




AWS Glue Studio でSnowflake のデータ連携のETL 処理を作成

AWS Glue はAmazon が提供するETL サービスで、ビジネスデータをストレージやアナリティクスプラットフォームに簡単にロード・加工ができます。CData Glue Connectors を使うことで、Glue Studio でノーコード・ローコードでETL ジョブを作成することが可能になります。この記事では、CData Glue Connector for Snowflake を使って、Snowflake のデータ連携を行うAWS Glue ジョブを作成していきます。
IAM ロールの設定
AWS Glue ジョブを作成するには、AWS のIAM ロールを設定する必要があります。 IAM ロールは、Glue ジョブが関連するすべてのリソース(Amazon S3 のリソース、ターゲット、スクリプト、テンポラリーディレクトリ、AWS Glue Catalog オブジェクトを含む)にアクセス権限を持つ必要があります。また、AWS Glue Marketplace で購入するCData Glue Connector for Snowflake へのアクセス権限も必要です。
ミニマムで、以下のポリシーをIAM ロールに追加する必要があります:
- AWSGlueServiceRole (Glue Studio およびGlue Jobs へのアクセス)
- AmazonEC2ContainerRegistryReadOnly (CData AWS Glue Connector for Snowflake へのアクセス)
Amazon S3 データにアクセスする場合は以下を追加:
- AmazonS3FullAccess (Amazon S3 への読み書き)
接続プロパティの保存にAWS Secrets Manager を使う場合、インラインでポリシーを追加して、Glue ジョブに必要な特定のsecrets へのアクセスを許容:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"secretsmanager:GetResourcePolicy",
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret",
"secretsmanager:ListSecretVersionIds"
],
"Resource": [
"arn:aws:secretsmanager:us-west-2:111122223333:secret:aes128-1a2b3c",
"arn:aws:secretsmanager:us-west-2:111122223333:secret:aes192-4D5e6F",
