




RPA ツールBizRobo! でRabbitMQ に連携したフローを作成する

BizRobo! はRPAテクノロジーズ株式会社が提供する低コストかつスモールスタートで利用できるRPA ツールです。
この記事では、BizRobo! に備わっているJDBC インターフェースと CData JDBC Driver for API を組み合わせることによりBizRobo! でRabbitMQ
データを活用した自動化フローを作成する方法を紹介します。
BizRobo! 環境の構成
はじめるにあたりBizRobo! 側の環境を用意しておきます。
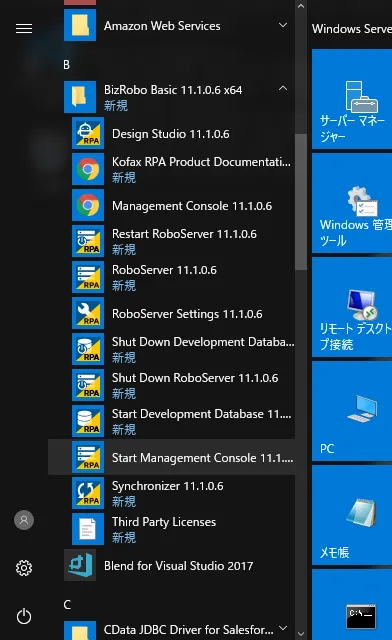
- 今回は検証にあたって、BizRobo! Basic を利用しました。JDBC Driver のアップロードに「BizRobo! Management Console」を利用するためです。
- 「BizRobo! Management Console」にアクセスするために、あらかじめBizRobo! Basic がインストールされたサーバー上で「Start Management Console」を実行しておきましょう。
CData JDBC Driver for API のインストール
続いてCData JDBC Driver for API をBizRobo! と同じマシンにインストールします。
-
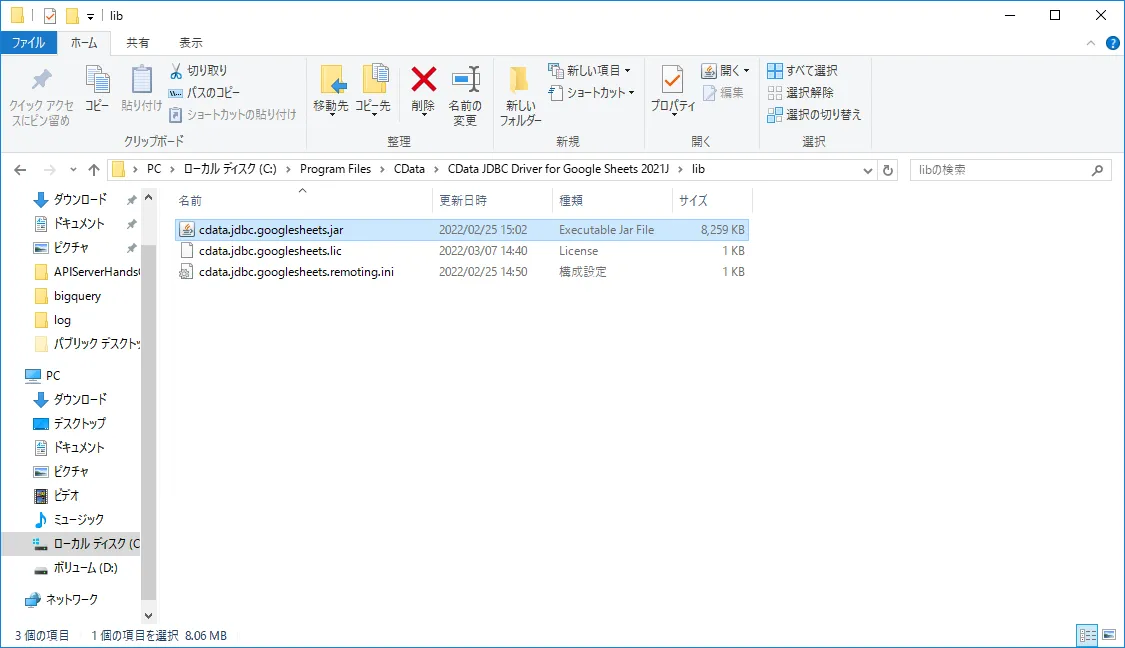
以下のパスにJDBC Driver がインストールされます。
C:\Program Files\CData\CData JDBC Driver for API 20xxJ\lib\cdata.jdbc.api.jar
