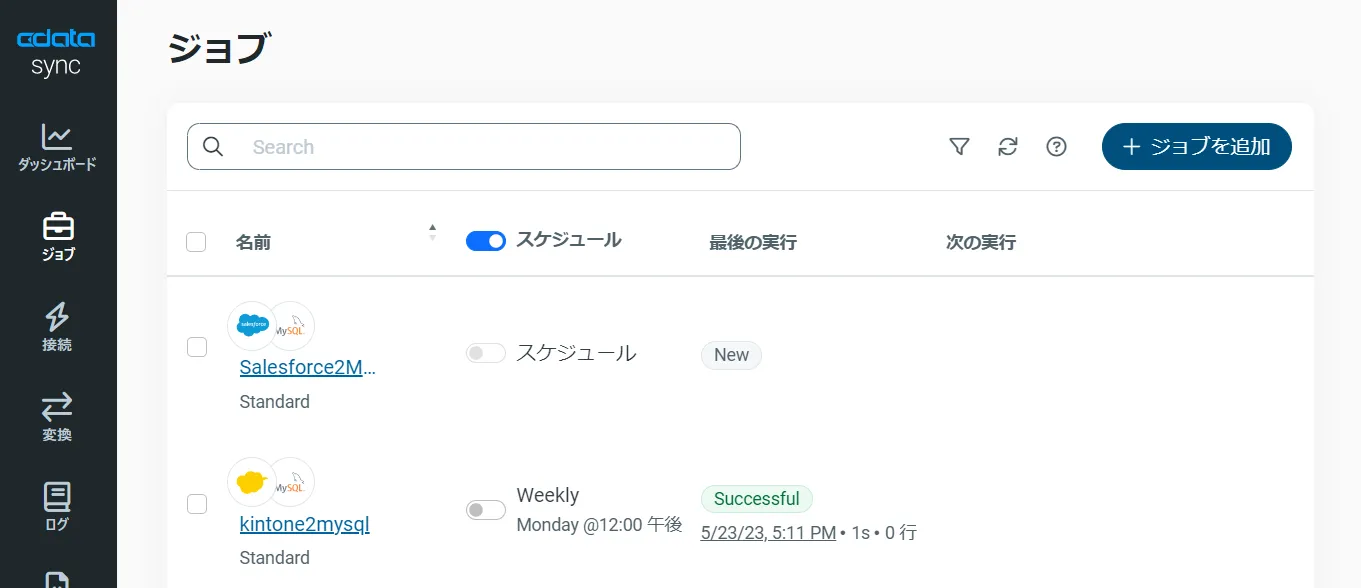
[ジョブを追加]画面が開き、以下を入力します。
- 名前:ジョブの名前
- データソース:ドロップダウンリストから先に設定したRabbitMQ を選択
- 同期先:先に設定したMySQL を選択
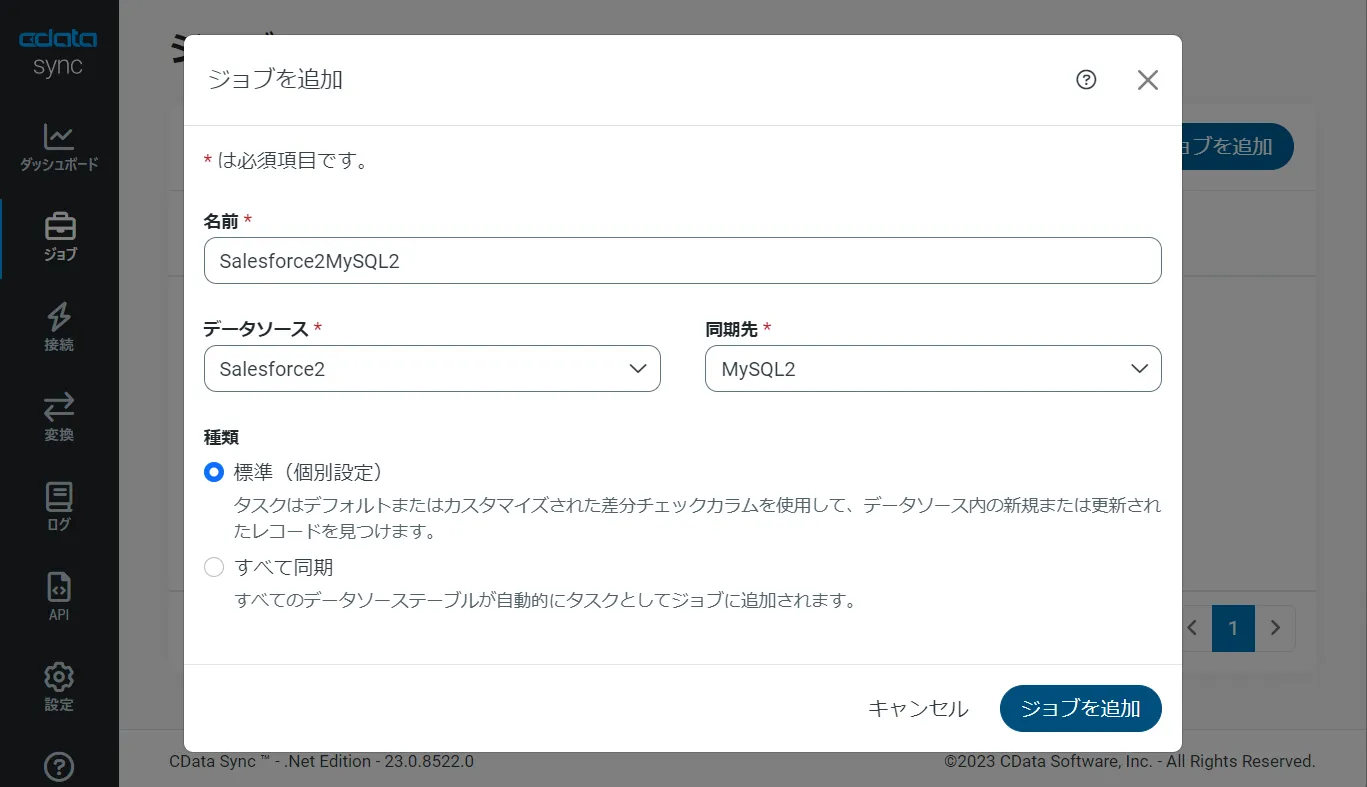
すべてのオブジェクトをレプリケーションする場合
RabbitMQ のすべてのオブジェクト / テーブルをレプリケーションするには、[種類]セクションで[すべて同期]を選択して、[タスクを追加]ボタンで確定します。
作成したジョブ画面で、右上の[▷実行]ボタンをクリックするだけで、全RabbitMQ テーブルのMySQL HeatWave への同期を行うことができます。
オブジェクトを選択してレプリケーションする場合
RabbitMQ から特定のオブジェクト / テーブルを選択してレプリケーションを行うことが可能です。[種類]セクションでは、[標準(個別設定)]を選んでください。