"arn:aws:secretsmanager:us-west-2:111122223333:secret:aes256-7g8H9i"
]
}
]
}
AWS Glue Studio およびGlue Job でのアクセス権限についての詳細情報は、「Setting up IAM Permissions for AWS Glue in the AWS Glue」ドキュメントを参照してください。
Amazon S3 バケットへのアクセス権限についての詳細情報は、「Amazon Simple Storage Service Developer Guide」を参照してください。
シークレットへのアクセスコントロール設定については、AWS Secrets Manager ドキュメントの「Authentication and Access Control for AWS Secrets Manager」および「Limiting Access to Specific Secrets」を参照してください。AWS Secret Manager から取得されたクレデンシャル(key-value ペアの文字列)は、CData Glue Connector がデータソースに接続する際に使われます。
Snowflake 接続プロパティの取得
それでは、Snowflake データベースに接続していきましょう。認証に加えて、以下の接続プロパティを設定します。
- Url:お使いのSnowflake URL を指定します。例:https://orgname-myaccount.snowflakecomputing.com
- Legacy URL を使用する場合:https://myaccount.region.snowflakecomputing.com
- ご自身のURL は以下のステップで確認できます。
- Snowflake UI の左下にあるユーザー名をクリックします
- Account ID にカーソルを合わせます
- Copy Account URL アイコンをクリックして、アカウントURL をコピーします
- Database(オプション):CData 製品によって公開されるテーブルとビューを、特定のSnowflake データベースのものに制限したい場合に設定します
- Schema(オプション):CData 製品によって公開されるテーブルとビューを、特定のSnowflake データベーススキーマのものに制限したい場合に設定します
Snowflakeへの認証
CData 製品では、Snowflake ユーザー認証、フェデレーション認証、およびSSL クライアント認証をサポートしています。認証するには、User とPassword を設定し、AuthScheme プロパティで認証方法を選択してください。
キーペア認証
