




エンタープライズサーチのNeuron にRabbitMQ のデータを取り込んで検索利用

ブレインズテクノロジー社のNeuron は、先端OSS 技術(Apache Solr)を活用したエンタープライズサーチ(企業内検索エンジン)サービスです。Apache Solr は、エンタープライズサーチ機能をAPI として提供してくれますが、Neuron はApache Solr に企業ユーザーがデータを探索するためのシンプルかつ使いやすいユーザーインターフェースと管理画面・運用機能を提供してくれます。これによりエンドユーザーが簡単にエンタープライズサーチを利用することができます。管理画面では、ファイルやデータのクローリング設定がUI で行えるようになっています。この記事では、Neuron に備わっているJDBC インターフェース経由で、CData JDBC Driver for API を利用することでNeuron にRabbitMQ のデータを取り込んで検索で利用できるようにします。
Neuron にCData JDBC Driver for API データをロード
CData JDBC Driver for API のインストールと.jar ファイルの配置
- CData JDBC Driver for API をNeuron と同じマシンにインストールします。
-
以下のパスにJDBC Driver がインストールされます。
C:\Program Files\CData\CData JDBC Driver for API 20xxJ\lib\cdata.jdbc.api.jar
-
このcdata.jdbc.api.jar とcdata.jdbc.api.lic ファイルをコピーして、Neuron のC:\APP
cf\lib フォルダに配置します。
Neuron CF でのRabbitMQ のデータを扱うリポジトリの作成
-
