こんにちは。CData Software Japan の色川です。
先日公開した「こちらの記事」では、CData Connect AI とCData API Server を組み合わせることで、AI からオンプレミスデータアクセスを「よりコントローラブルに実現する」方法をご紹介しました。
一方で、業種業界で求められる規制要件やデータ主権(データソブリンティ)の観点から、業務でのAI 活用を検討する際に「外部のクラウドサービスを一切経由させたくない」「すべてを社内ネットワーク内で完結させたい」という制約下での「AI からのデータアクセス」についてご相談をいただく場面も増えてきました。この記事では「社内ネットワーク完結が必須要件なシーン」で「AI データアクセスの基盤としてCData API Server を活用する方法」について、セルフホスティング可能なAI ワークフローツールであるn8n とローカルLLM を組み合わせた構成パターンを例にご紹介します。
この記事の狙い(背景)
総務省の調査によると、生成AI の活用方針を定めている国内企業の割合は他の国と比べて大幅に低い傾向が続いています。「生成AI 導入に際しての懸念事項」も他の国々がコストを最も懸念する中、日本においてはセキュリティリスクがより上位に挙がっているのが特徴的です。特に規制の厳しい業種業界において「AI 活用におけるセキュリティリスク」は単なる懸念ではなく、明確な制約条件として掲げられることも多いのではないでしょうか。