
本記事では、CData Sync と dbt Core を組み合わせて、メダリオンアーキテクチャに基づいた ELT パイプラインを構築する方法を解説します。実装例として、PostgreSQL の販売データを Snowflake に取り込み、Bronze → Silver → Gold の各レイヤーを段階的に構築する実装手順をご紹介します。
CData Sync はデータの抽出・ロード(EL)に加えて、変換機能から dbt Core を直接呼び出すことができます。これにより、EL から T(Transform)までを CData Sync のパイプラインとして一元管理でき、スケジュール実行や実行履歴の確認も CData Sync の画面上で完結します。
メダリオンアーキテクチャとは
メダリオンアーキテクチャは、データレイクハウスにおけるデータ設計パターンです。データを Bronze、Silver、Gold の 3 つのレイヤーに分けて段階的に品質を向上させます。
レイヤー | 役割 | データの状態 | 本記事での担当 |
|---|
Bronze | ソースからの生データ取り込み | 未加工・そのまま | CData Sync ジョブ |
Silver | クレンジング・正規化 | 型変換・NULL除外・フィルタリング済み | dbt Core モデル |
Gold | ビジネスロジック・集計 | 分析・レポート用に最適化 | dbt Core モデル |
各レイヤーを明確に分離することで、データの追跡可能性(リネージ)が向上し、問題発生時の原因特定や再処理が容易になります。
dbt とは
dbt(data build tool)は、データウェアハウス(DWH)内でのデータ変換に特化したツールです。データエンジニアリングにおける「ELT」プロセスの「T(変換)」を担います。最大の特徴は、SQLを用いてデータ変換処理を記述しつつ、ソフトウェア開発のベストプラクティス(Gitによるバージョン管理、テストの自動化、CI/CDなど)をデータ分析の世界に持ち込める点です。これにより、データの依存関係を自動で管理し、品質が担保された再利用可能なデータモデルを効率的に構築できます。CData Sync では変換機能と dbt を統合することができ、これによりデータの取り込み(EL)から dbt による変換(T)まで一元管理が可能となっています。本記事ではローカル環境で動作する dbt Core を用いて環境を構築していきます。
今回の構成
今回は PostgreSQL に格納された販売データを DWH である Snowflake へ連携します。CData Sync + dbt で Snowflake に Bronze、Silver、Gold の3つのレイヤーを構築するデータパイプラインを実装していきます。
全体アーキテクチャ

検証環境
本記事では以下の環境で検証しています。
サンプルデータの準備(PostgreSQL)
本記事では、販売データとして PostgreSQL に以下の 4 テーブルを作成し、サンプルデータを投入します。
テーブル作成
CREATE TABLE customers (
customer_id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
email VARCHAR(255),
region VARCHAR(50),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE products (
product_id SERIAL PRIMARY KEY,
name VARCHAR(200) NOT NULL,
category VARCHAR(100),