次に[ジョブ]画面で、[タスク]タブをクリックし、[タスクを追加]ボタンをクリックします。 
するとCData Sync で利用可能なオブジェクト / テーブルのリストが表示されるので、レプリケーションを行うオブジェクトにチェックを付けます(複数選択可)。[タスクを追加]ボタンで確定します。
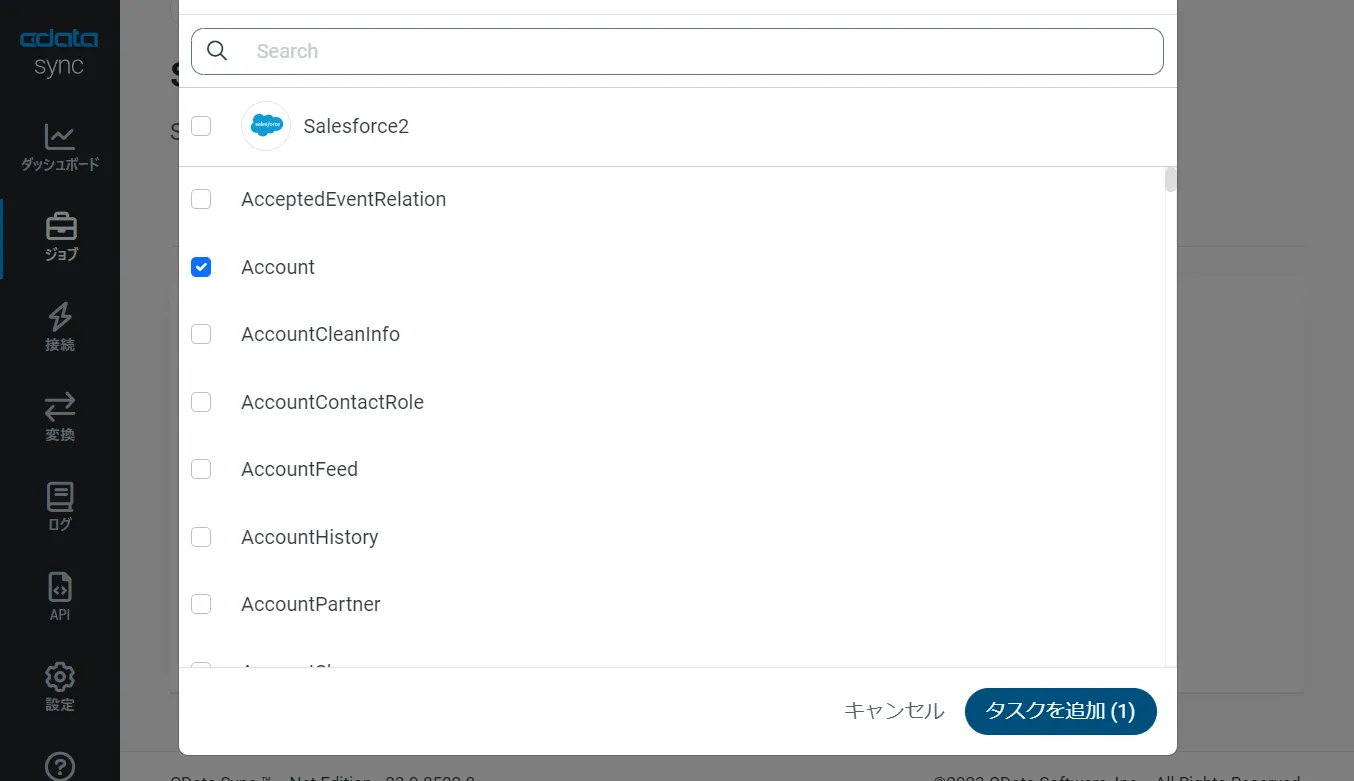
作成したジョブ画面で、[▷実行]ボタンをクリックして(もしくは各タスク毎の実行ボタンを押して)、レプリケーションジョブを実行します。 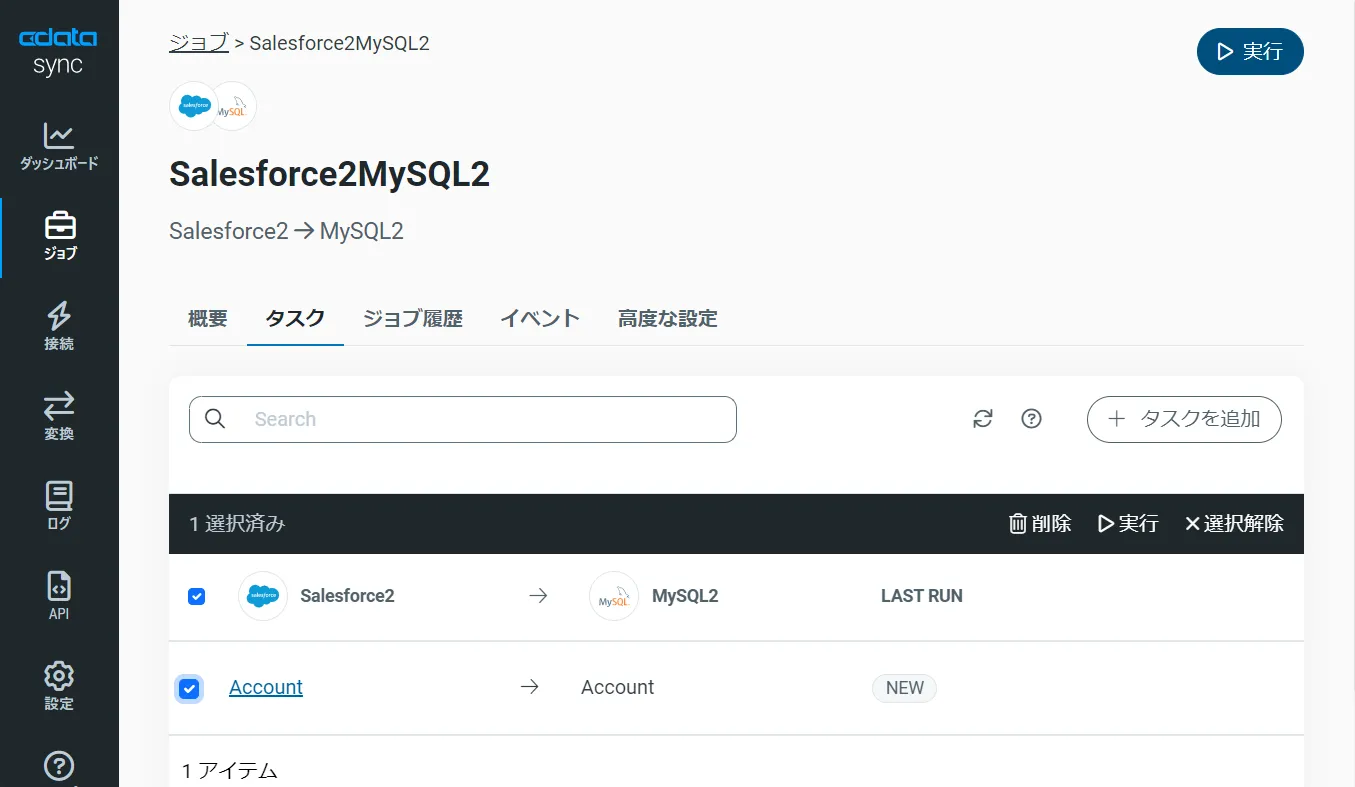
それでは、実際にHeatWave にRabbitMQ のデータが同期されているかどうか、OCI インスタンス上のMySQL Shell で確認してみましょう。
mysql> USE sync;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+----------------+
| Tables_in_sync |
+----------------+