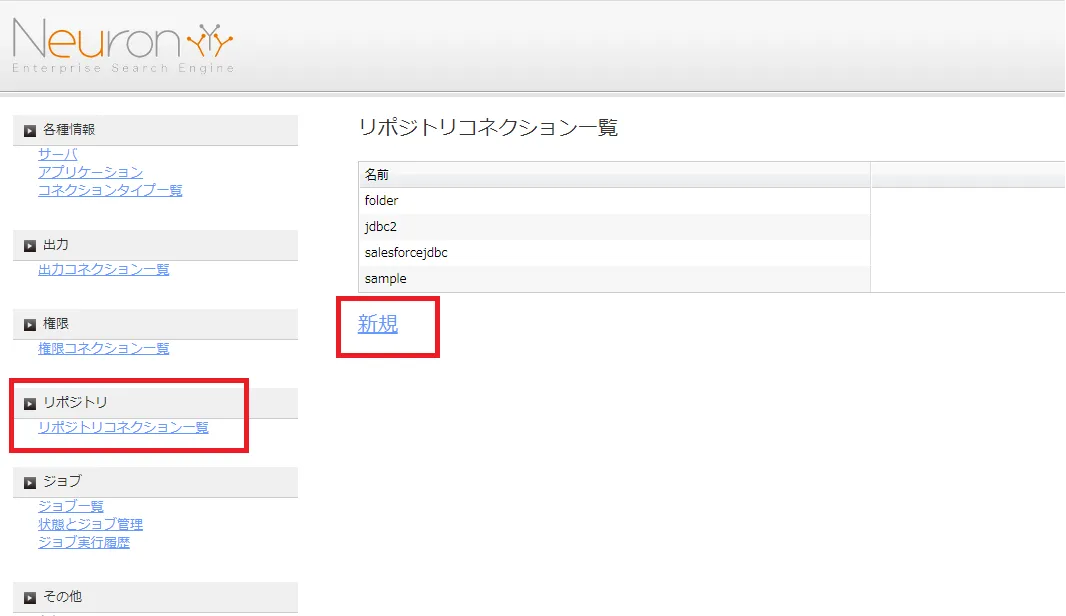
Neuron CF でクローラーの設定をGUI で行います。JDBC を読み取るためのリポジトリを作成します。Neuron の管理画面にログインし、[リポジトリ]→[リポジトリコレクション一覧]→[新規]をクリックします。
-
任意のリポジトリ名を入力します。タイプは[JDBC]を選択します。

-
次に、ドライバーのクラス名とJDBC 接続文字列でRabbitMQ への接続を行います。
RabbitMQ Management HTTP API について
RabbitMQ は、複数のメッセージングプロトコルをサポートするオープンソースのメッセージブローカーです。RabbitMQ Management HTTP API は、RabbitMQ サーバーの管理データと監視データに HTTP 経由でアクセスする手段を提供します。この API では、仮想ホスト、エクスチェンジ、キュー、バインディング、コネクション、チャネル、コンシューマー、ユーザー、権限、ポリシー、クラスター全体の統計情報を取得できます。
HTTP API を利用するには、RabbitMQ サーバーで Management プラグインを有効化する必要があります。デフォルトでは、管理インターフェースはポート 15672 でリッスンします。
Basic 認証の設定
RabbitMQ Management HTTP API は HTTP Basic 認証を使用します。RabbitMQ 管理ユーザーのユーザー名とパスワードを指定する必要があります。
管理 API へのアクセスを有効にするには、以下のステップで進めます:
- サーバーで RabbitMQ Management プラグインが有効になっていることを確認します(rabbitmq-plugins enable rabbitmq_management)。