price NUMERIC(10, 2) NOT NULL
);
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
customer_id INTEGER REFERENCES customers(customer_id),
order_date DATE NOT NULL,
status VARCHAR(20) DEFAULT 'pending'
);
CREATE TABLE order_items (
item_id SERIAL PRIMARY KEY,
order_id INTEGER REFERENCES orders(order_id),
product_id INTEGER REFERENCES products(product_id),
quantity INTEGER NOT NULL,
unit_price NUMERIC(10, 2) NOT NULL
);
サンプルデータ投入
-- 顧客データ
INSERT INTO customers (name, email, region) VALUES
('Sample 太郎', '[email protected]', '関東'),
('Sample 花子', '[email protected]', '関西'),
('Sample 一郎', '[email protected]', '中部'),
('Sample 美咲', '[email protected]', '関東'),
('Sample 健太', '[email protected]', '九州'),
('Sample 裕子', NULL, '東北'),
('Sample 大輔', '[email protected]', '関西');
-- 商品データ
INSERT INTO products (name, category, price) VALUES
('ノートPC Pro', 'PC', 198000),
('ワイヤレスマウス', 'アクセサリ', 3500),
('USB-C ハブ', 'アクセサリ', 7800),
('モニター 27インチ', 'ディスプレイ', 45000),
('キーボード メカニカル', 'アクセサリ', 12000),
('ノートPC Standard', 'PC', 128000),
('Webカメラ HD', 'アクセサリ', 5500);
-- 注文データ
INSERT INTO orders (customer_id, order_date, status) VALUES
(1, '2025-01-15', 'completed'),
(2, '2025-01-18', 'completed'),
(1, '2025-01-20', 'completed'),
(3, '2025-02-01', 'completed'),
(4, '2025-02-05', 'cancelled'),
(5, '2025-02-10', 'completed'),
(2, '2025-02-14', 'completed'),
(6, '2025-02-20', 'pending'),
(7, '2025-03-01', 'completed'),
(3, '2025-03-05', 'completed');
-- 注文明細データ
INSERT INTO order_items (order_id, product_id, quantity, unit_price) VALUES
(1, 1, 1, 198000),
(1, 2, 2, 3500),
(2, 4, 1, 45000),
(2, 5, 1, 12000),