金融・医療・公共・防衛・社会インフラ・製造研究開発といった領域では「機密性の高い情報については、推論プロセスも含めて社内ネットワーク内で完結させる」という選択をされる場面が、構造的に増えてきているかとも思います。この記事では、このような「社内ネットワーク完結でのAI 活用」を検討される場面において「AI データアクセスの基盤としてCData API Server を活用する方法」をご紹介します。
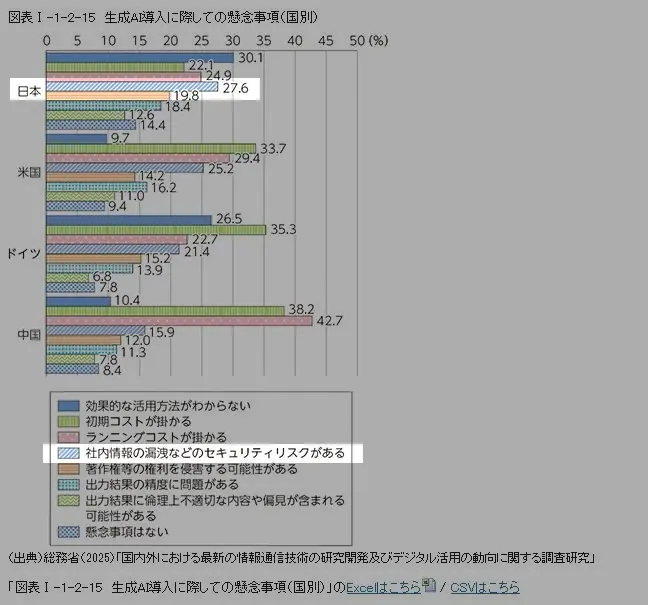
参考: 総務省「令和7年版 情報通信白書」
CData API Server
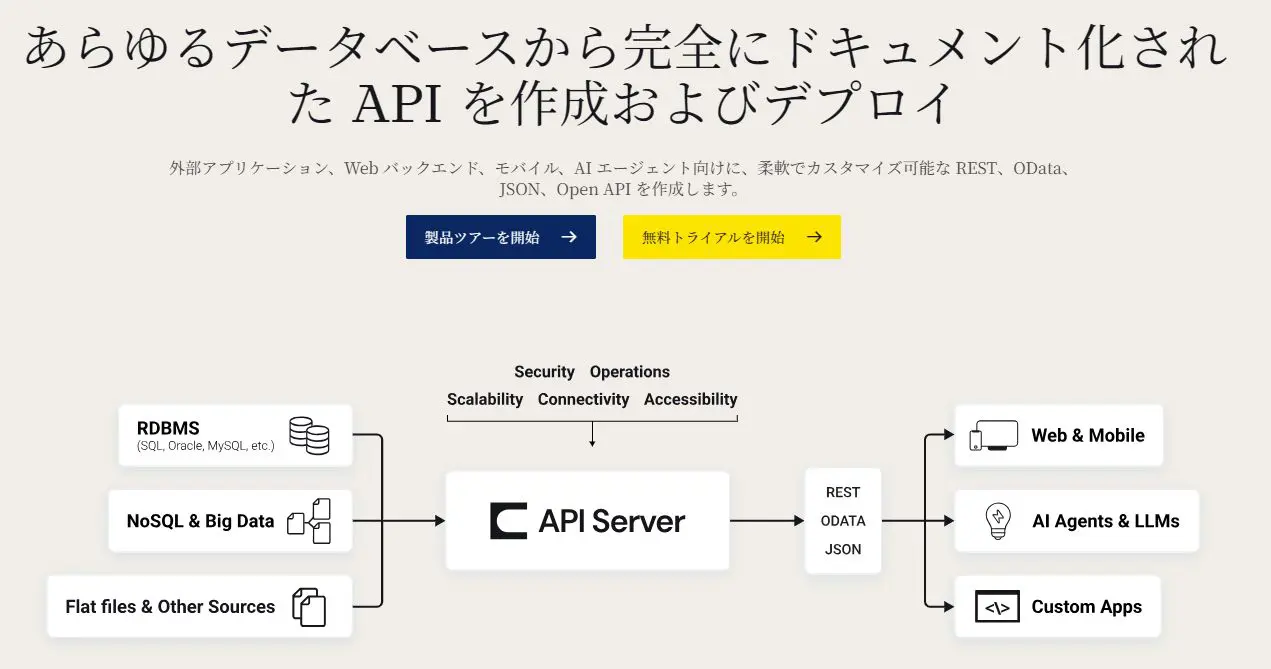
この記事でご紹介する「CData API Server」は「あらゆるデータソースから完全にドキュメント化されたAPI を作成およびデプロイ」できるサーバーアプリケーションです。外部アプリケーション、Web バックエンド、モバイル、AI エージェント向けに、柔軟でカスタマイズ可能なOData 準拠のAPI をノーコードで開発・運用することができます。API の「開発」のみならず、公開から運用・保守にいたるまでAPI 基盤として必要となる機能を備えています。
CData API Server の主な特徴や機能は以下のとおりです。
豊富な対応データソース : 270 を超える業務データソース(RDB、SaaS、ファイル系など豊富なデータソース)に対応
スキーマカスタマイズ : テーブル名・カラム名の別名(エイリアス)、データ型の変換、APIScript による高度なマークアップ
API ガバナンス : ユーザー単位の認証・レート制限・アクセス制御(メソッド / オブジェクト / IP)・監査ログ