- 既存の管理ユーザーを使用するか、適切な管理タグ(management、policymaker、monitoring、または administrator)を持つユーザーを作成します。
- RabbitMQ Management HTTP API の完全なベース URL を控えておきます(例:http://localhost:15672)。
RabbitMQ サーバーを設定したら、以下の接続プロパティを設定して接続します:
- AuthScheme:Basic に設定します。
- URL:RabbitMQ Management HTTP API のベース URL に設定します(例:http://localhost:15672)。
- User:RabbitMQ の管理ユーザー名に設定します(例:guest)。
- Password:RabbitMQ の管理パスワードに設定します。
接続文字列の例:
Profile=C:\profiles\RabbitMQ.apip;AuthScheme=Basic;URL=http://localhost:15672;User=guest;Password=guest;
利用可能なテーブル
RabbitMQ プロファイルでは、以下のテーブルにアクセスできます:
- Overview - クラスター全体の統計情報と RabbitMQ ノードに関する情報
- Nodes - RabbitMQ クラスター内の個々のノードに関する情報
- NodeMemory - 特定のクラスターノードの詳細なメモリ使用状況の内訳
- Connections - ブローカーへのすべてのオープンな AMQP コネクションの一覧
- Channels - すべてのコネクションにわたるオープンな AMQP チャネルの一覧
- Consumers - すべてのキューに登録されたコンシューマーの一覧