(3, 3, 3, 7800),
(4, 6, 2, 128000),
(5, 1, 1, 198000),
(6, 7, 5, 5500),
(7, 2, 1, 3500),
(7, 3, 1, 7800),
(8, 4, 2, 45000),
(9, 1, 1, 198000),
(9, 5, 2, 12000),
(10, 6, 1, 128000),
(10, 2, 3, 3500);
CData Sync 設定 — Bronze レイヤーへのデータ取り込み
接続設定
CData Sync の管理画面から、PostgreSQL とSnowflake の接続をそれぞれ作成します。
PostgreSQL 接続
画面左側の「接続」→「接続を追加」から PostgreSQL を選択し、Server、Port、Database、User、Password を入力して「作成およびテスト」で接続を確認します。設定の詳細はヘルプページを参照してください。
Snowflake 接続
同様に「接続を追加」から Snowflake を選択し、URL、Warehouse、Database、認証情報を設定します。設定の詳細はヘルプページを参照してください。
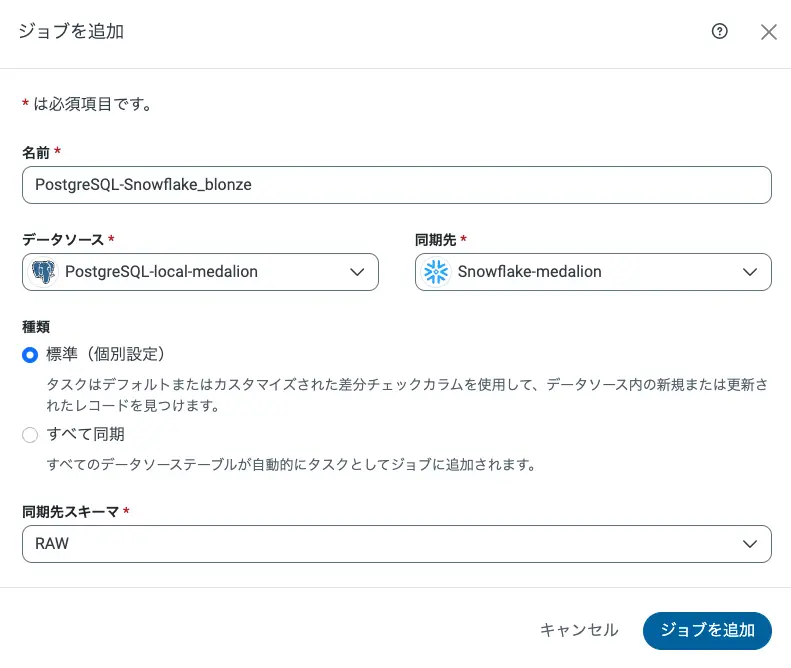
ジョブ作成
「ジョブ」→「ジョブを追加」から以下の設定でジョブを作成します。
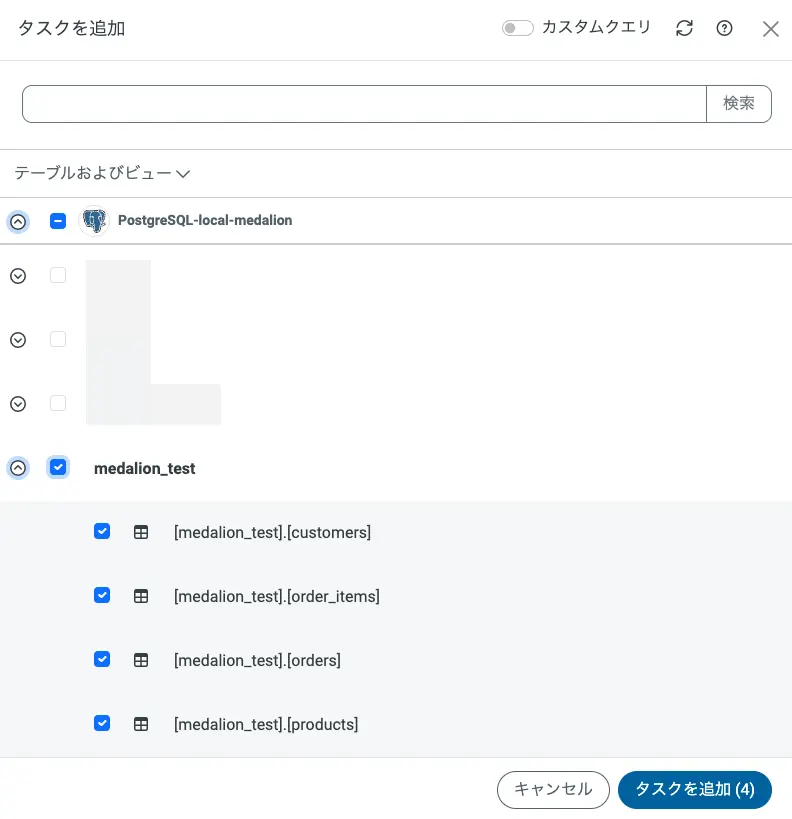
「タスク」タブに移動し、以下の 4 テーブルをタスクとして追加します。
customers
products
orders
order_items
dbt Core の導入と設定
dbt Core のインストール
CData Sync がインストールされたマシンに dbt Core と Snowflake アダプタをインストールします。CData Sync の実行ユーザで次のコマンドを実行します。
pip install --user dbt-snowflake
インストール後、バージョンを確認します。
~/.local/bin/dbt --version
dbt プロジェクトの初期化
以下のようなコマンドで dbt プロジェクトを作成します。
~/.local/bin/dbt init medallion_project
実行時に dbt で使用する Database を聞かれるので 1 を入力し Snowflake を選択します。
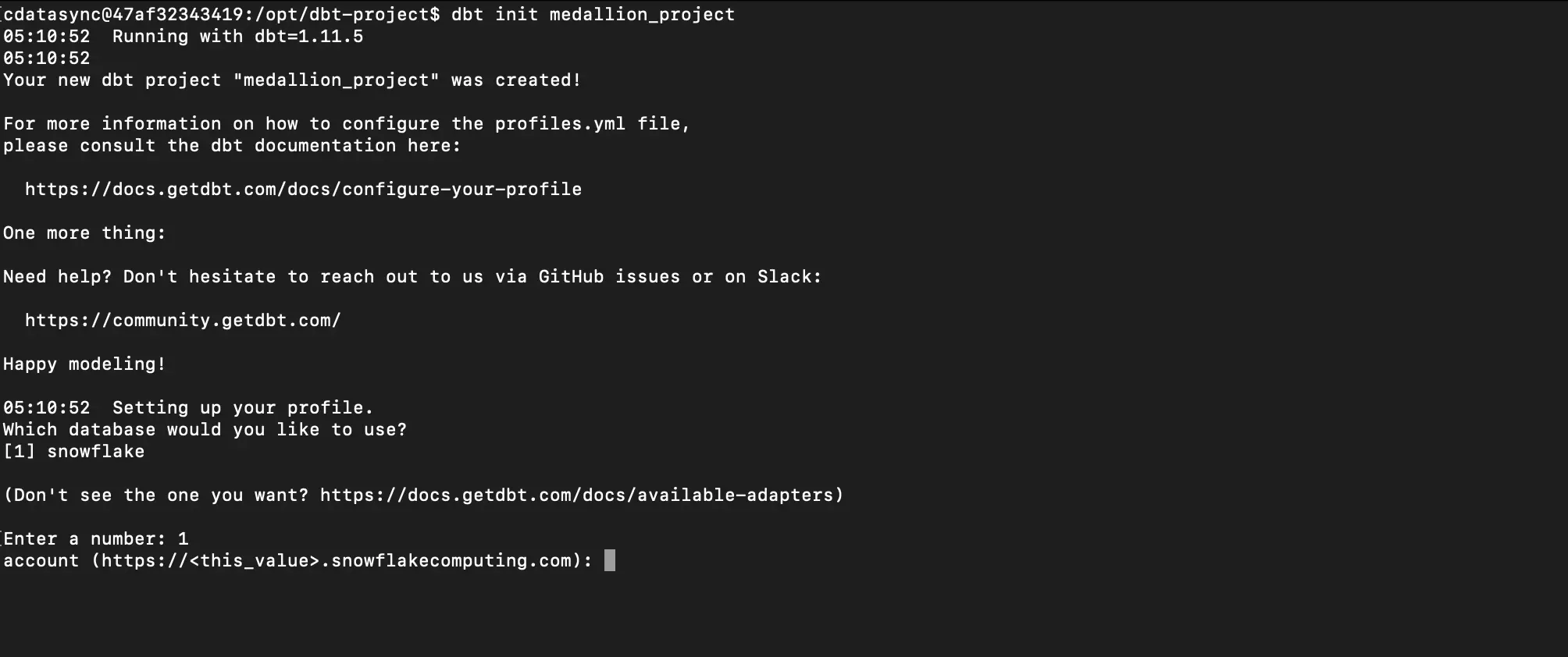
その後接続情報を聞かれるので入力していくとコマンドを実行したフォルダ直下に medallion_project というフォルダが作成されます。またこのとき入力した接続情報は ~/.dbt/profiles.yml に格納されています。誤りがあれば直接修正してください。
フォルダ構成
以下のフォルダ構成でモデルを作成していきます。
medallion_project/
├── dbt_project.yml
├── macros/
│ └── generate_schema_name.sql
├── models/
│ ├── silver/
│ │ ├── _silver_sources.yml
│ │ ├── slv_customers.sql
│ │ ├── slv_products.sql
│ │ ├── slv_orders.sql
│ │ └── slv_order_items.sql
│ └── gold/
│ ├── gld_customer_orders.sql
│ ├── gld_daily_revenue.sql
│ └── gld_product_performance.sql