- 続いて、接続用の文字列を取得するために、CData JDBC Driverの接続ユーティリティを利用しましょう。対象の「cdata.jdbc.api.jar」を実行します。
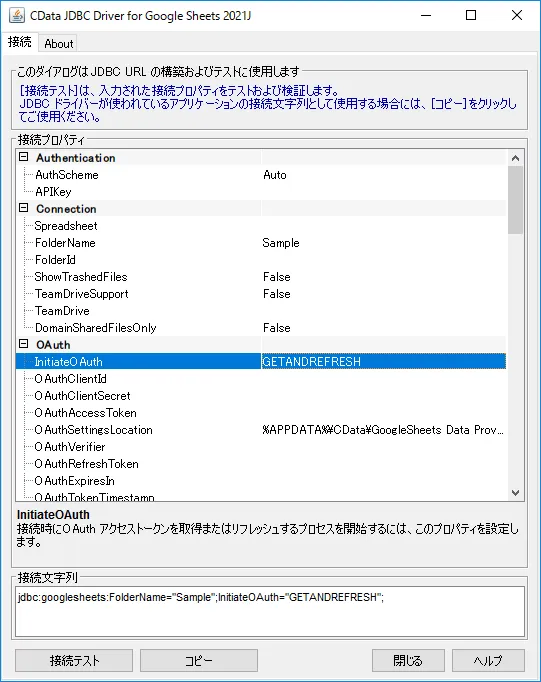
- 以下のような接続テストツールが立ち上がるので必要なプロパティを指定し接続テストを実行します。入力した接続文字列はあとで利用するので控えておきましょう。
URL:jdbc:api:Profile=C:\profiles\\RabbitMQ.apip;AuthScheme=Basic;URL=http://localhost:15672;User=guest;Password=guest;
- また、事前に DbVisualizer のようなJDBC の接続ツールでどのようなデータが取得できるか確認しておくのがおすすめです。
-
RabbitMQ Management HTTP API について
RabbitMQ は、複数のメッセージングプロトコルをサポートするオープンソースのメッセージブローカーです。RabbitMQ Management HTTP API は、RabbitMQ サーバーの管理データと監視データに HTTP 経由でアクセスする手段を提供します。この API では、仮想ホスト、エクスチェンジ、キュー、バインディング、コネクション、チャネル、コンシューマー、ユーザー、権限、ポリシー、クラスター全体の統計情報を取得できます。
HTTP API を利用するには、RabbitMQ サーバーで Management プラグインを有効化する必要があります。デフォルトでは、管理インターフェースはポート 15672 でリッスンします。
Basic 認証の設定
RabbitMQ Management HTTP API は HTTP Basic 認証を使用します。RabbitMQ 管理ユーザーのユーザー名とパスワードを指定する必要があります。
