





AWS Lambda でリアルタイムSharePoint のデータにアクセス(IntelliJ IDEA を使用)

AWS Lambda は、新しい情報やイベントに素早く応答するアプリケーションを構築できるコンピューティングサービスです。CData JDBC Driver for SharePoint と組み合わせることで、AWS Lambda 関数からリアルタイムSharePoint のデータを操作できます。この記事では、IntelliJ で Maven を使用して AWS Lambda 関数を構築し、SharePoint のデータに接続してクエリを実行する方法を説明します。
最適化されたデータ処理機能を組み込んだ CData JDBC ドライバは、リアルタイムSharePoint のデータとのインタラクションにおいて卓越したパフォーマンスを発揮します。SharePoint に対して複雑な SQL クエリを発行すると、ドライバーはフィルタや集計などのサポートされている SQL 操作を直接SharePointにプッシュし、サポートされていない操作(主に SQL 関数や JOIN 操作)は組み込みの SQL エンジンを使用してクライアント側で処理します。さらに、動的メタデータクエリ機能により、ネイティブのデータ型を使用してSharePoint のデータの操作・分析が可能です。
SharePoint データ連携について
CData を使用すれば、SharePoint のライブデータへのアクセスと統合がこれまでになく簡単になります。お客様は CData の接続機能を以下の目的で利用しています:
- Windows SharePoint Services 3.0、Microsoft Office SharePoint Server 2007 以降、SharePoint Online を含む、幅広い SharePoint バージョンのデータにアクセスできます。
- 非表示カラムとルックアップカラムのサポートにより、SharePoint のすべてにアクセスできます。
- フォルダを再帰的にスキャンして、すべての SharePoint データのリレーショナルモデルを作成できます。
- SQL ストアドプロシージャを使用して、ドキュメントや添付ファイルをアップロード・ダウンロードできます。
多くのお客様は、SharePoint データをデータベースやデータウェアハウスに統合するために CData ソリューションを活用していますが、Power BI、Tableau、Excel などのお気に入りのデータツールと SharePoint データを統合しているお客様もいます。
お客様が CData の SharePoint ソリューションで問題を解決している方法については、ブログをご覧ください:Drivers in Focus: Collaboration Tools
はじめに
ステップ1:接続プロパティの設定と接続文字列の構築
CData JDBC Driver for SharePoint のインストーラーをダウンロードし、パッケージを解凍して JAR ファイルを実行してドライバーをインストールします。次に、必要な接続プロパティを収集します。
Microsoft SharePoint への接続
URL の設定:
Microsoft SharePoint では、2つの範囲でデータを操作できます。グローバルなMicrosoft SharePoint サイト全体を対象にするか、個々のサイトのみを対象にするかを選択できます。
グローバルなMicrosoft SharePoint サイトですべてのリストおよびドキュメントを操作したい場合は、URL 接続プロパティをサイトコレクションURL に設定しましょう。以下のような形式です。
https://teams.contoso.com
個々のサイトのリストおよびドキュメントのみを扱いたい場合は、URL 接続プロパティを個々のサイトURL に設定してください。以下のような形式です。
https://teams.contoso.com/TeamA
続いて、お使いの環境に適した認証プロパティを設定していきましょう。詳細な設定手順については、 href="/kb/help/" target="_blank">ヘルプドキュメントの「はじめに」をご参照ください。
Microsoft SharePoint Online
SharePointEdition を"SharePoint Online" に設定し、User およびPassword にはSharePoint へのログオンで使用するクレデンシャル(例:Microsoft Online Services アカウントのクレデンシャル)を設定します。
Microsoft SharePoint Online は様々なクラウドベースアーキテクチャをサポートしており、それぞれ異なる認証スキームが利用できます。
- Microsoft Entra ID(Azure AD)
- ADFS、Okta、OneLogin、またはPingFederate SSO ID プロバイダーを介したシングルサインオン(SSO)
- Azure MSI
- Azure パスワード
- OAuthJWT
- SharePointOAuth
Microsoft SharePoint オンプレミス
Microsoft SharePoint オンプレミスでは、多くのオンプレミス環境に対応した認証方式をサポートしています。
- Windows(NTLM)
- Kerberos
- ADFS
- 匿名アクセス
まずSharePointEdition を"SharePoint On-Premises" に設定しましょう。
Windows(NTLM)認証
これは最も一般的な認証方式です。そのため、CData 製品ではNTLM をデフォルトとして使用するよう事前設定されています。Windows のUser およびPassword を設定するだけで接続できます。
NOTE: AWS Lambda 関数で JDBC ドライバーを使用するには、ライセンス(製品版または試用版)とランタイムキー(RTK)が必要です。ライセンス(または試用版)の取得については、弊社営業チームまでお問い合わせください。