dbt_project.yml の設定
dbt プロジェクトルートの dbt_project.yml を編集し、レイヤーごとのマテリアライゼーションとスキーマを設定します。
name: 'medallion_project'
version: '1.0.0'
profile: 'medallion_project'
model-paths: ["models"]
models:
medallion_project:
silver:
+materialized: table
+schema: silver
gold:
+materialized: table
+schema: gold
スキーマ名のカスタマイズ(generate_schema_name マクロ)
dbt のデフォルト動作では+schema で指定したスキーマ名に profiles.yml のデフォルトスキーマがプレフィックスとして付与されます。今回の設定だと raw_silverraw_gold というスキーマ名になってしまいます。
silvergold というスキーマ名をそのまま使いたい場合はmacros/generate_schema_name.sql を作成して、デフォルトの命名規則をオーバーライドします。
-- macros/generate_schema_name.sql
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- if custom_schema_name is none -%}
{{ target.schema }}
{%- else -%}
{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}
このマクロにより+schema: silver と指定したモデルは silver スキーマに+schema: gold と指定したモデルは gold スキーマに直接作成されます+schema を指定していないモデルは profiles.yml の schema(今回は raw)が使用されます。
dbt モデルの実装 — Silver レイヤー
Silver レイヤーでは、Bronze レイヤーの生データをクレンジング・正規化します。まず、Bronze レイヤーのテーブルを dbt の source として定義します。
Source 定義(_silver_sources.yml)
version: 2
sources:
- name: raw
schema: raw
tables:
- name: customers
- name: products
- name: orders
- name: order_items
slv_customers.sql — 顧客データのクレンジング
メールアドレスが NULL のレコードを除外し、リージョン名を標準化します。
WITH source AS (
SELECT * FROM {{ source('raw', 'customers') }}
)
SELECT
customer_id,
TRIM(name) AS customer_name,
LOWER(TRIM(email)) AS email,
region,
created_at::TIMESTAMP_NTZ AS created_at
FROM source
WHERE email IS NOT NULL
slv_products.sql — 商品データの正規化
カテゴリの表記ゆれを統一し、価格を数値型に明示変換します
WITH source AS (
SELECT * FROM {{ source('raw', 'products') }}