管理 API へのアクセスを有効にするには、以下のステップで進めます:
- サーバーで RabbitMQ Management プラグインが有効になっていることを確認します(rabbitmq-plugins enable rabbitmq_management)。
- 既存の管理ユーザーを使用するか、適切な管理タグ(management、policymaker、monitoring、または administrator)を持つユーザーを作成します。
- RabbitMQ Management HTTP API の完全なベース URL を控えておきます(例:http://localhost:15672)。
RabbitMQ サーバーを設定したら、以下の接続プロパティを設定して接続します:
- AuthScheme:Basic に設定します。
- URL:RabbitMQ Management HTTP API のベース URL に設定します(例:http://localhost:15672)。
- User:RabbitMQ の管理ユーザー名に設定します(例:guest)。
- Password:RabbitMQ の管理パスワードに設定します。
接続文字列の例:
Profile=C:\profiles\RabbitMQ.apip;AuthScheme=Basic;URL=http://localhost:15672;User=guest;Password=guest;
利用可能なテーブル
RabbitMQ プロファイルでは、以下のテーブルにアクセスできます:
- Overview - クラスター全体の統計情報と RabbitMQ ノードに関する情報
- Nodes - RabbitMQ クラスター内の個々のノードに関する情報
- NodeMemory - 特定のクラスターノードの詳細なメモリ使用状況の内訳
- Connections - ブローカーへのすべてのオープンな AMQP コネクションの一覧
- Channels - すべてのコネクションにわたるオープンな AMQP チャネルの一覧
- Consumers - すべてのキューに登録されたコンシューマーの一覧
- Exchanges - すべての仮想ホストで宣言されたエクスチェンジの一覧
- Queues - すべての仮想ホストで宣言されたキューの一覧
- Bindings - エクスチェンジとキュー間のすべてのバインディングの一覧
- VirtualHosts - ブローカーに設定された仮想ホストの一覧
- VhostPermissions - 特定の仮想ホスト内のユーザー権限
- Users - すべての RabbitMQ ユーザーの一覧
- Permissions - すべての仮想ホストにわたる全ユーザーの権限レコード
- TopicPermissions - 全ユーザーのトピックレベルの権限レコード
- Policies - 仮想ホスト内のキューおよびエクスチェンジに適用されたポリシーの一覧
- OperatorPolicies - 仮想ホスト内のキューに適用されたオペレーターポリシーの一覧
- Parameters - 仮想ホストごとのコンポーネントパラメータ(例:federation、shovel)の一覧
- GlobalParameters - すべての仮想ホストに適用されるグローバルパラメータの一覧
- VhostLimits - 特定の仮想ホストに設定されたリソース制限
- UserLimits - 特定のユーザーに設定されたリソース制限
- FeatureFlags - フィーチャーフラグの一覧と、ノード上での有効/無効の状態