組み込みの接続文字列デザイナー
JDBC URL の構築には、SharePoint JDBC Driver に組み込まれている接続文字列デザイナーを使用できます。JAR ファイルをダブルクリックするか、コマンドラインから JAR ファイルを実行してください。
java -jar cdata.jdbc.sharepoint.jar
")
接続プロパティ(RTK を含む)を入力し、接続文字列をクリップボードにコピーします。
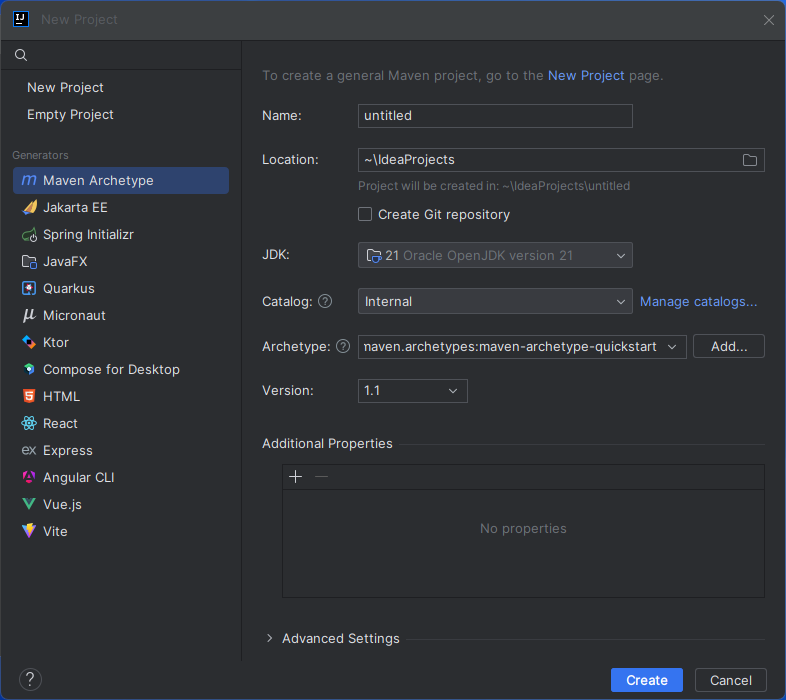
ステップ2:IntelliJ でプロジェクトを作成
- IntelliJ IDEA で「New Project」をクリックします。
- Generators から「Maven Archetype」を選択します。
- プロジェクトに名前を付け、Archetype として「maven.archetypes:maven-archetype-quickstart」を選択します。
- 「Create」をクリックします。
CData JDBC Driver for SharePoint JAR ファイルのインストール
プロジェクトのルートフォルダから以下の Maven コマンドを実行して、JAR ファイルをプロジェクトにインストールします。
mvn install:install-file -Dfile="PATH/TO/CData JDBC Driver for SharePoint 20XX/lib/cdata.jdbc.sharepoint.jar" -DgroupId="org.cdata.connectors" -DartifactId="cdata-sharepoint-connector" -Dversion="23" -Dpackaging=jar
依存関係の追加
Maven プロジェクトの pom.xml ファイル内で、AWS とCData JDBC Driver for SharePointを依存関係として追加します(<dependencies> 要素内に以下の XML を追加)。
- AWS
<dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-lambda-java-core</artifactId> <version>1.2.2</version> <!--Replace with the actual version--> </dependency>
- CData JDBC Driver for SharePoint
<dependency> <groupId>org.cdata.connectors</groupId> <artifactId>cdata-sharepoint-connector</artifactId> <version>25</version> <!--Replace with the actual version--> </dependency>
- Fat JAR 作成用の Maven Shade Plugin
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.4.1</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <createDependencyReducedPom>false</createDependencyReducedPom> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>com.example.CDataLambda</mainClass> <!-- Change to your actual Lambda handler class --> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> </build>
AWS Lambda 関数の作成
このサンプルプロジェクトでは、CDataLambda.java と CDataLambdaTest.java の2つのソースファイルを作成します。
Lambda 関数の定義
- CDataLambda クラスを AWS Lambda SDK の RequestHandler インターフェースを実装するように更新します。handleRequest メソッドを追加する必要があります。このメソッドは、Lambda 関数がトリガーされたときに以下のタスクを実行します:
- 入力を使用して SQL クエリを構築
- CData JDBC Driver for SharePoint を登録
- JDBC を使用してSharePointへの接続を確立
- SharePoint で SQL クエリを実行
- 結果をコンソールに出力
- 出力メッセージを返す
-
以下の完全な Lambda クラスを使用してください。インポート、クラス定義、handleRequest メソッドが含まれています。DriverManager.getConnection 呼び出し内の接続文字列値は、実際の値に置き換えてください。
package com.example; import com.amazonaws.services.lambda.runtime.Context; import com.amazonaws.services.lambda.runtime.RequestHandler; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.ResultSetMetaData; import java.sql.SQLException; import java.sql.Statement; public class CDataLambda implements RequestHandler < Object, String > { @Override public String handleRequest(Object input, Context context) { String query = "SELECT * FROM " + input; String bucketName = "MY_AWS_BUCKET"; try { Class.forName("cdata.jdbc.sharepoint.SharePointDriver"); cdata.jdbc.sharepoint.SharePointDriver driver = new cdata.jdbc.sharepoint.SharePointDriver(); DriverManager.registerDriver(driver); } catch (SQLException ex) { // Registering the driver failed throw new RuntimeException("Failed to register JDBC driver", ex); } catch (ClassNotFoundException e) { // The driver class was not found in the classpath throw new RuntimeException("JDBC Driver class not found", e); } Connection connection = null; try { connection = DriverManager.getConnection("jdbc:cdata:sharepoint:RTK=52465...;User=myuseraccount;Password=mypassword;Auth Scheme=NTLM;URL=http://sharepointserver/mysite;SharePointEdition=SharePointOnPremise;"); } catch (SQLException ex) { context.getLogger().log("Error getting connection: " + ex.getMessage()); } catch (Exception ex) { context.getLogger().log("Error: " + ex.getMessage()); } if (connection != null) { context.getLogger().log("Connected Successfully! "); } ResultSet resultSet = null; try { //executing query Statement stmt = connection.createStatement(); resultSet = stmt.executeQuery(query); ResultSetMetaData metaData = resultSet.getMetaData(); int numCols = metaData.getColumnCount(); //printing the results while (resultSet.next()) { for (int i = 1; i <= numCols; i++) { System.out.printf("%-25s", (resultSet.getObject(i) != null) ? resultSet.getObject(i).toString().replaceAll(" ", "") : null); } System.out.print(" "); } } catch (SQLException ex) { System.out.println("SQL Exception: " + ex.getMessage()); } catch (Exception ex) { System.out.println("General exception: " + ex.getMessage()); } return "v24 query: " + query + " complete"; } }
ステップ3:Lambda 関数のデプロイと実行
IntelliJ で関数をビルドしたら、Maven プロジェクト全体を単一の JAR ファイルとしてデプロイする準備が整います。
- IntelliJ で mvn install コマンドを使用して SNAPSHOT JAR ファイルをビルドします。
Note: Maven Shade Plugin は target フォルダに2つの JAR を生成します。AWS Lambda には常に、すべての必要な依存関係を含むサイズの大きい -shaded.jar ファイルをアップロードしてください。
- AWS Lambda で新しい関数を作成します(または既存の関数を開きます)。
- 関数に名前を付け、IAM ロールを選択し、タイムアウト値を関数が完了するのに十分な値に設定します(クエリの結果サイズによって異なります)。
- 「Upload from」->「.zip file」をクリックし、SNAPSHOT JAR ファイルを選択します。

- 「Runtime settings」セクションで「Edit」をクリックし、Handler を handleRequest メソッドに設定します(例:package.class::handleRequest)。

- これで関数をテストできます。「Event JSON」フィールドにテーブル名を設定し、「Test」をクリックします。

無償トライアル・詳細情報
CData JDBC Driver for SharePoint の30日間の無償トライアルをダウンロードして、AWS Lambda でリアルタイムSharePoint のデータを活用してみてください。ご不明な点があれば、サポートチームまでお気軽にお問い合わせください。
はじめる準備はできましたか?
SharePoint Driver の無料トライアルをダウンロードしてお試しください:
ダウンロード詳細:
Java 開発者は、Web、デスクトップ、およびモバイルアプリケーションをSharePoint Server のリスト、連絡先、カレンダー、リンク、タスクなどのデータに簡単に接続できるようになります。