ユーザーアカウントに定義されたプライベートキーを使用してセキュアなトークンを作成し、キーペア認証で接続することも可能です。この方法で接続するには、AuthScheme をPRIVATEKEY に設定し、以下の値を設定してください。
- User:認証に使用するユーザーアカウント
- PrivateKey:プライベートキーを含む.pem ファイルへのパスなど、ユーザーに使用されるプライベートキー
- PrivateKeyType:プライベートキーを含むキーストアの種類(PEMKEY_FILE、PFXFILE など)
- PrivateKeyPassword:指定されたプライベートキーのパスワード
多要素認証(MFA)
Snowflake アカウントでMFA(Duo Security 経由)が有効になっている場合は、MFACode に Duo 認証アプリで生成されたパスコードを設定してください。
その他の認証方法については、ヘルプドキュメントの「Snowflakeへの認証」セクションをご確認ください。
CData Glue Connector for Snowflake で使用するので必要なプロパティの値をメモしておきます。
(Optional)Snowflake Connection Properties Credentials をAWS Secrets Manager に保存する
接続プロパティをセキュアに保存して使用するには、AWS Secrets Manager に保存することができます。
Note: AWS Glue ETL ジョブおよびシークレットは、同じリジョンにホストされる必要があります。リジョンをまたぐシークレットの取得はサポートされていません。
- AWS Secrets Manager console にサインインします。
- service introduction ページもしくはSecrets list ページで、Store a new secret を選択します。
- Store a new secret ページで、Other type of secret を選択します。このオプションはシークレットの構造や詳細を自身で提供するものです。
- Snowflake への接続プロパティについては"Activate" セクションを参照してください。必要なプロパティに対して、key-value ペアを作ります。例:
- Username: account user (for example, [email protected])
- Password: account password
- Add any additional private credential key-value pairs required by the CData Glue Connector for Snowflake