- DeprecatedFeatures - 非推奨機能の一覧と、その使用状態
- AuthAttempts - ノードの認証試行統計
- ClusterName - RabbitMQ クラスターの名前
- WhoAmI - 現在認証されている管理ユーザーに関する情報
- ExchangeBindingsSource - 特定のエクスチェンジがソースとなっているバインディング
- ExchangeBindingsDestination - 特定のエクスチェンジが宛先となっているバインディング
- QueueBindings - 仮想ホスト内の特定のキューのバインディング
BizRobo! にJDBC Driver をアップするために lic ファイルを調整
併せてCData JDBC ドライバのライセンスファイルをBizRobo! にアップロードするために少し追加の作業を実施します。
- 「lib」フォルダに存在する「cdata.jdbc.api.lic」ファイルをZIPに圧縮し
- 名前を「cdata.jdbc.api.lic.jar」に変更しておきます。これでBizRobo! にアップロードできるようになります。
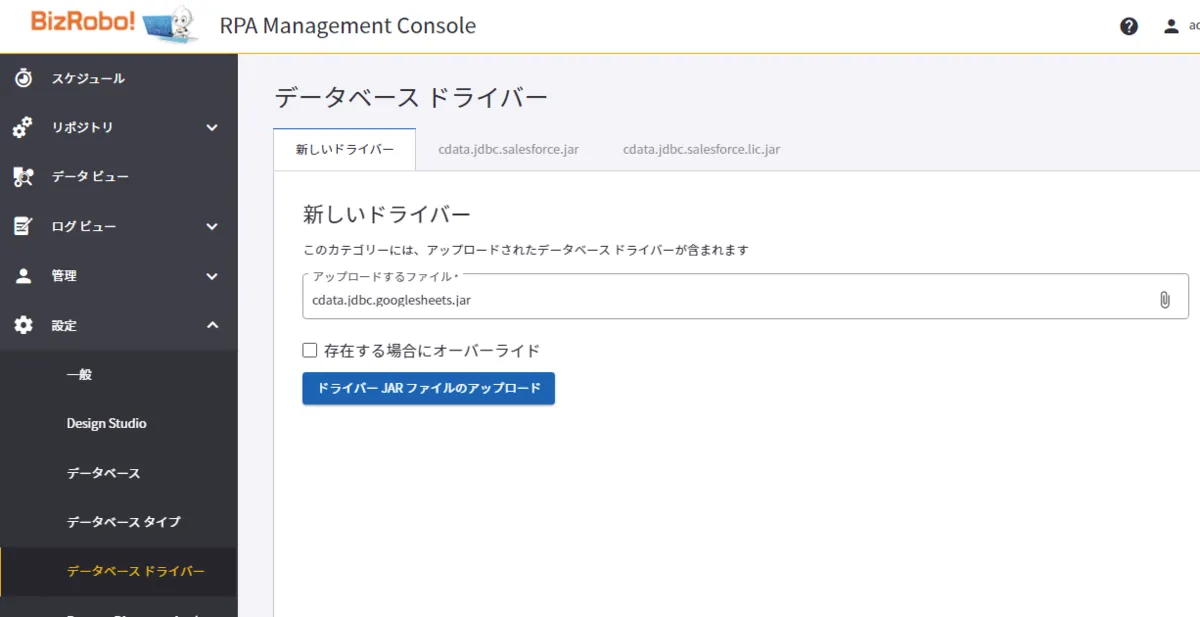
BizRobo! Managmenet Console にJDBC Driver をアップロード
それでは「BizRobo! Managmenet Console」でCData JDBC ドライバを利用できるように設定を進めていきましょう。
- 「設定」→「データベース ドライバー」から「cdata.jdbc.api.jar」、「cdata.jdbc.api.lic.jar」2つのファイルをアップロードします。
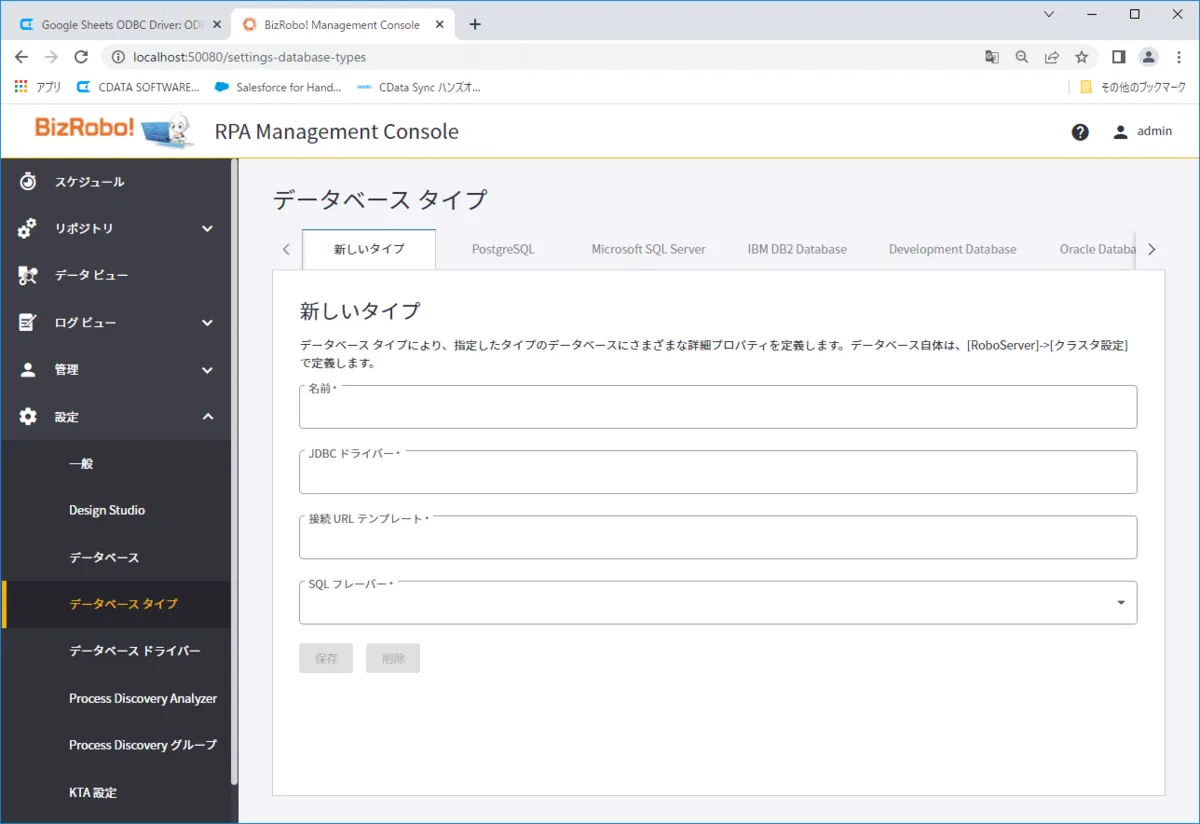