| AuthAttempts |
+----------------+
1 rows in set (0.00 sec)
AuthAttempts が同期されていますね!このように、とても簡単にRabbitMQ からMySQL HeatWave への同期を行うことができました。
CData Sync の主要な機能を試してみる:スケジューリング・差分更新・ETL
ジョブのスケジュール起動設定
CData Sync では、同期ジョブを1日に1回や15分に1回などのスケジュール起動をすることができます。ジョブ画面の[概要]タブから[スケジュール]パネルを選び、[⚙設定]ボタンをクリックします。[間隔]と同期時間の[毎時何分]を設定し、[保存]を押して設定を完了します。これでCData Sync が同期ジョブをスケジュール実行してくれます。ユーザーはダッシュボードで同期ジョブの状態をチェックするだけです。 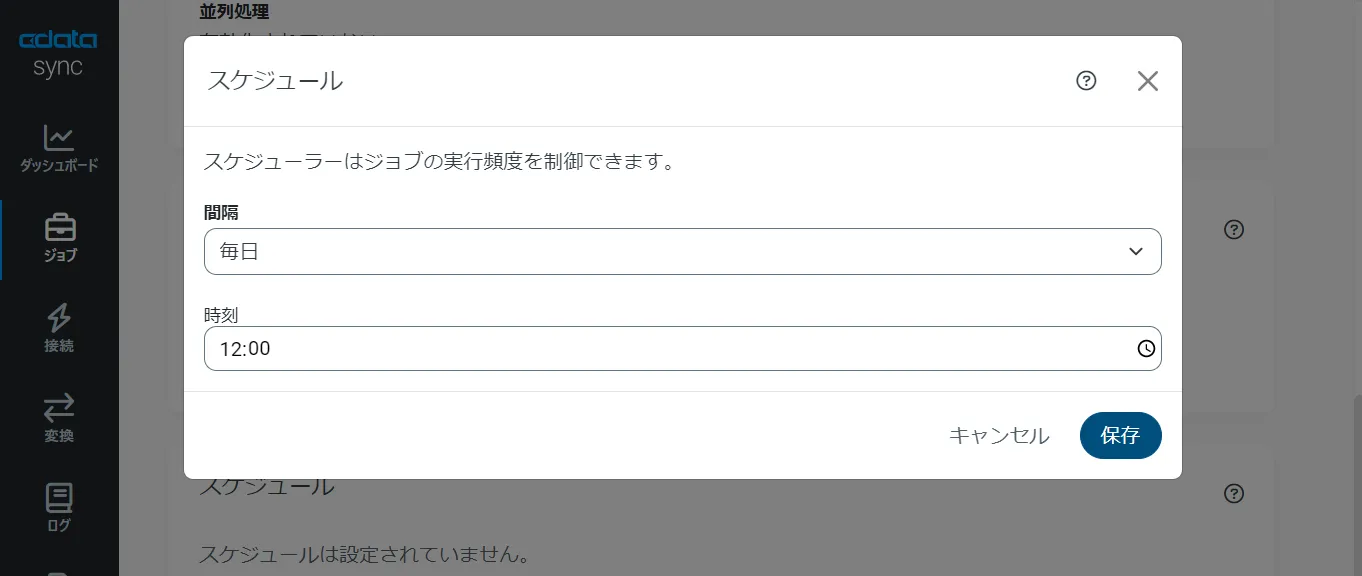
差分更新