OData 準拠の標準API : クライアント側のツール選択肢が豊富、自動ドキュメント(OpenAPI 仕様)を提供
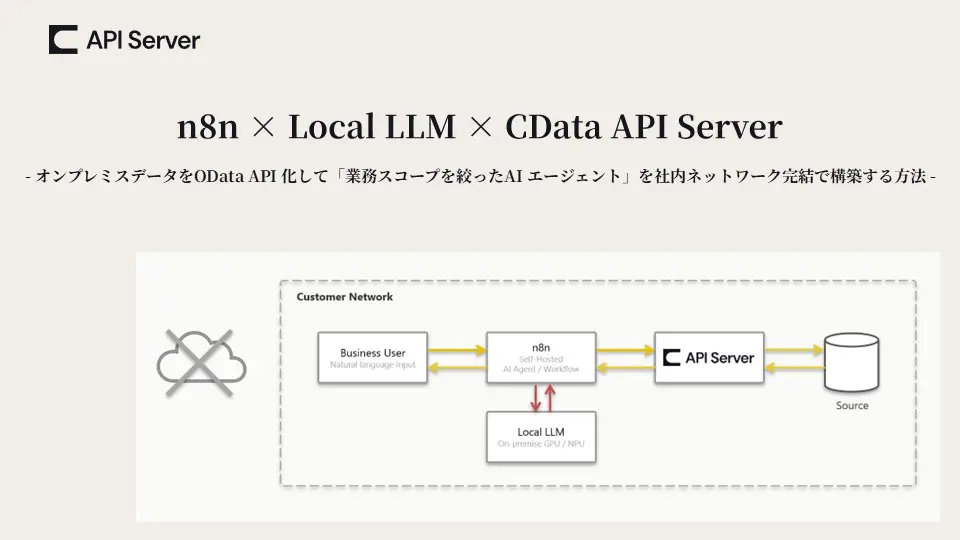
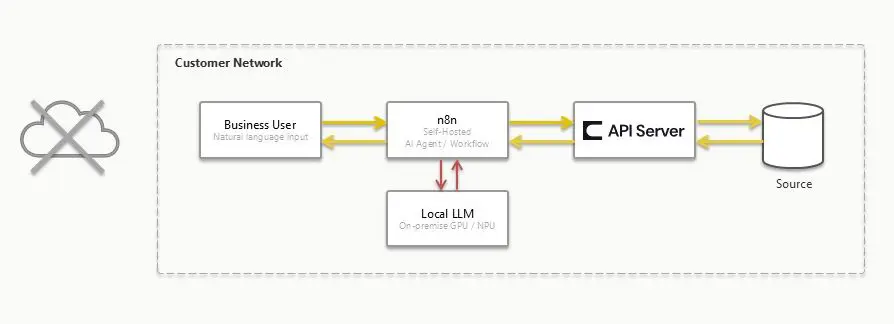
この記事の構成イメージ
「社内ネットワーク完結でのAI エージェント」を成立させるには、構成するすべてのコンポーネントが社内ネットワーク内で動いている必要があります。この記事では以下のイメージで構成しています。今回は社内ネットワークで完結する(外部ネットワークへの通信が発生しない)ことが最重要ポイントです。
この記事で実際に検証した環境は次のとおりです。
レイヤ | コンポーネント(バージョン) |
AI エージェント基盤 | n8n(2.19.2)セルフホスティング |
Local LLM | Ollama 経由 llama3.1:8b (OpenAI 互換 API として呼び出し) |
データアクセスAPI 基盤 | CData API Server(26.1.9595.0) |
データソース | Oracle Database 23ai |
この記事ではAI エージェント基盤としてn8n を利用しましたが、Dify を利用されているケースもよくご相談いただきます。またこの記事ではLocal LLM にはオープンウェイトのモデルを利用しましたが、実際の検討シーンでは閉域提供(ベンダーが個社専用のクラウド環境やオンプレミス機器で提供する形態)の商用LLM で検討されるケースも多いと思います。それぞれ概念的にはこの記事を読み替えて検討いただけると思います。