- CData JDBC ドライバのアップロードが完了したら「データベースタイプ」で接続設定を追加しましょう。「設定」→「データベース タイプ」から「新しいタイプ」として以下の情報を入力し保存します。
名前: 例)CData JDBC Driver
JDBC ドライバー:cdata.jdbc.api.APIDriver
接続URL テンプレート:jdbc:api:Profile=C:\profiles\\RabbitMQ.apip;AuthScheme=Basic;URL=http://localhost:15672;User=guest;Password=guest;
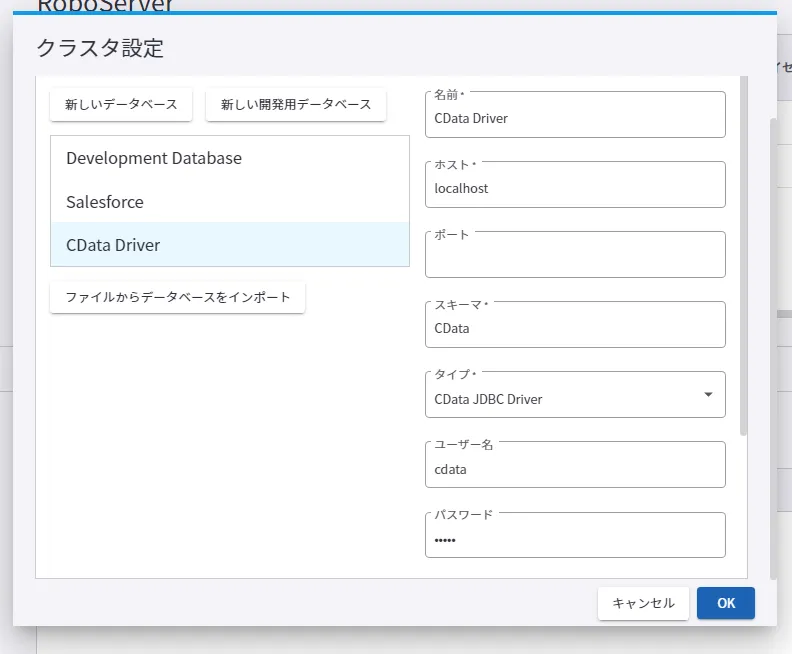
SQLフレーバー:PostgreSQL - 続いて対象のクラスタにデータベース接続を追加します。「管理」→「RoboServer」から対象のクラスタの「クラスタ設定」を開きます。
- 「新しいデータベース」をクリックし各種情報を指定します。この際、明示的な指定が必要なものは「タイプ」だけです。ここで先ほど作成したデータベースタイプを入力します。
それ以外の情報は内部的には利用しないので、任意の文字列を入力してもらって構いません。 - これで設定を反映させれば対象のクラスタでCData JDBC ドライバが利用できるようになります。


データベース設定をプロジェクトに追加
Design Studio を立ち上げて、ロボットを作成するためのプロジェクト側の準備を進めていきましょう。
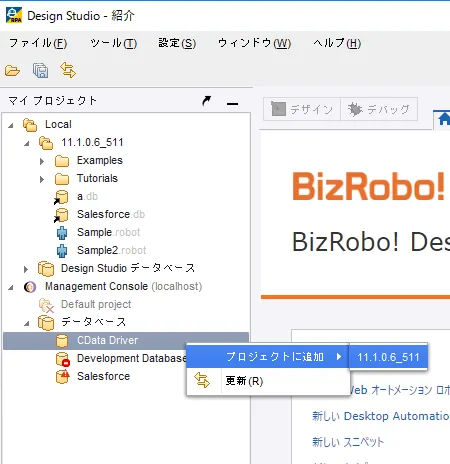
- 「BizRobo! Managmenet Console」で追加したデータベース設定は Design Studio のデータベース一覧に表示されるのでここから右クリックで「プロジェクトに追加」から対象の環境に追加します。