CData Sync では、主要なデータソースでは、差分更新が可能です。差分更新では、最後のジョブ実行時からデータソース側でデータの追加・変更があったデータだけを同期するので、レプリケーションのクエリ・通信のコストを圧倒的に抑えることが可能です。
差分更新を有効化するには、ジョブの[概要]タブから「差分更新」パネルを選び、[⚙設定]ボタンをクリックします。[開始日]と[レプリケーション間隔]を設定して、[保存]します。
SQL での取得データのカスタマイズ
CData Sync は、デフォルトではRabbitMQ のオブジェクト / テーブルをそのままMySQL HeatWave に複製しますが、ここにSQL、またはdbt 連携でのETL 処理を組み込むことができます。テーブルカラムが多すぎる場合や、データ管理の観点から一部のカラムだけをレプリケーションしたり、さらにデータの絞り込み(フィルタリング)をしたデータだけをレプリケーションすることが可能です。
ジョブの[概要]タブ、[タスク]タブへと進みます。選択されたタスク(テーブル)の[▶]の左側のメニューをクリックし、[編集]を選びます。タスクの編集画面が開きます。
UI からカラムを選択する場合には、[カラム]タブから[マッピング編集]をクリックします。レプリケーションで使用しないカラムからチェックを外します。
SQL を記述して、フィルタリングなどのカスタマイズを行うには、[クエリ]タブをクリックし、REPLICATE [テーブル名]の後に標準SQL でフィルタリングを行います。
RabbitMQ からMySQL HeatWave へのデータ同期には、ぜひCData Sync をご利用ください
このようにノーコードで簡単にRabbitMQ のデータをMySQL HeatWave にレプリケーションできます。データ分析、AI やノーコードツールからのデータ利用などさまざまな用途でCData Sync をご利用いただけます。30日の無償トライアルで、シンプルでパワフルなデータパイプラインを体感してください。
日本のユーザー向けにCData Sync は、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。
CData Sync の 導入事例を併せてご覧ください。