)
SELECT
product_id,
TRIM(name) AS product_name,
CASE
WHEN category IN ('PC', 'パソコン', 'コンピュータ') THEN 'PC'
WHEN category IN ('アクセサリ', 'アクセサリー', '周辺機器') THEN 'アクセサリ'
WHEN category IN ('ディスプレイ', 'モニター') THEN 'ディスプレイ'
ELSE category
END AS category,
price::NUMERIC(10, 2) AS price
FROM source
slv_orders.sql — 注文データのフィルタリング
キャンセル済みの注文を除外し、有効な注文のみを Silver レイヤーに残します。
WITH source AS (
SELECT * FROM {{ source('raw', 'orders') }}
)
SELECT
order_id,
customer_id,
order_date::DATE AS order_date,
status
FROM source
WHERE status != 'cancelled'
slv_order_items.sql — 注文明細データの加工
小計(subtotal)カラムを追加し、分析に必要な情報を付与します。
WITH source AS (
SELECT * FROM {{ source('raw', 'order_items') }}
),
valid_orders AS (
SELECT order_id FROM {{ ref('slv_orders') }}
)
SELECT
oi.item_id,
oi.order_id,
oi.product_id,
oi.quantity,
oi.unit_price::NUMERIC(10, 2) AS unit_price,
(oi.quantity * oi.unit_price)::NUMERIC(12, 2) AS subtotal
FROM source oi
INNER JOIN valid_orders vo ON oi.order_id = vo.order_id
slv_order_items は slv_orders を参照ref)しているため、dbt が依存関係を自動解決しslv_orders → slv_order_items の順で実行されます。
dbt モデルの実装 — Gold レイヤー
Gold レイヤーでは、Silver レイヤーのデータを集計・結合し、分析やレポートに直接使えるテーブルを作成します。
gld_customer_orders.sql — 顧客別注文サマリ
WITH customers AS (
SELECT * FROM {{ ref('slv_customers') }}
),
orders AS (
SELECT * FROM {{ ref('slv_orders') }}
),
order_items AS (
SELECT * FROM {{ ref('slv_order_items') }}
),
order_totals AS (
SELECT
o.order_id,
o.customer_id,
o.order_date,
SUM(oi.subtotal) AS order_total
FROM orders o
INNER JOIN order_items oi ON o.order_id = oi.order_id
GROUP BY o.order_id, o.customer_id, o.order_date
)
SELECT
c.customer_id,