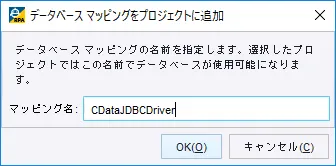
- 任意のマッピング名で追加します。
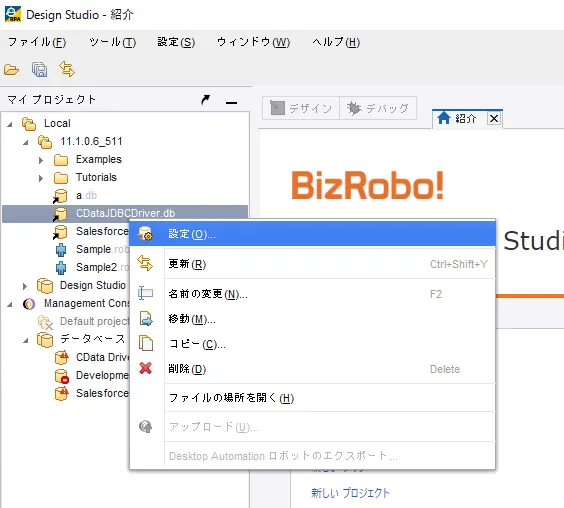
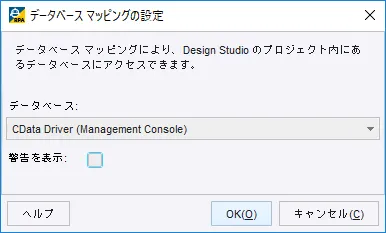
- ちなみにデフォルトでは警告メッセージが表示されてしまうので、追加したデータベース マッピングの「設定」から
- 「警告を表示」のチェックを外しておくと良いです。
データを格納するためのタイプを追加
続いて、取得したデータを変数に適切に追加するために、「タイプ」を作成しましょう。
- メニューの「ファイル」→「新しいタイプ」をクリックし
- 任意のタイプ名で作成します。
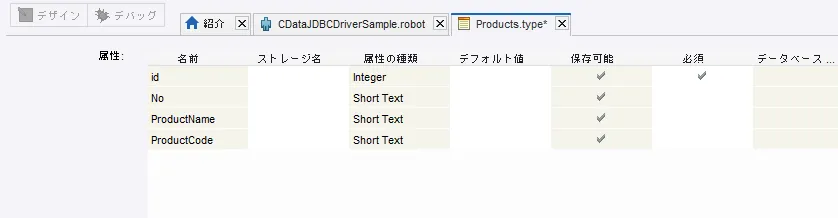
- あとは下記のように各種項目を定義します。
新しいWeb オートメーションロボットを追加
実際にロボットの作成を開始します。
- 「メニュー」から「新しい Web オートメーションロボット」を選択し
- 任意の名称で作成します。
- これで以下のようにデフォルトのロボットが作成され、フローのデザイン画面が表示されます。
変数の準備
取得したデータを格納する変数を設定します。
- 以下の変数画面から「+」ボタンをクリックし
- 先ほど作成したタイプを元に変数を追加します。
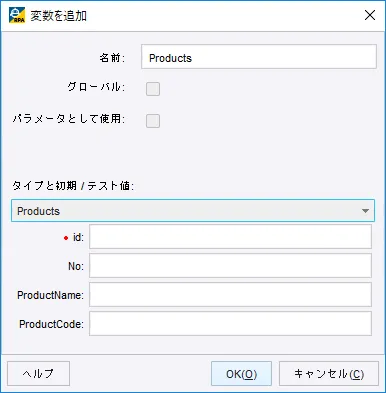
データベース照会アクションを追加
変数を追加したら、実際にCData JDBC ドライバ経由でデータを取得するアクションを追加します。
- デザイン画面から「アクション ステップ」を追加し
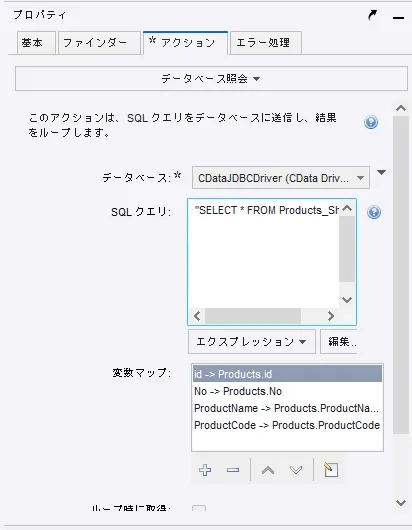