シークレットの作成については、AWS Secrets Manager User Guide のCreating and Managing Secrets with AWS Secrets Manager を参照してください。
- AWS Glue Studio で使用するシークレット名を保存します。
CData Glue Connector for Snowflake をサブスクライブする
AWS Glue Studio でCData Glue Connector for Snowflake を利用するには、AWS Marketplace でコネクタのサブスクリプションを行う必要があります。すでにCData Glue Connector for Snowflake のサブスクリプション契約をしている場合には、この部分はスキップしてください。
- AWS Glue Studio でConnectors をクリック
- AWS Marketplace にアクセス
- "CData Snowflake" のコネクタを検索
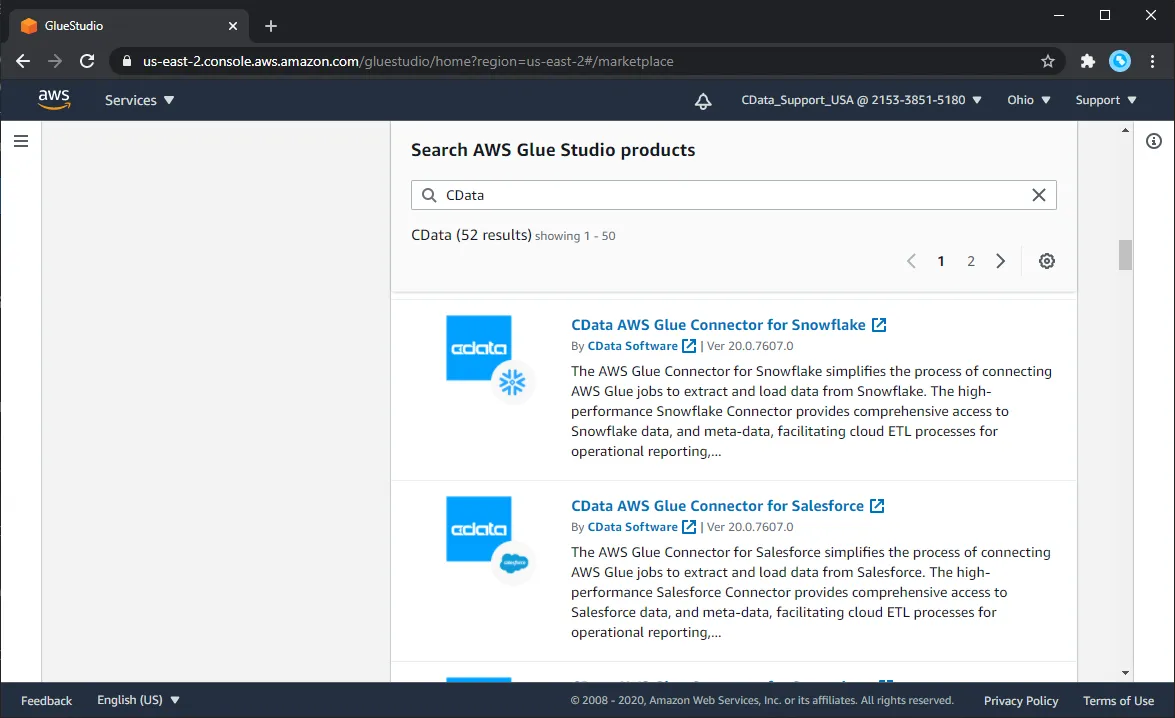
- "Continue to Subscribe" をクリック
- Connector の使用条件に同意して、リクエストが処理完了を待ちます
- "Continue to Configuration" をクリック
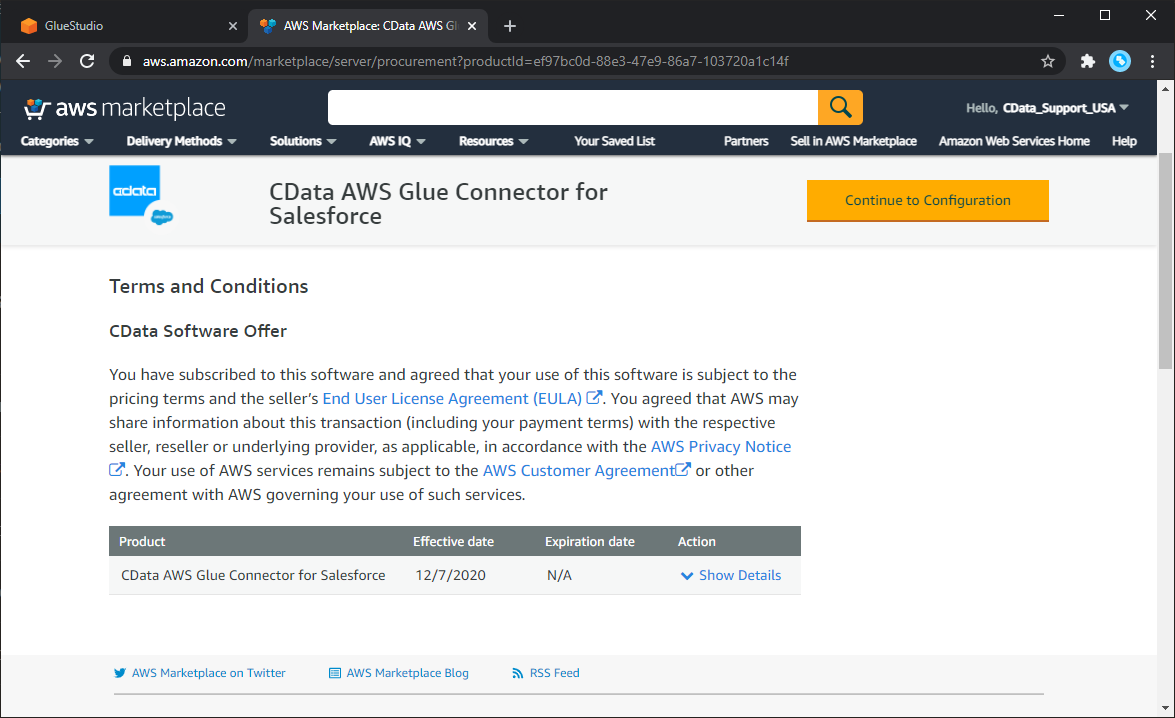
Glue Studio でCData Glue Connector for Snowflake をアクティベートする
AWS Glue でCData Glue Connector for Snowflakeを使うためには、AWS Glue Studio でサブスクライブしたコネクタをアクティベートする必要があります。アクティベートすることで、AWS アカウントにコネクタオブジェクトが作成されます。
- コネクタのサブスクリプションが完了したら、AWS Marketplace Connector ページにnew Config タブが表示されます。
- デリバリーオプションを選択して、"Continue to Launch" ボタンをクリックします。
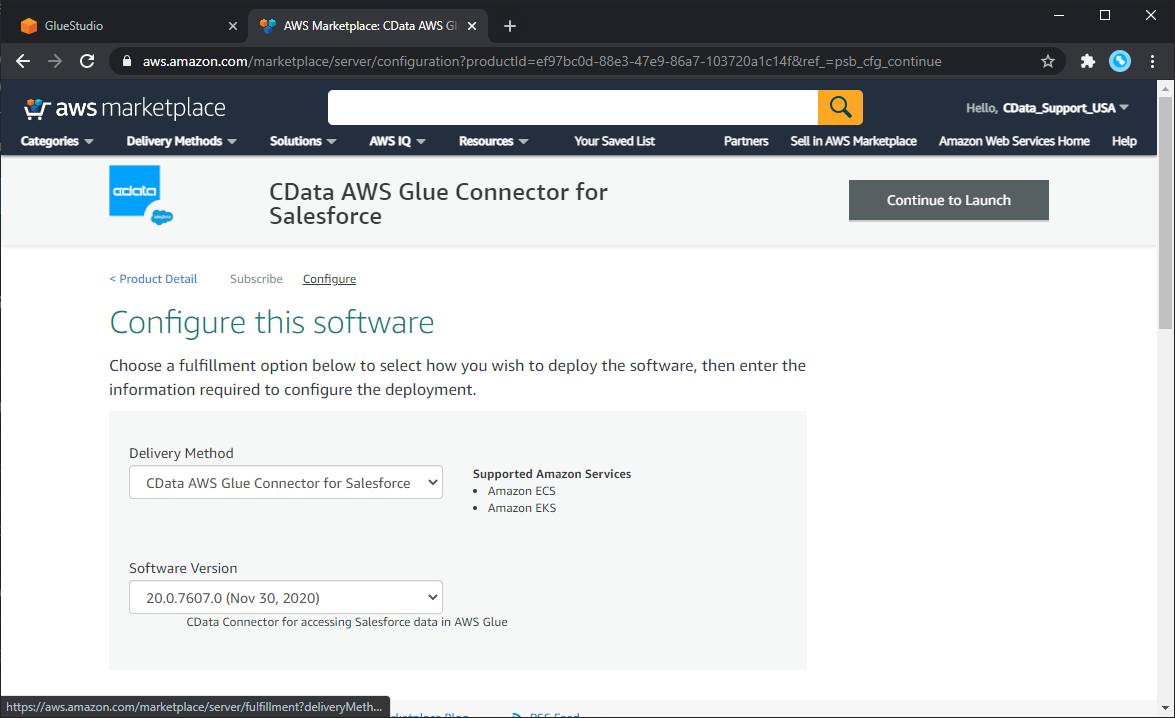
- ローンチタブで、"Usage Instructions" をクリックして、表示されるリンクに従い、接続設定を行います。
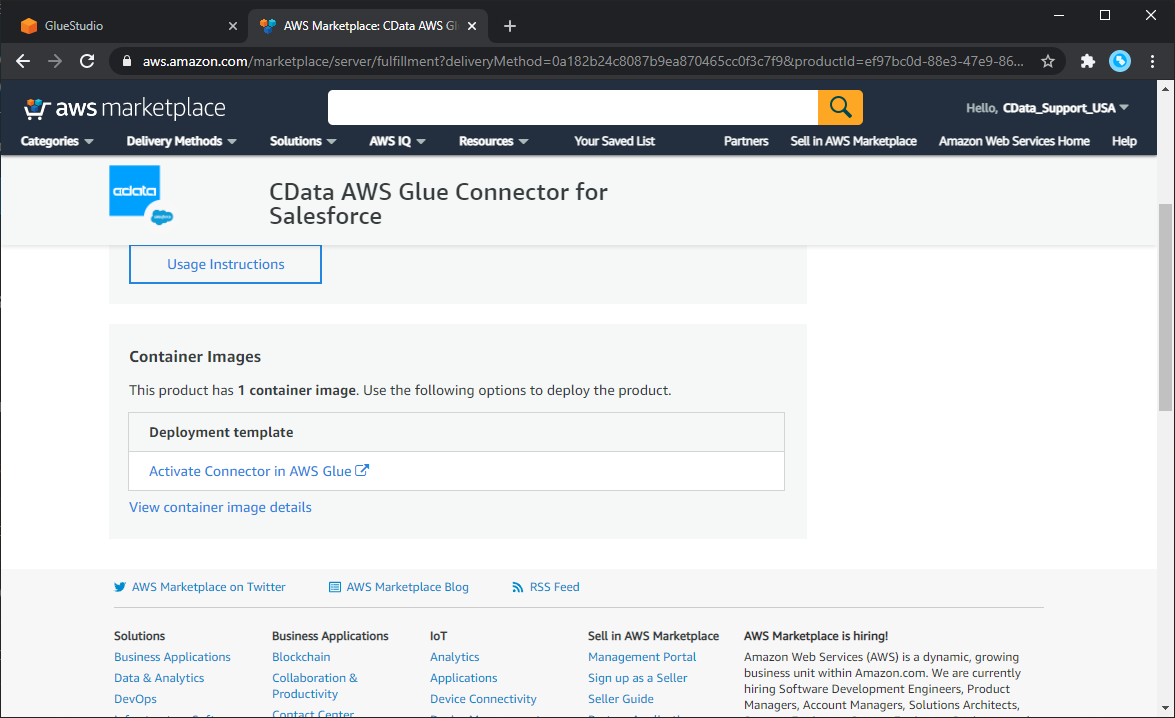
Connection アクセスで、JDBC URL 形式を選択し、接続設定を行います。以下が一般的なSnowflake への接続のJDBC URL 接続文字列フォーマットです。Snowflake への接続の詳細については、Connector のヘルプドキュメントを参照してください。