c.customer_name,
c.email,
c.region,
COUNT(ot.order_id) AS total_orders,
COALESCE(SUM(ot.order_total), 0) AS total_revenue,
COALESCE(AVG(ot.order_total), 0) AS avg_order_value,
MIN(ot.order_date) AS first_order_date,
MAX(ot.order_date) AS last_order_date
FROM customers c
LEFT JOIN order_totals ot ON c.customer_id = ot.customer_id
GROUP BY c.customer_id, c.customer_name, c.email, c.region
gld_daily_revenue.sql — 日別売上集計
WITH orders AS (
SELECT * FROM {{ ref('slv_orders') }}
),
order_items AS (
SELECT * FROM {{ ref('slv_order_items') }}
)
SELECT
o.order_date,
COUNT(DISTINCT o.order_id) AS order_count,
SUM(oi.subtotal) AS daily_revenue,
SUM(oi.quantity) AS total_items_sold
FROM orders o
INNER JOIN order_items oi ON o.order_id = oi.order_id
GROUP BY o.order_date
ORDER BY o.order_date
gld_product_performance.sql — 商品別パフォーマンス
WITH products AS (
SELECT * FROM {{ ref('slv_products') }}
),
order_items AS (
SELECT * FROM {{ ref('slv_order_items') }}
)
SELECT
p.product_id,
p.product_name,
p.category,
p.price AS list_price,
COALESCE(SUM(oi.quantity), 0) AS total_quantity_sold,
COALESCE(SUM(oi.subtotal), 0) AS total_revenue,
COALESCE(COUNT(DISTINCT oi.order_id), 0) AS order_count
FROM products p
LEFT JOIN order_items oi ON p.product_id = oi.product_id
GROUP BY p.product_id, p.product_name, p.category, p.price
ORDER BY total_revenue DESC
CData Sync の変換設定(dbt Core 連携)
ここまでで dbt プロジェクトの準備が完了しました。次に、CData Sync の 変換機能を使って dbt Core を統合し、Bronze → Silver → Gold の変換を自動化します。
dbt Core Transformation の作成
CData Sync の管理画面から「変換」→「変換を追加」をクリックし、以下の設定で変換を作成します。
名前: 任意(例 dbt_medallion_transformation)