この記事のスコープ(Workflows / Agents)
Anthropic の「Building Effective Agents」では、LLM を活用したシステムを大きく2つに分類しています。LLM とツールが事前定義されたコードパスで動く「Workflows(以下、ワークフロー型)」と、LLM が自律的にプロセスとツール使用を制御する「Agents(以下、エージェント型)」です。
エージェント型と一口に言ってもその幅は広く、特に「ツールの作り方や使わせ方」で適用範囲や機能性が大きく変わります。この記事ではエージェント型を、業務文脈をあらかじめ作り込み、アクセス可能なデータを明示的に制限する「業務スコープを絞ったエージェント」と、LLM の自律性に任せ、データを自由に探索しながら任意のツール呼び出しを許可する「自由探索型エージェント」のように分けて整理していきます(エージェント型に対する分類は、この記事独自の整理です)。
この記事で主にご紹介するのは表中の「ワークフロー型」と「業務スコープを絞ったエージェント」です。業務の文脈を作り込みやすく、アクセス可能なデータを明示的に制限でき、コストやレイテンシも予測しやすいため、確実かつ堅牢にAI を活用したい規制の厳しい業種業界とも相性の良いアプローチだと思います。
# | ワークフロー型 | エージェント型
(業務スコープを絞ったエージェント) | エージェント型
(自由探索型エージェント) |
|---|