- Exchanges - すべての仮想ホストで宣言されたエクスチェンジの一覧
- Queues - すべての仮想ホストで宣言されたキューの一覧
- Bindings - エクスチェンジとキュー間のすべてのバインディングの一覧
- VirtualHosts - ブローカーに設定された仮想ホストの一覧
- VhostPermissions - 特定の仮想ホスト内のユーザー権限
- Users - すべての RabbitMQ ユーザーの一覧
- Permissions - すべての仮想ホストにわたる全ユーザーの権限レコード
- TopicPermissions - 全ユーザーのトピックレベルの権限レコード
- Policies - 仮想ホスト内のキューおよびエクスチェンジに適用されたポリシーの一覧
- OperatorPolicies - 仮想ホスト内のキューに適用されたオペレーターポリシーの一覧
- Parameters - 仮想ホストごとのコンポーネントパラメータ(例:federation、shovel)の一覧
- GlobalParameters - すべての仮想ホストに適用されるグローバルパラメータの一覧
- VhostLimits - 特定の仮想ホストに設定されたリソース制限
- UserLimits - 特定のユーザーに設定されたリソース制限
- FeatureFlags - フィーチャーフラグの一覧と、ノード上での有効/無効の状態
- DeprecatedFeatures - 非推奨機能の一覧と、その使用状態
- AuthAttempts - ノードの認証試行統計
- ClusterName - RabbitMQ クラスターの名前
- WhoAmI - 現在認証されている管理ユーザーに関する情報
- ExchangeBindingsSource - 特定のエクスチェンジがソースとなっているバインディング