種類: dbt Core (※dbt Core を選択するためには先に同期先を選択する必要があります)
同期先: Snowflake 接続を選択
プロジェクトフォルダ: ローカルを選択
フォルダパス: 先程作成したプロジェクトフォルダのパスを指定

パイプラインの構成
CData Sync のパイプライン機能を使い、ジョブ(Bronze 投入)と 変換(Silver/Gold 生成)を順番に実行するワークフローを構成します。「Pipelines」→「Add Pipeline」からパイプラインを作成し、作成したジョブ・変換をそれぞれ以下の順序でステップを追加します。
ステップ 1 ジョブ postgres_to_snowflake_bronze(PostgreSQL → Snowflake raw スキーマ)
ステップ 2 変換 dbt_medallion_transformation(dbt Core による Silver/Gold レイヤー生成)
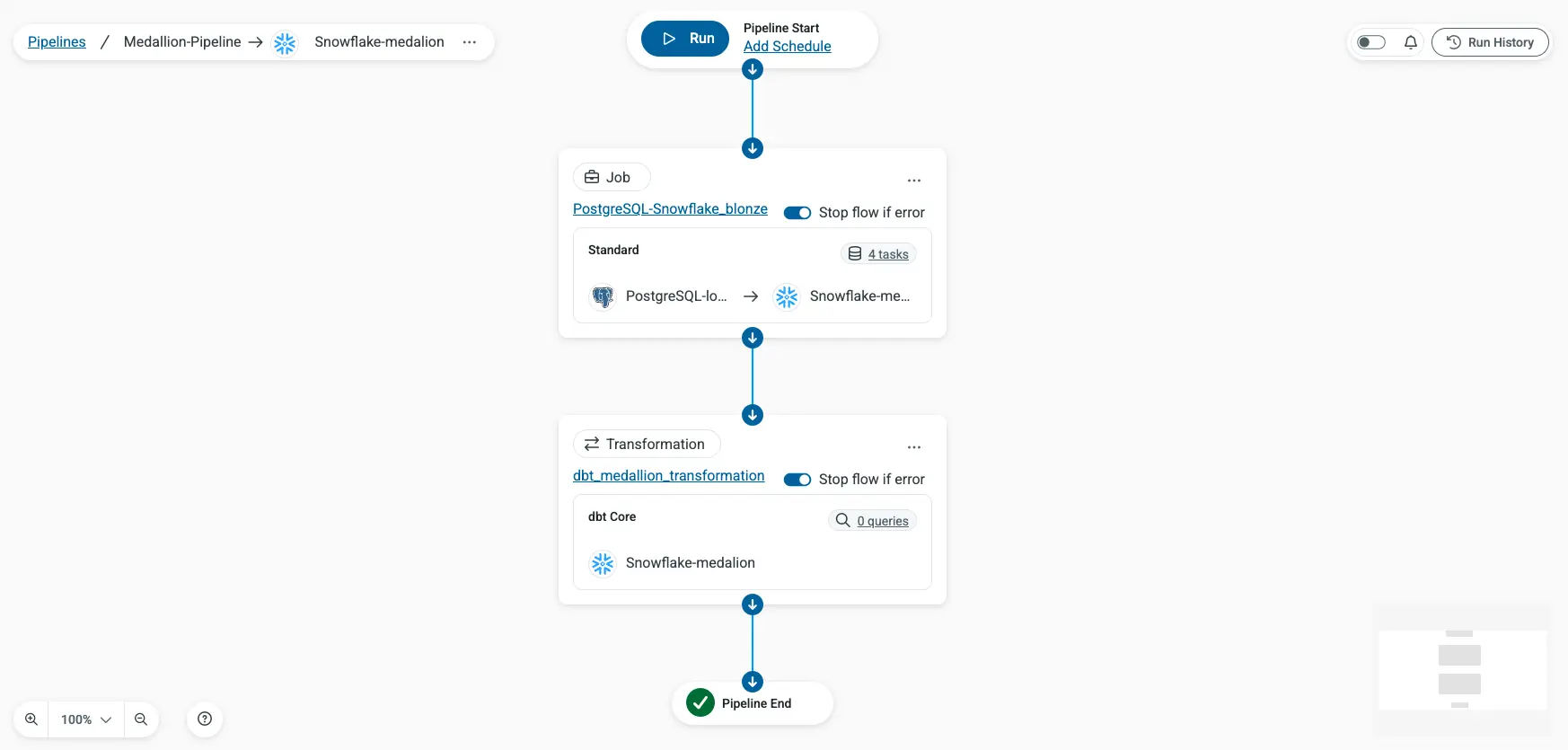
パイプライン実行
設定が完了したら、パイプラインの「Run」ボタンをクリックして、全ステップを順次実行します。
結果確認
パイプライン実行後、Snowflake 上の各スキーマにテーブルが作成されていることを確認します。
スキーマとテーブルの一覧確認
-- Bronze レイヤー(raw スキーマ)
SHOW TABLES IN SCHEMA raw;
-- Silver レイヤー(silver スキーマ)
SHOW TABLES IN SCHEMA silver;
-- Gold レイヤー(gold スキーマ)
SHOW TABLES IN SCHEMA gold;
Gold レイヤーのデータ確認
最終的に BI ツールなどから参照する Gold レイヤーのデータをそれぞれ確認してみましょう。
-- 顧客別売上 TOP 10
SELECT
customer_name,
region,
total_orders,
total_revenue,
avg_order_value
FROM gold.gld_customer_orders
ORDER BY total_revenue DESC
LIMIT 10;

-- 日別売上推移
SELECT
order_date,
order_count,
daily_revenue
FROM gold.gld_daily_revenue
ORDER BY order_date;

-- 商品別パフォーマンス
SELECT
product_name,
category,
total_quantity_sold,
total_revenue
FROM gold.gld_product_performance
ORDER BY total_revenue DESC;
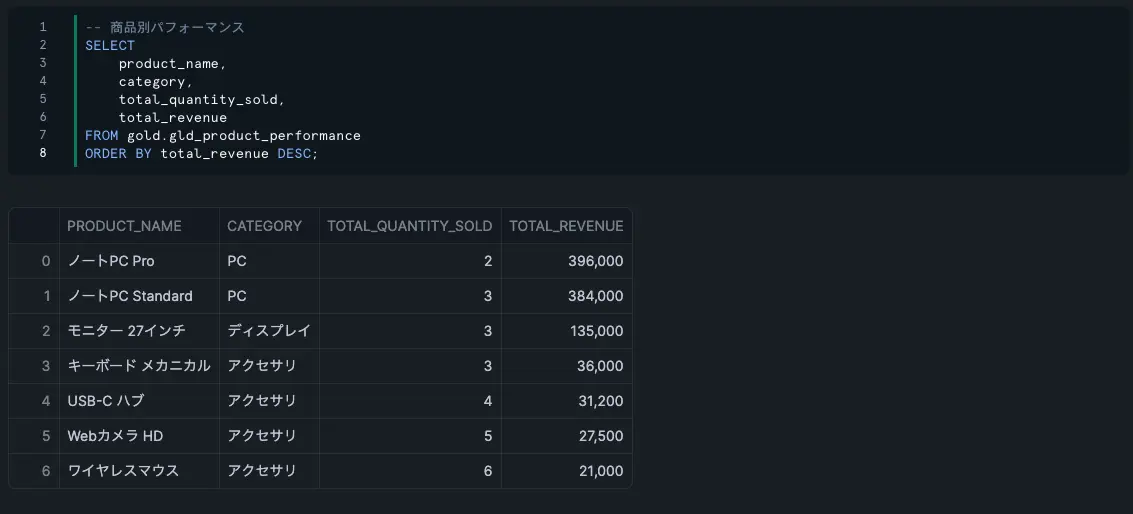
Bronze レイヤーの生データから、Silver で品質を向上させ、Gold で分析に適した形に加工されていることが確認できます。
まとめ
本記事では、CData Sync と dbt Core を組み合わせてメダリオンアーキテクチャを構築する方法を解説しました。この構成により、データの品質を段階的に向上させながら、コードベースで管理可能な ELT パイプラインを実現できます。dbt のモデルは SQL で記述するため、データエンジニアだけでなくアナリストにも扱いやすく、Git によるバージョン管理やコードレビューも可能です。CData Sync の 30 日間無償トライアルはこちらからダウンロードいただけます。ご不明な点があれば、お気軽にテクニカルサポートまでお問い合わせください。