LLM の役割 | 固定(要約・分類・整形など) | ツール選択 + 引数生成 | ツール発見 + 多段の操作計画 |
|---|
利用ツール | 事前定義 / 順序も固定 | 文脈に合わせた数個〜十数個 | 実行時に動的に発見される多数のツール |
|---|
入力 | 定期実行 / 固定パラメータ | ユーザーの自然言語(業務範囲内) | ユーザーの自由な問い合わせ |
|---|
再現性 | 最も高い | 高い | 低い |
|---|
コスト・レイテンシ予測 | 最も容易 | 容易 | 困難 |
|---|
規制業界との相性 | ◎ | ○ | △ |
|---|
n8n x Local LLM x CData API Server での構成パターン
CData API Server 側での事前準備
この記事では、オンプレミス環境にあるOracle Database をCData API Server のデータソースとしました。API Server 側では、ユーザーを作成してAuth Token を発行し、AI に公開するリソース(テーブル、ビュー、ストアドプロシージャ)として必要なものだけを選択してAPI 化しておきます。エンドポイントは http://{host}:{port}/api.rsc/、OpenAPI 仕様は /api.rsc/$oas で取得できます。
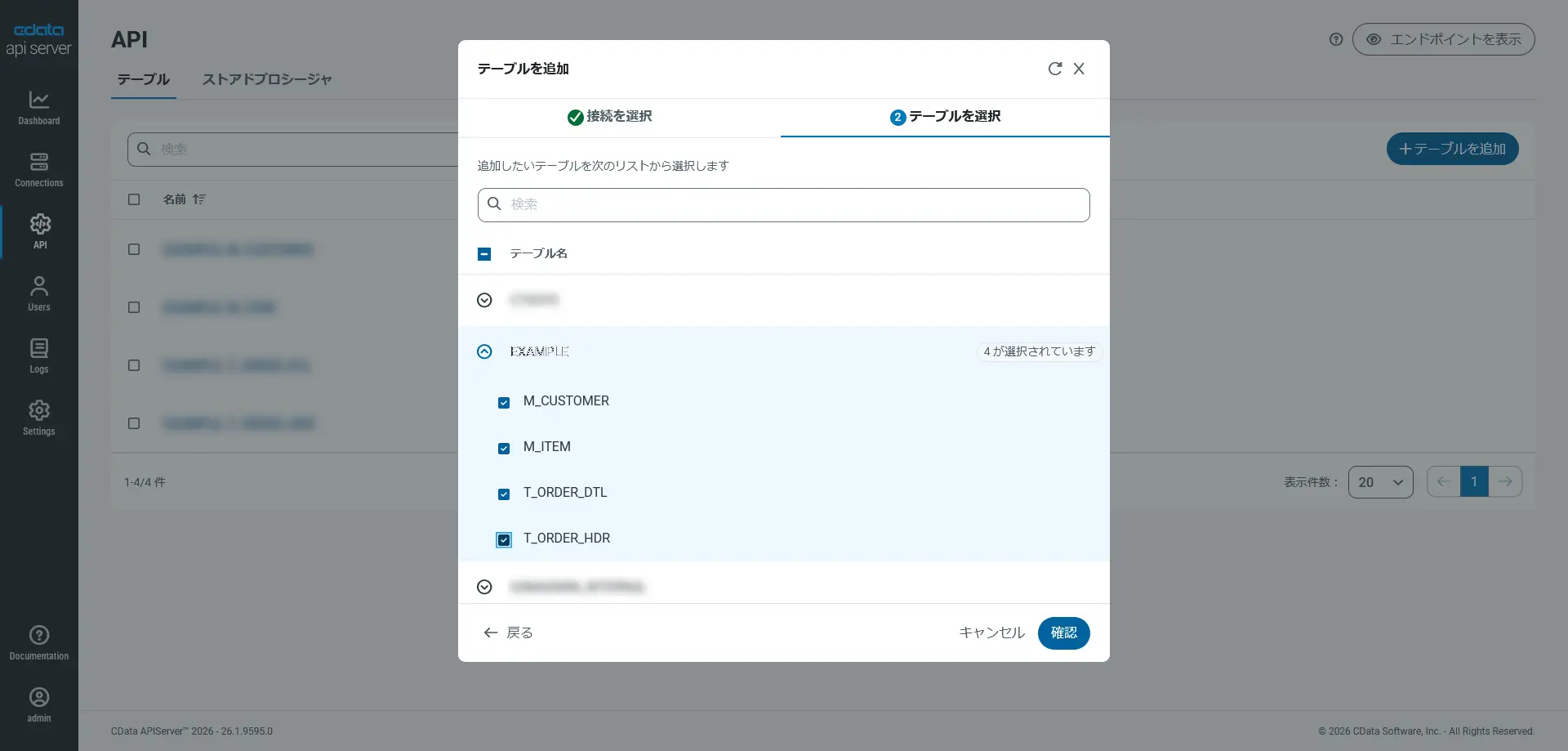