AWS Secrets Manager でのシークレットの保管をしている場合には、プレースホルダーの値 (e.g. ${Property1}) は空白になります。そうでない場合には、入力した値はAWS Glue Connection インターフェースはRead-only のJDBCURL として表示されます。
Username & Password
jdbc:cdata:Snowflake:AuthScheme=Password;URL=${URL};Warehouse=${Warehouse};User=${Username};Password=${Password}Private Key
jdbc:cdata:Snowflake:AuthScheme=PrivateKey;URL=${URL};Warehouse=${Warehouse};User=${Username};PrivateKey={$PrivateKey};PrivateKeyType={$PrivateKeyType};PrivateKeyPassword=${PrivateKeyPassword}OKTA
jdbc:cdata:Snowflake:AuthScheme=OKTA;URL=${URL};Warehouse=${Warehouse};User=${Username};Password=${Password};SSOIDPDomain=${SSOIDPDomain}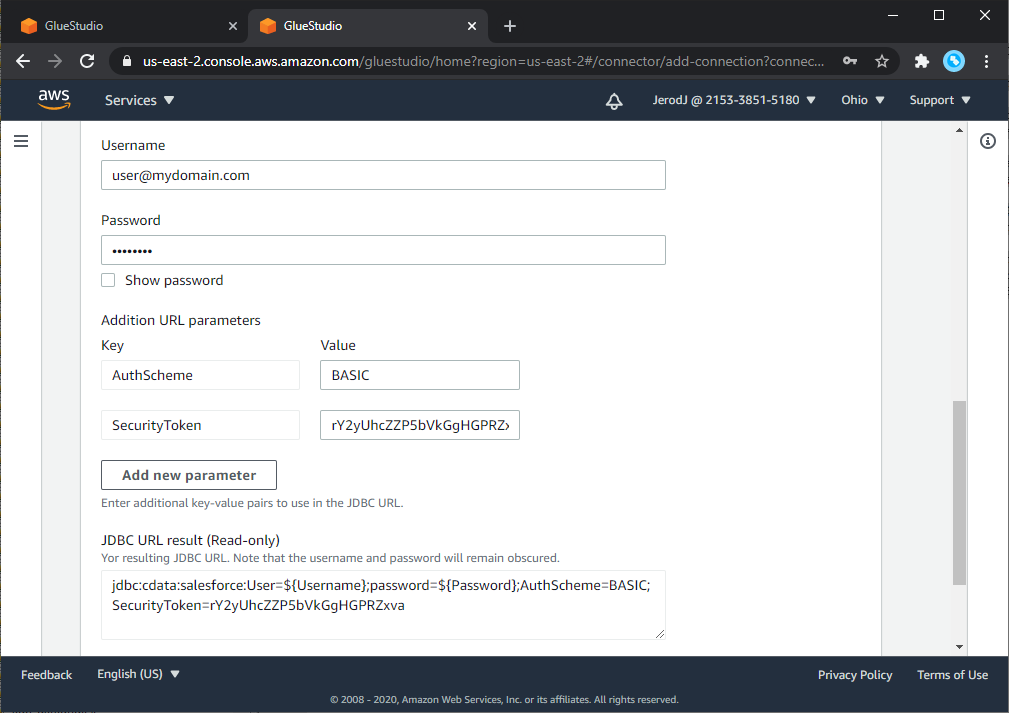
- (Optional): コネクタのログ取得を設定。
CData Glue Connector for Snowflake のログ機能を利用する場合、JDBC URL に以下の2つのプロパティを追加しま:
- Logfile: Set this to "STDOUT://"
- Verbosity: Set this to an integer (1-5) for varying depths of logging. 1 is the default, 3 is recommended for most debugging scenarios.
- Network オプションを設定して"Create Connection" をクリックします。
Amazon Glue ジョブの作成
接続設定の完了後、Glue ジョブを作成することができます。
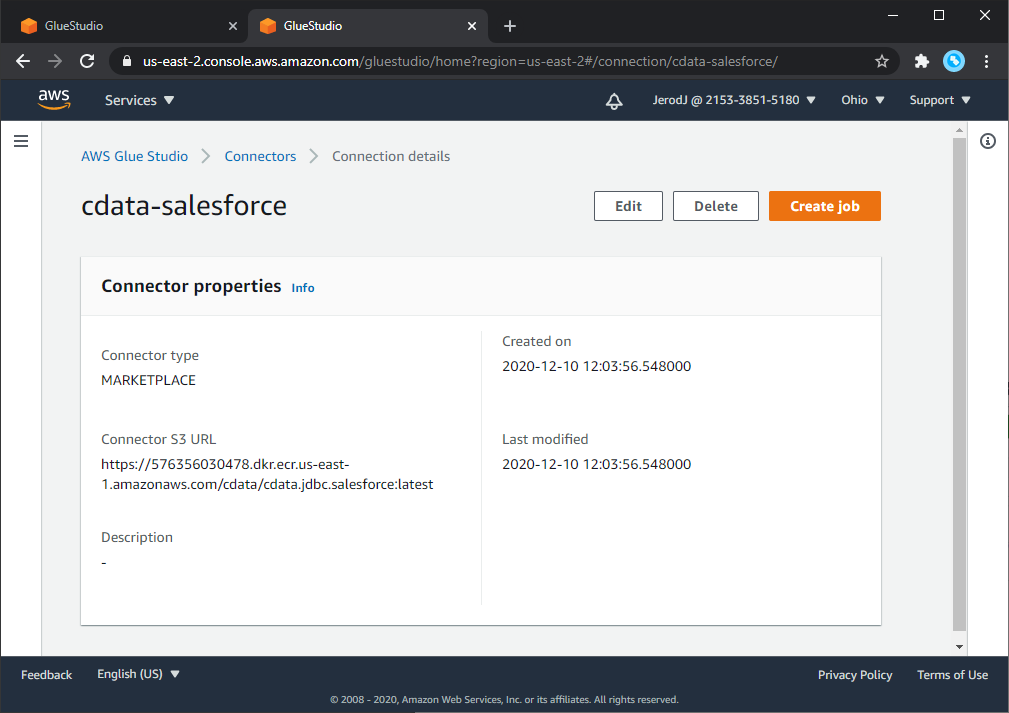
コネクションを使うジョブを作成
- Glue Studio で"Your connections" から作成したConnection を選択します。
- "Create job" をクリックします。
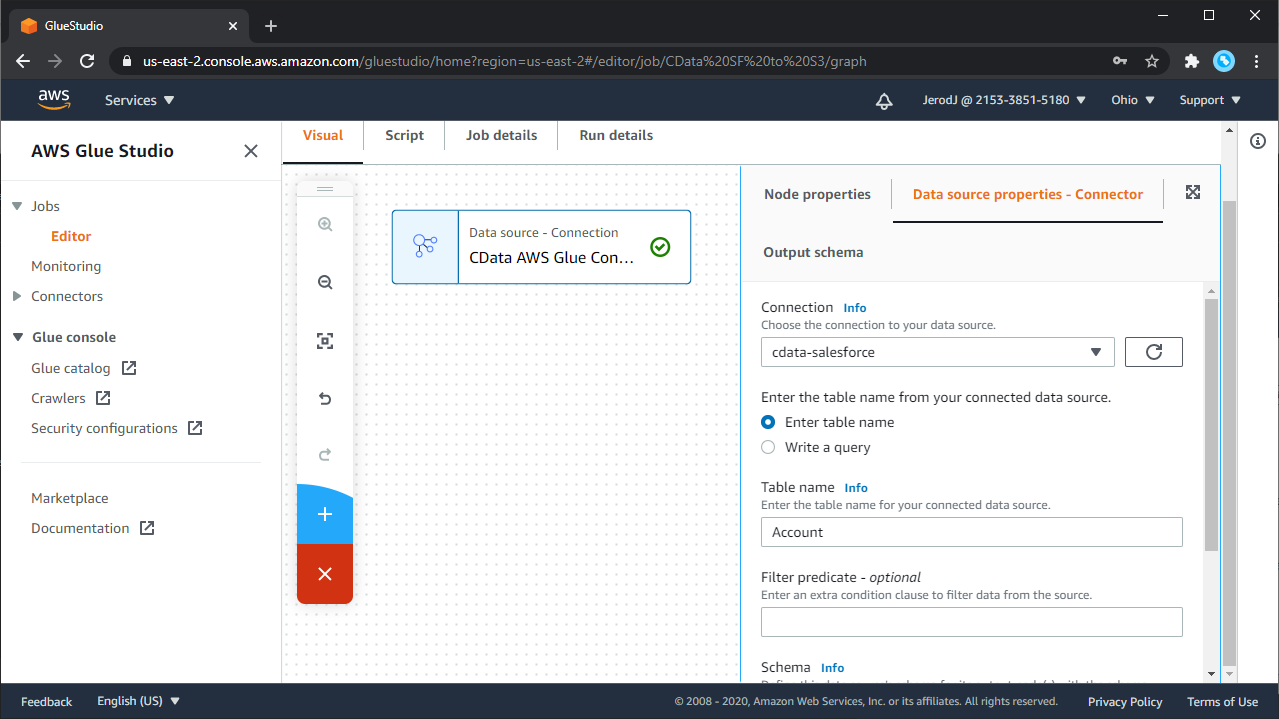