- ExchangeBindingsDestination - 特定のエクスチェンジが宛先となっているバインディング
- QueueBindings - 仮想ホスト内の特定のキューのバインディング
ドライバクラス名:cdata.jdbc.api.APIDriver
接続文字列:jdbc:api:Profile=C:\profiles\\RabbitMQ.apip;AuthScheme=Basic;URL=http://localhost:15672;User=guest;Password=guest;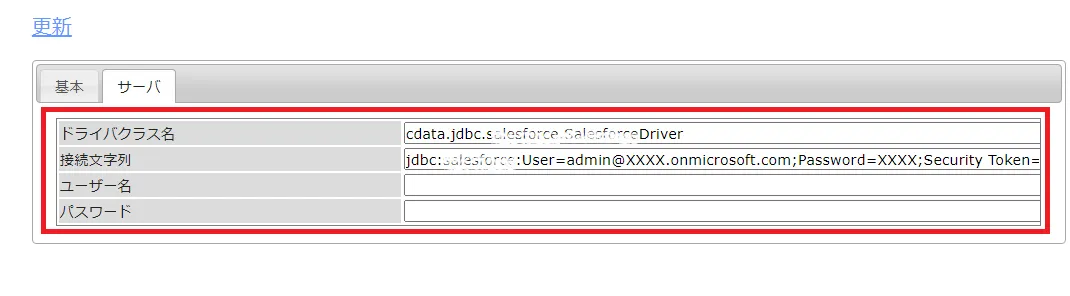
- [更新]をクリックして、RabbitMQ に接続するリポジトリコレクションができました。
Neuron でRabbitMQ のデータをクローリングするジョブを作成
続いて、RabbitMQ のどのデータをどのようにクローリングするのかをジョブで定義していきます。
-
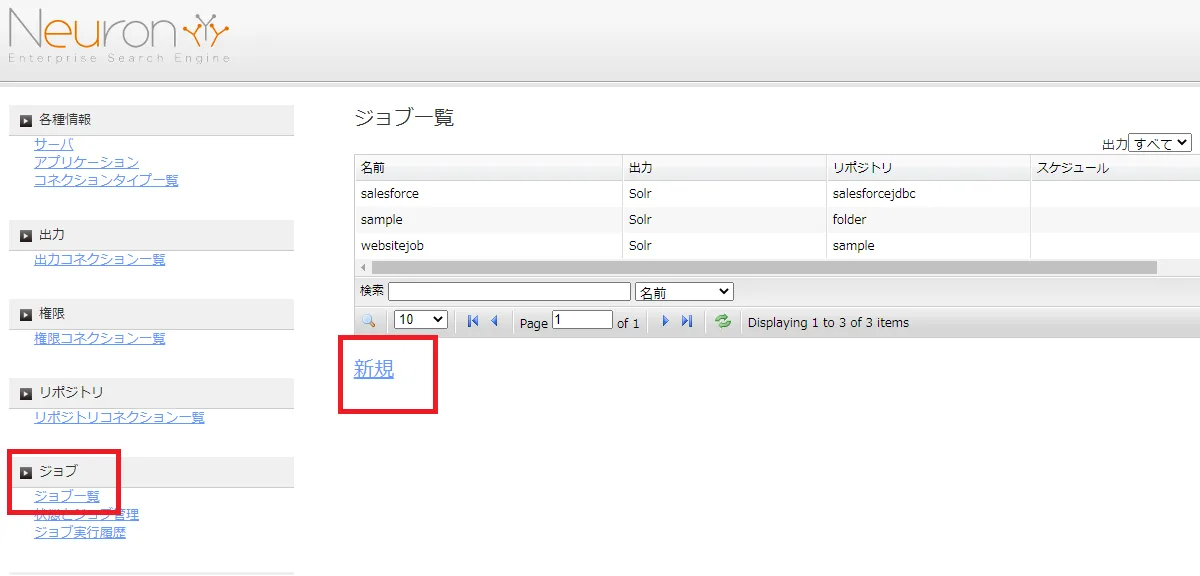
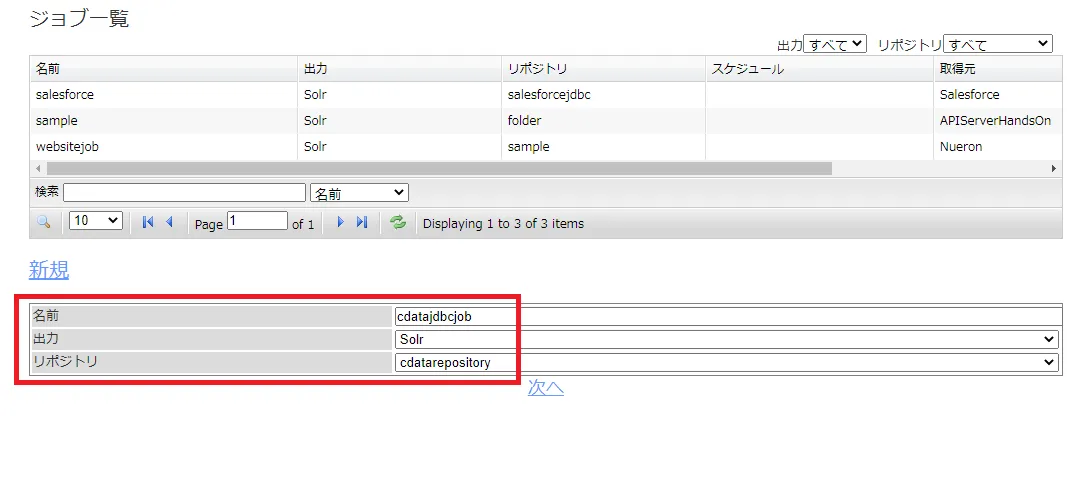
管理画面で[ジョブ]→[ジョブ一覧]→[新規]とクリックします。
-
任意のジョブ名を入力します。出力先にはSolr を選択します。リポジトリは先ほど作成したRabbitMQ に接続するリポジトリコレクションを選びます。
-
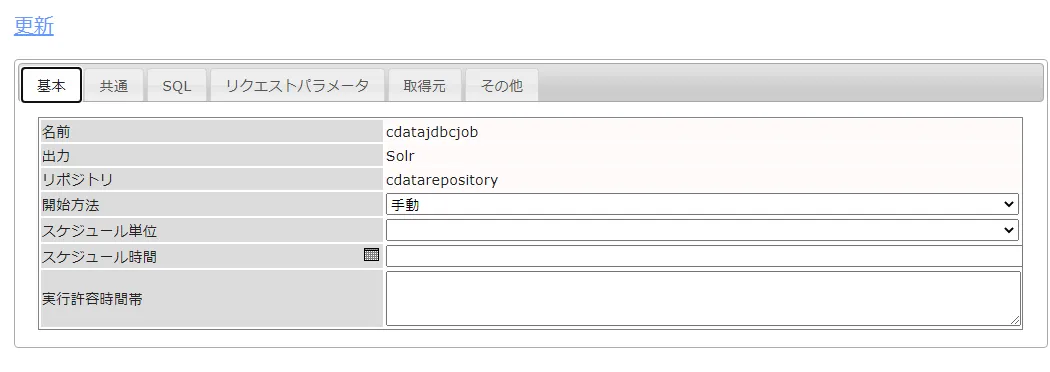
次に基本タブからジョブ実行を手動にするか、定期実行するかを自由に設定します。
-
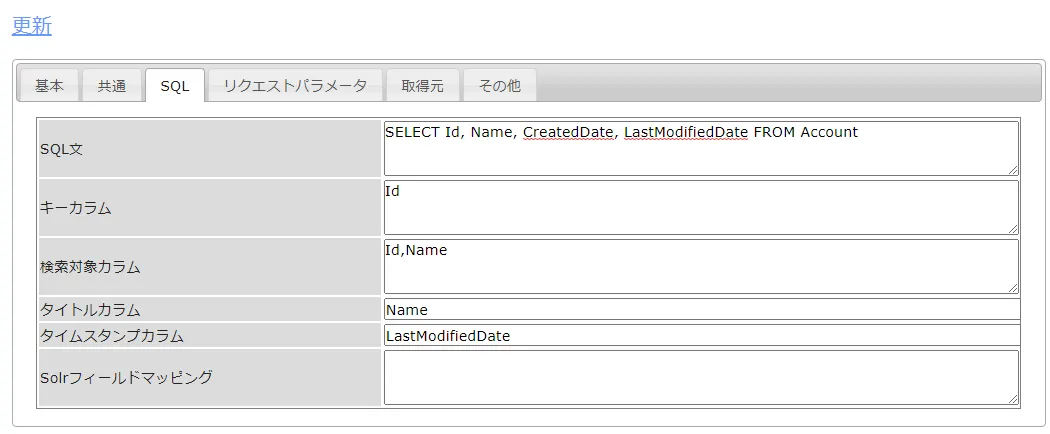
SQL タブでは、どんなデータを取得するのか、テーブル名やカラム、フィルタリング条件などを設定できます。CData JDBC ドライバがRabbitMQ のデータをテーブルにモデル化しているので、標準SQL でRabbitMQ をクエリすることができます。