オンプレミスにある基幹システム、とくにスクラッチ開発アプリケーションのデータストア等においては、「XXX_MST」という略式的なオブジェクト名や「XXX_CD」や「XXX_FLG」「XXX_DT」などの略式的なカラム名で構成されているケースも多いかと思います。AI エージェントがこれらのメタデータをそのまま取得した場合、略式的な名称しか見えず、「最近の受注実績を教えて」と質問しても、どのカラムが受注日を表すのか判断に困るでしょう。うまく判断に至れる場合も「判断がしにくい」ことによって推論コストが高くつくことは容易に想像がつきます。API Server がサポートする「スキーマのカスタマイズ機能」を利用すると、エンドポイント(テーブル名)を分かりやすい名称に変更したり、カラム名に分かりやすい別名(エイリアス)を設定したり、データ型を明示的に変換したり、と「AI が文脈(Context)を理解しやすい形へ整える」ことができます。この記事でもエイリアスをつけて、AI フレンドリーなエンドポイントとなるように構成しました。
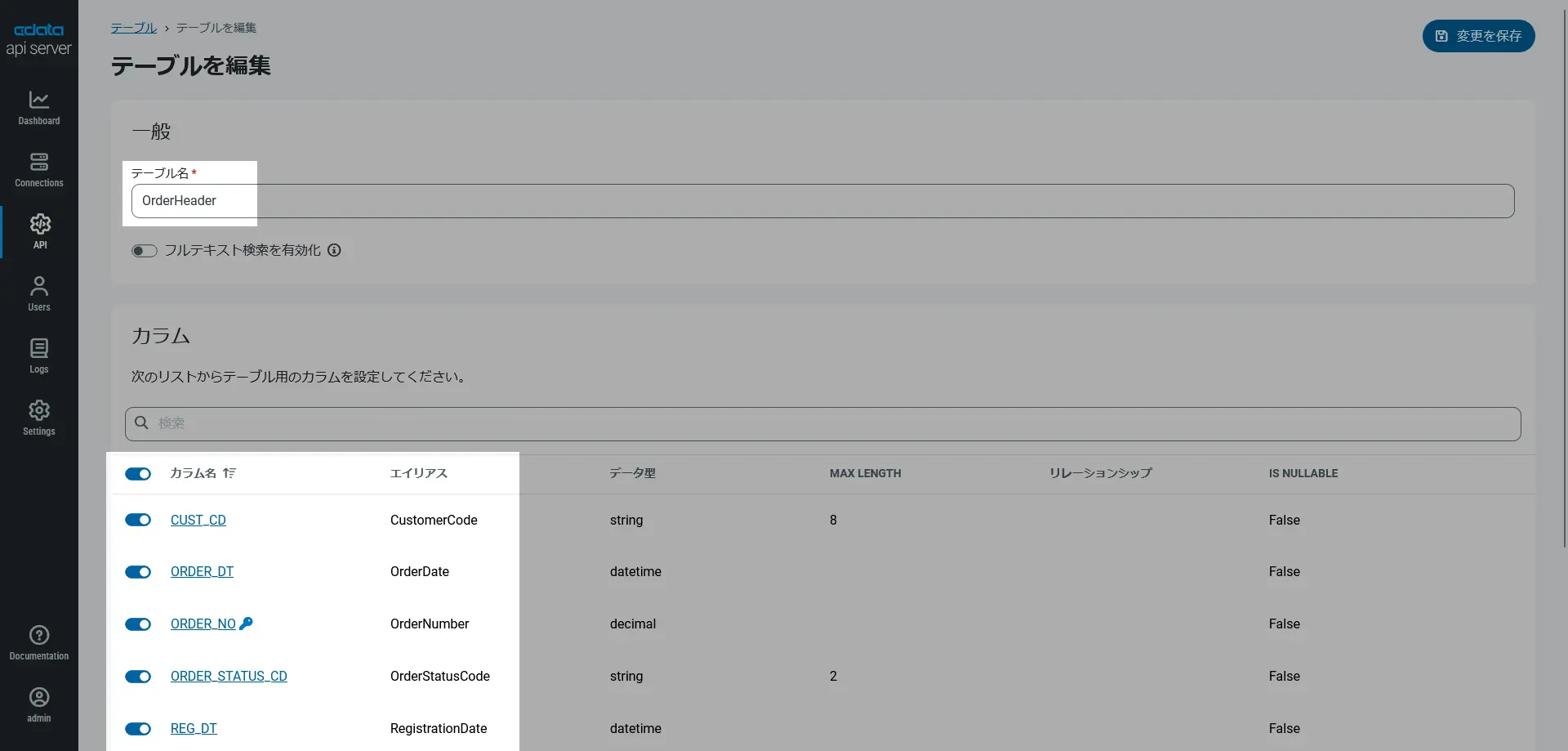
これでオンプレミスデータを AI エージェント基盤(n8n)から利用するためのAPI 化は完了です。
ここからは、AI エージェント基盤である n8n からのLLM の使い方(呼び出し方)について「ワークフロー型」と「業務スコープを絞ったエージェント型」のそれぞれで例を挙げて試していきます。それぞれの違いは「LLM にどこまで自由度を与えるか」の観点で整理できます。
A. ワークフロー型(ex. HTTP Request + LLM Chain)