ジョブエディタが開くので、新しいNode を追加します。Node 詳細パネルの右にSource Properties タブがあります。
Source Node Properties を設定:
Source properties タブでデータソースへの接続オプションを選択できます。AWS Glue Studio ヘルプで詳細を確認してください。ここではシンプルな例を示します。
- ジョブエディタで、コネクタのSource Node が選択されていることを確認します。右側のNode 詳細パネルSource Properties タブを選択します。
- コネクタ名のConnection フィールドが出てきます。
- データソースのデータロケーションを入力します。使用するデータのテーブル名もしくはSQL クエリを直接入力することができます。SQL クエリの例は SELECT Id, ProductName FROM Products WHERE Id = 1 です。
- データソースからTransformation Node にデータを渡すために、AWS Glue Studio ではデータのスキーマを定義する必要があります。"Use Schema Builder" を選択して、スキーマを設定します。
- 必要に応じて他のオプションフィールドを設定します:
- Partitioning information - for parallelizing the read operations from the data source
- Data type mappings - to convert data types used in the source data to the data types supported by AWS Glue
- Filter predicate - to select a subset of the data from the data source
これらのオプションの詳細については"Use the Connection in a Glue job using Glue Studio" を参照してください。
- Node properties パネルのOutput スキーマタブで、これらの作成されたスキーマを確認できます。
Glue ジョブの編集、保存、実行
ジョブグラフでNode を追加・編集することでジョブを変更することができます。詳細は、Editing ETL jobs in AWS Glue Studio を参照してください。
ジョブの編集が終わったら、Job Properties を入力します。
- グラフエディタでJob Properties タブを選択します。
- カスタムコネクタの使用には、以下のJob Properties を設定します:
- Name: Provide a job name.