- アクションの一覧から「データベース照会」を選択します。「データベース」で先ほど登録したデータベースマッピングを選択し、SQL クエリの欄にデータを取得するためのクエリを入力します。
最後に変数マップとして先ほど登録したタイプ変数にSQL クエリで取得できる各項目をマッピングします。
CSV 出力フローを追加
取得したデータはBizRobo! の機能を使って、自由に処理できます。
- 今回は試しにCSV データとして出力を行ってみました。詳細な手順は省略しますが、フローの作成方法はBizRobo! のマニュアルを参考に作成しています。
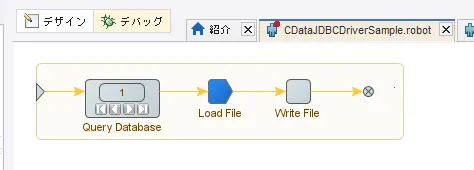
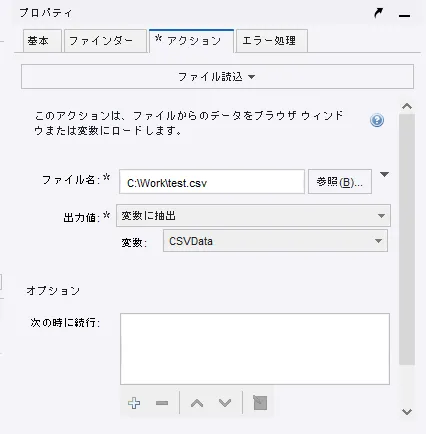
- 対象のCSV ファイルを読み込むアクションを追加し、LongText の変数に格納します。
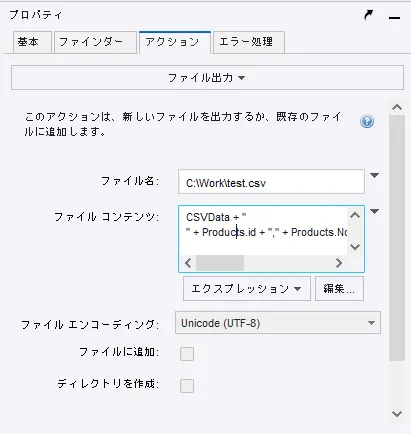
- そのCSV ファイルデータを元に、レコードを1行づつ追加するファイル出力アクションを設定しました。
デバッグして実際に動かしてみる
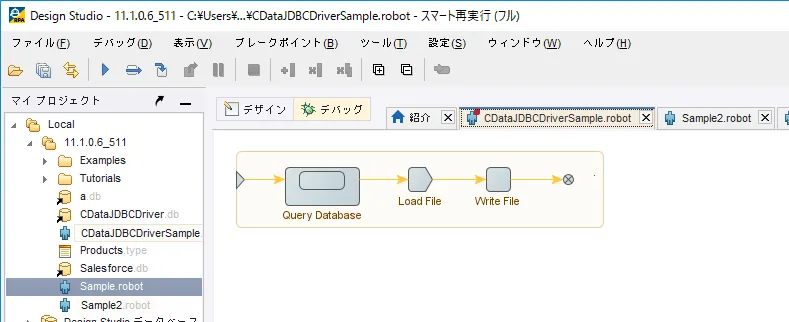
これでロボットが完成です。それでは実際に動かしてみましょう。
- デバッグ画面に移動して、「実行」ボタンをクリックします。
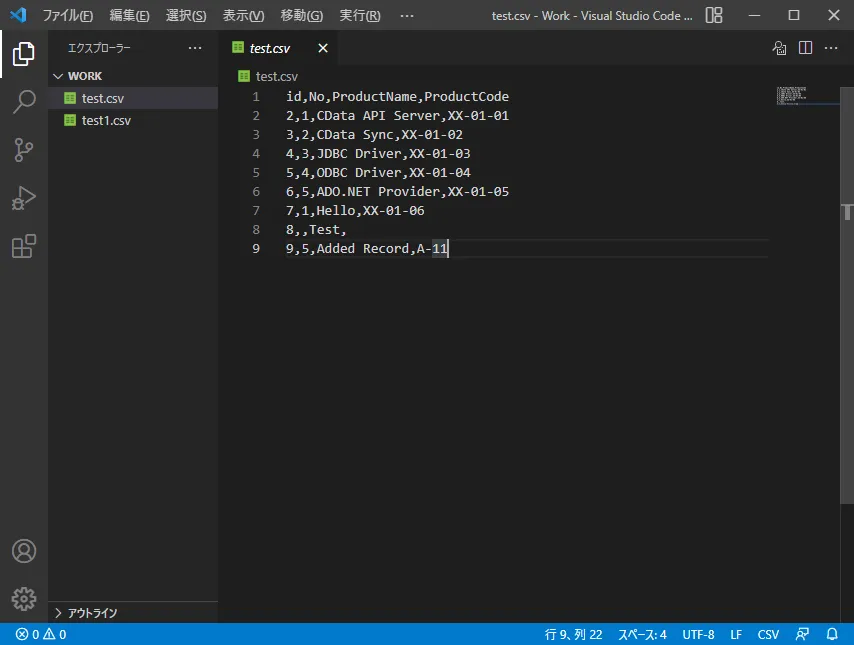
- 正常にロボットが動作すると、以下のようにCSV ファイルが生成されます。
このようにCData JDBC Driver for API とBizRobo! を組み合わせることで、簡単にRabbitMQ のデータを活用した自動化フローを作成することができました。ぜひ、30日の無償評価版をお試しください。