このパターンは、毎朝のレポート生成や定期的なデータ取得のように「呼び出す内容と処理の順序が事前に決まっているケース」といえます。このケースにおいて、LLM はデータ処理のパイプラインの中で「要約・分類・整形」など固定の役割を担当し、ツール選択や引数生成のような自律的な判断は行いません。この「ワークフロー型」のパターンは「LLM の出番を限定し、入出力を明確に固定しやすい」構成と言えるでしょう。再現性とコスト予測性が高く、業務への導入も進めやすい構成です。
なお、このパターンは「Building Effective Agents」でのPrompt Chaining(前段の出力を次段のLLM に渡す線形的なパイプライン型ワークフロー)に該当します。Workflows のサブパターンの中でも最も基本的な構成です。
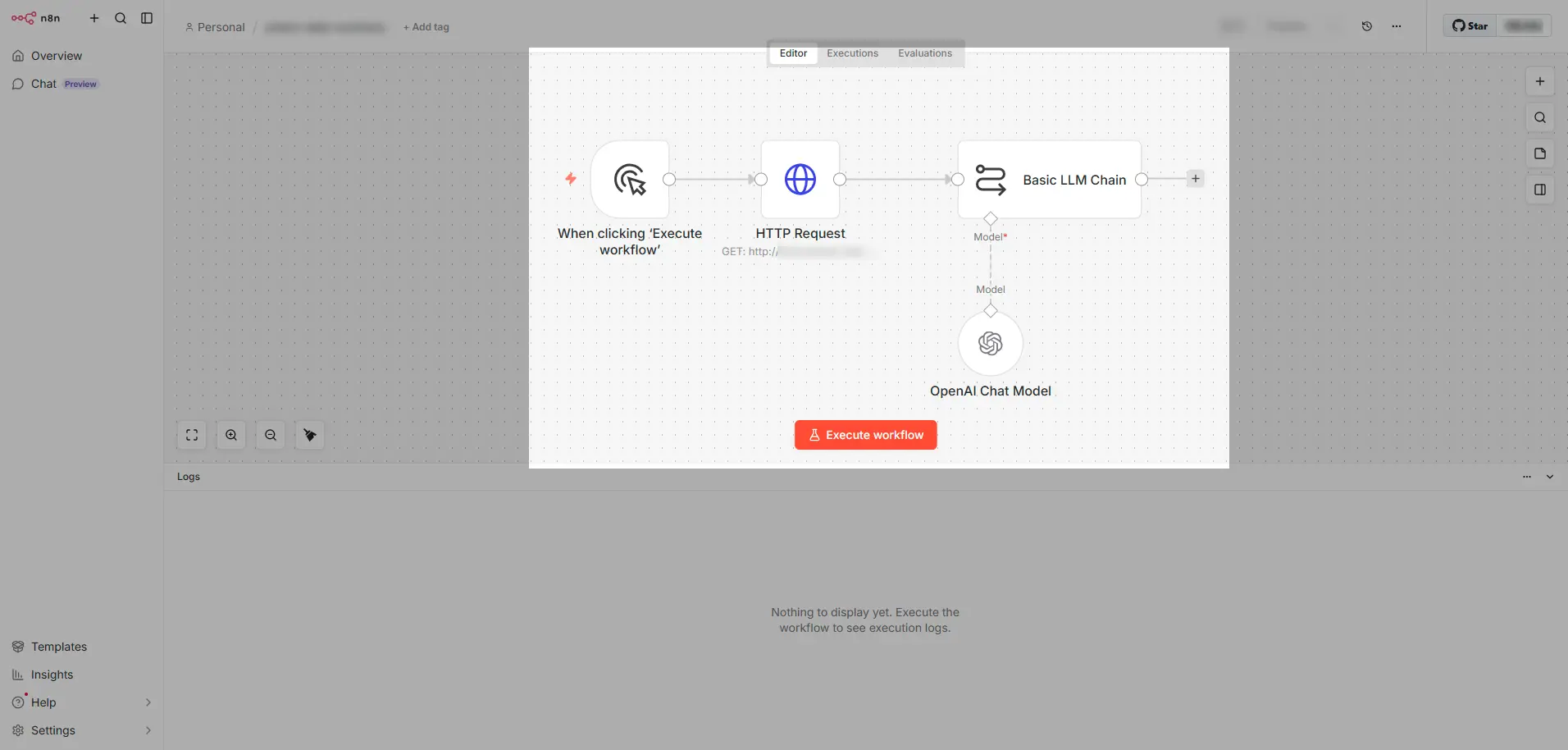
上記のn8n フロー構成を整理すると、以下のように役割分担と考えることができます。この構成の場合、LLM はツール選択や引数生成をせず、固定的な役割(要約)を担っています。
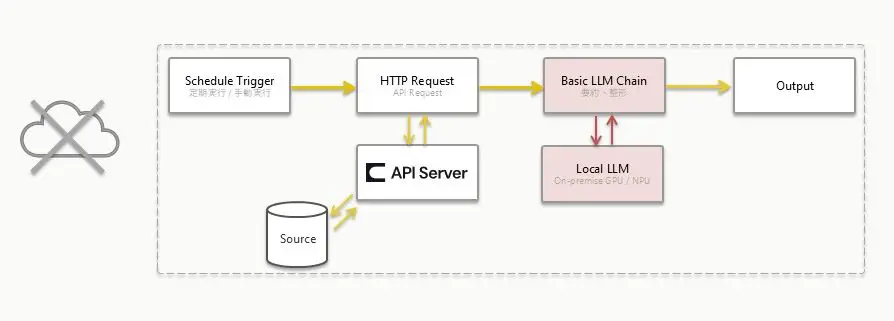
n8n フローを構成する各ノードの設定についても見ていきましょう。
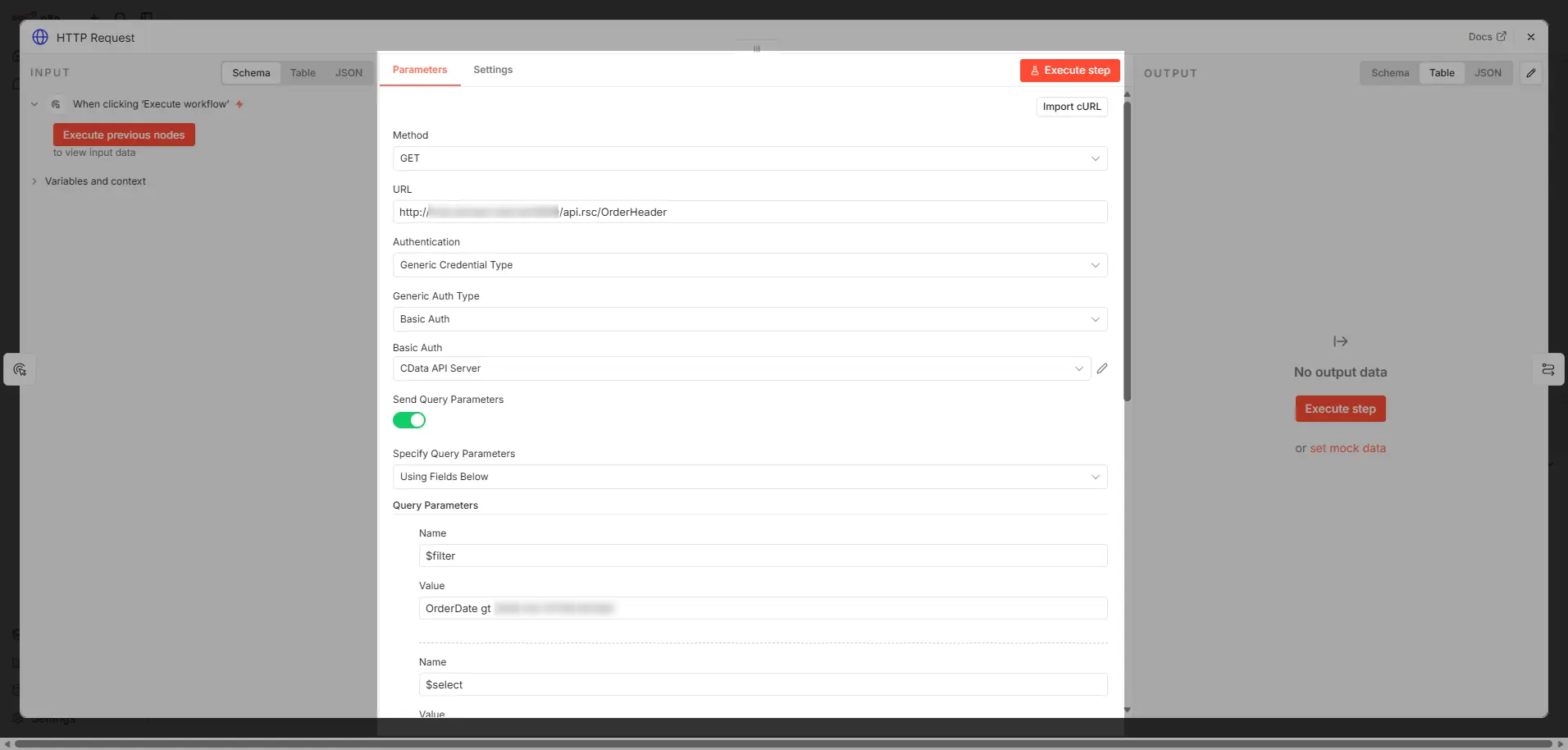
HTTP Request ノード(決定的な処理)
このフローでの「HTTP Request ノード」は「n8n フローで利用するデータをCData API Server から取得する事前決定的な処理」です。CData API Server が生成するOData 準拠のAPI であれば、n8n のHTTP Request ノードでシンプルに指定・取得することができます。