- SQL文:SELECT , FROM AuthAttempts
- キーカラム:Id など取得テーブルのキーとなるカラム
- 検索対象カラム:検索の対象とするカラム
- タイトルカラム:検索結果のタイトルとするカラム
- タイムスタンプカラム:タイムスタンプとなるカラムがあれば、ここで指定します
- リクエストパラメータでは、検索結果レコードのURL (があれば)を設定することもできます。URL を表示できると表示された検索結果からレコードに簡単に移動できます。
- 取得元では、ラベルを設定しておきます。[更新]をクリックして、クローラージョブの設定を完了します。
Neuron でRabbitMQ のデータをクロールするジョブを実行
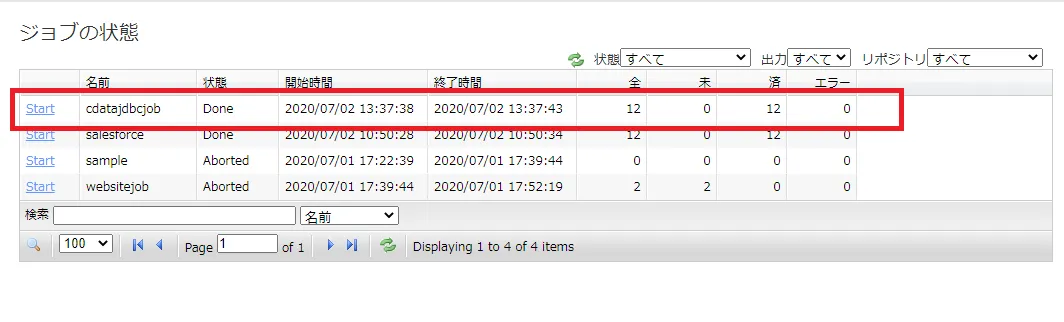
実際にNeuron で作成したジョブを実行します。[ジョブ]→[状態とジョブ管理]をクリックし、作成したジョブの[Start]をクリックします。
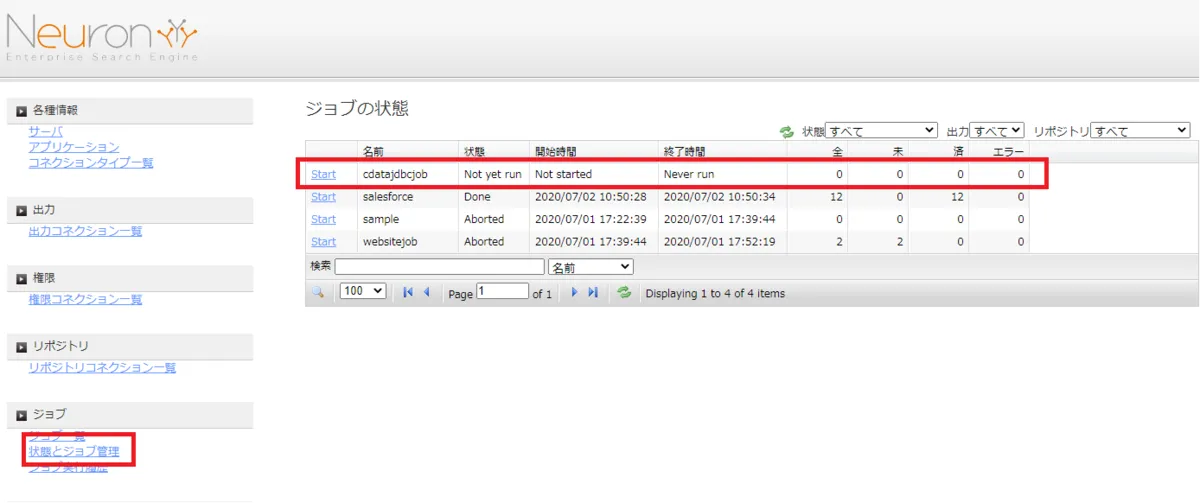
ジョブが正常完了すると、[Done]がステータスとして表示されます。
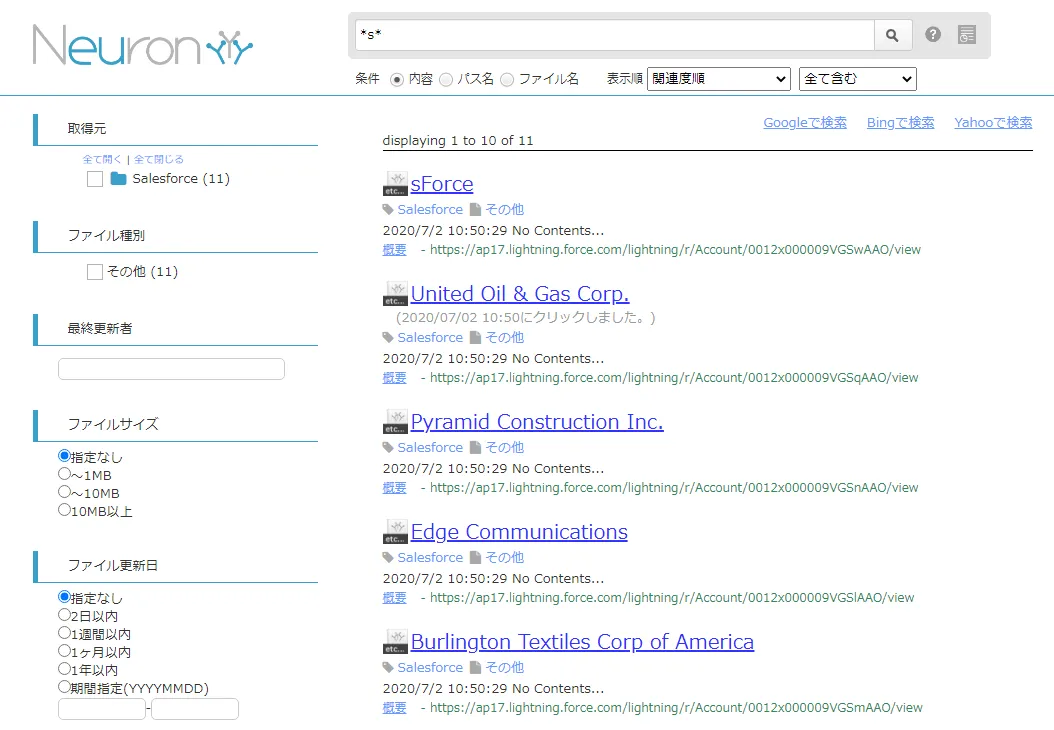
Neuron 上でのRabbitMQ のデータの検索の実施
実際にNeuron 上で検索ができるか確認してみます。取得元を絞り込むこと、内容やファイル名での検索、ファイルサイズやファイル更新日の絞り込み、部分一致や全部一致で検索が可能です。 検索をかけてみると、以下のようにデータを取得できました。
CData JDBC Driver for API をNeuron で使うことで、RabbitMQ コネクタとして機能し、簡単にデータを取得して同期することができました。ぜひ、30日の無償評価版をお試しください。