- IAM Role: Choose (or create) an IAM role with the necessary permissions, as described previously.
- Type: Choose "Spark."
- Glue version: Choose "Glue 2.0 - Supports spark 2.4, Scala 2, Python 3."
- Language: Choose "Python 3."
- 他のパラメータにはデフォルト値を使います。詳細はAWS Glue Developer Guide の"Defining Job Properties" を参照してください。
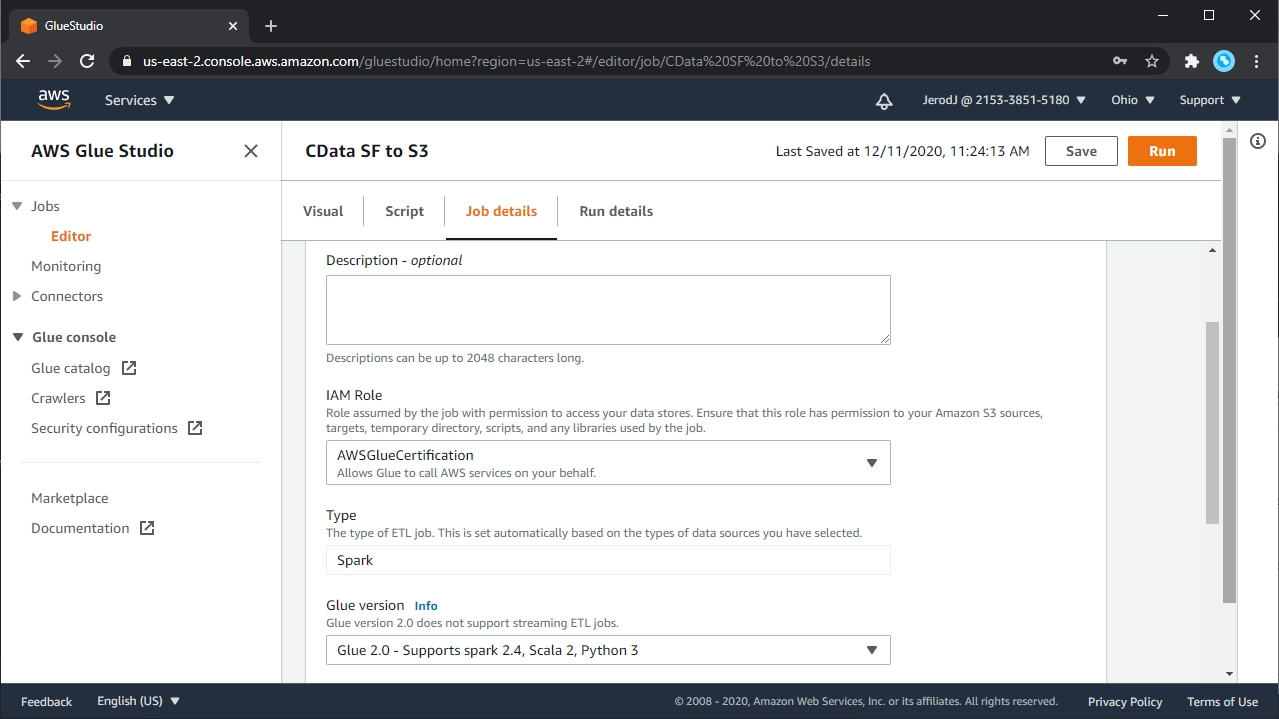
- "Save" を押して保存します。
- "Successfully created Job" の表示が緑のバナーに出ます。
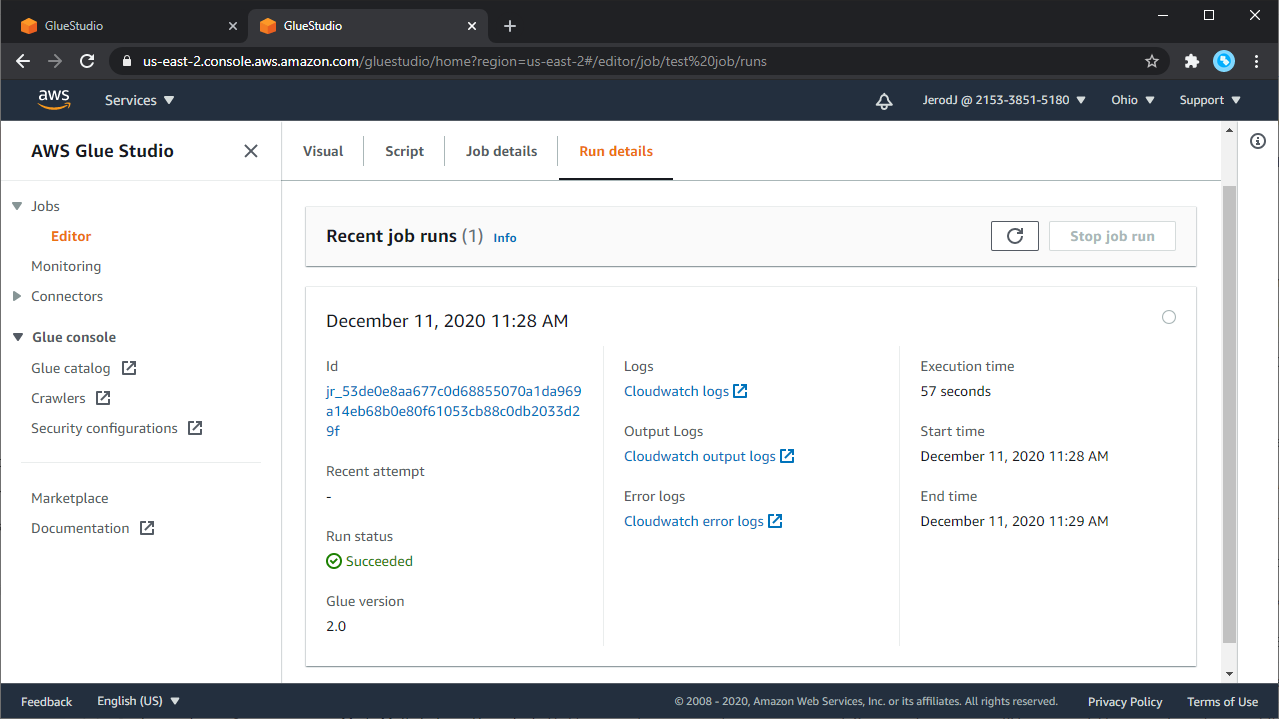
- ジョブの保存後、"Run" をクリックしてジョブを実行します。
- "Script" tab を選択すると、ジョブで生成されたスクリプトを見ることができます。"Job runs" タブには、ジョブの実行履歴が出ます。詳細は"View information for recent job runs" を参照してください。
Generate Script のレビュー
ジョブ作成において、Script タブをクリックし、Glue Studio が作成するスクリプトを確認することができます。シンプルなSnowflake のデータのS3 バケットへの書き込みの場合、スクリプトは以下のようになります:
スクリプトサンプル
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [connection_type = "marketplace.jdbc", connection_options = {"dbTable":"Products","connectionName":"cdata-snowflake"}, transformation_ctx = "DataSource0"]
## @return: DataSource0
## @inputs: []
DataSource0 = glueContext.create_dynamic_frame.from_options(connection_type = "marketplace.jdbc", connection_options = {"dbTable":"Products","connectionName":"cdata-snowflake"}, transformation_ctx = "DataSource0")
## @type: DataSink
## @args: [connection_type = "s3", format = "json", connection_options = {"path": "s3://PATH/TO/BUCKET/", "partitionKeys": []}, transformation_ctx = "DataSink0"]
## @return: DataSink0
## @inputs: [frame = DataSource0]
DataSink0 = glueContext.write_dynamic_frame.from_options(frame = DataSource0, connection_type = "s3", format = "json", connection_options = {"path": "s3://PATH/TO/BUCKET/", "partitionKeys": []}, transformation_ctx = "DataSink0")
job.commit()
CData Glue Connector for Snowflake をAWS Glue Studio で使って、簡単にSnowflake のデータをS3 バケットや他の同期先にETL するジョブを作成することができます。 また、Glue Connector を使って、Snowflake にデータを挿入、更新、削除を行うGlue ジョブを作ることもできます。.