この記事のイメージではクエリパラメータ構成も事前決定的であり、API Server 側のレート制限や監査ログも含め、非常にコントローラブルなデータアクセスになります。
Basic LLM Chain ノード(LLM が固定的な役割を担当)
つぎに「Basic LLM Chain ノード」に、ローカル LLM(OpenAI Chat Model 経由)をChat Model として接続します。このノードでは、HTTP Request ノードでの事前決定的な処理で得た出力(受注データ)をプロンプトに構成して、LLM に固定的な役割(要約や整形)を依頼します。
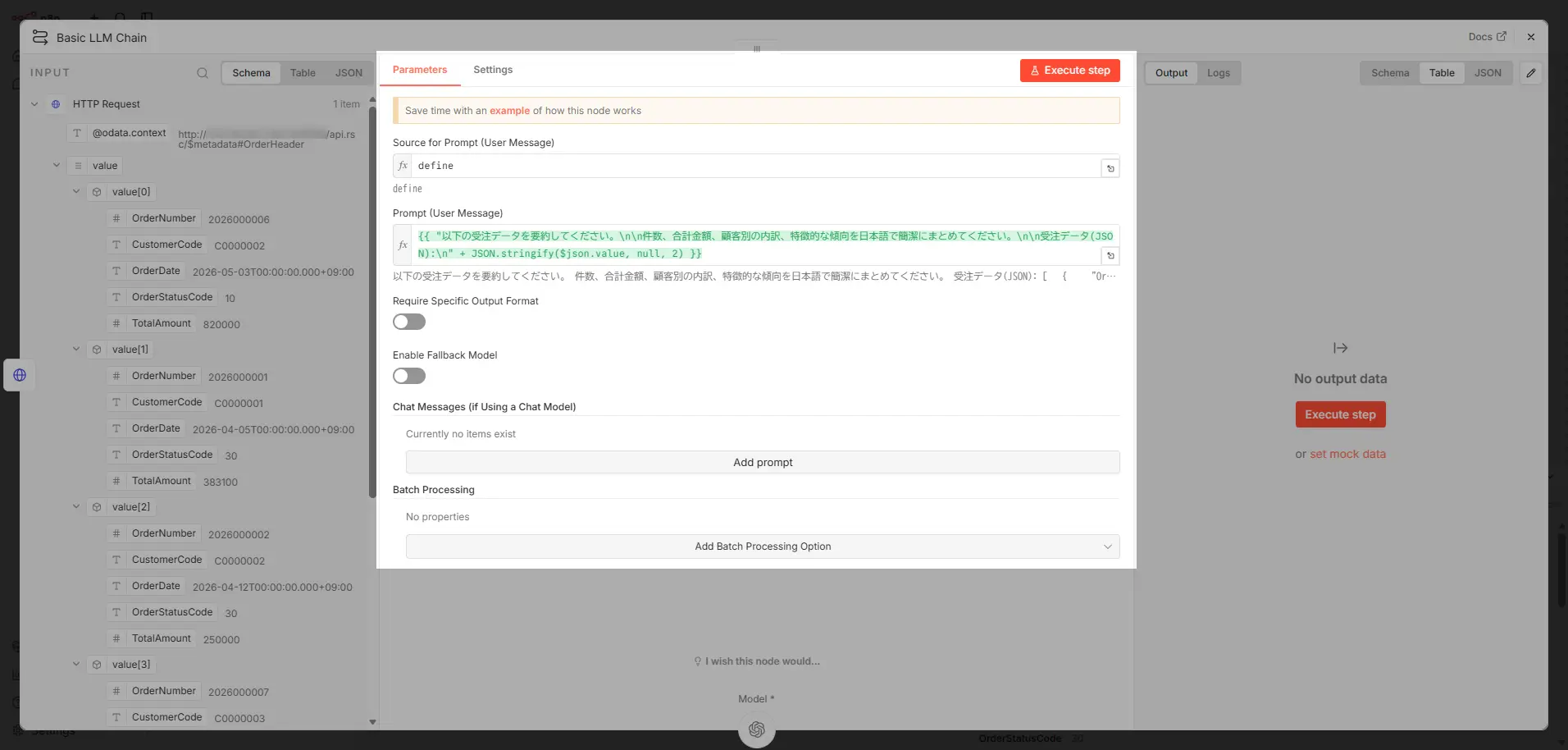
Prompt (User Message) 設定例: {{ "以下の受注データを要約してください。\n\n件数、合計金額、顧客別の内訳、特徴的な傾向を日本語で簡潔にまとめてください。\n\n受注データ(JSON):\n" + JSON.stringify($json.value, null, 2) }}
この例のような「ワークフロー型」では、LLM は与えられた受注データを要約するだけで、ツール呼び出しの判断は一切しない構成となっていることがイメージいただけると思います。AI 導入を検討する業務側の観点でみれば「AI が予期せぬデータアクセス(API Server を経由したクエリ)を発行することはない」と保証できますので、規制の厳しい業種業態においても導入を検討しやすいパターンです。
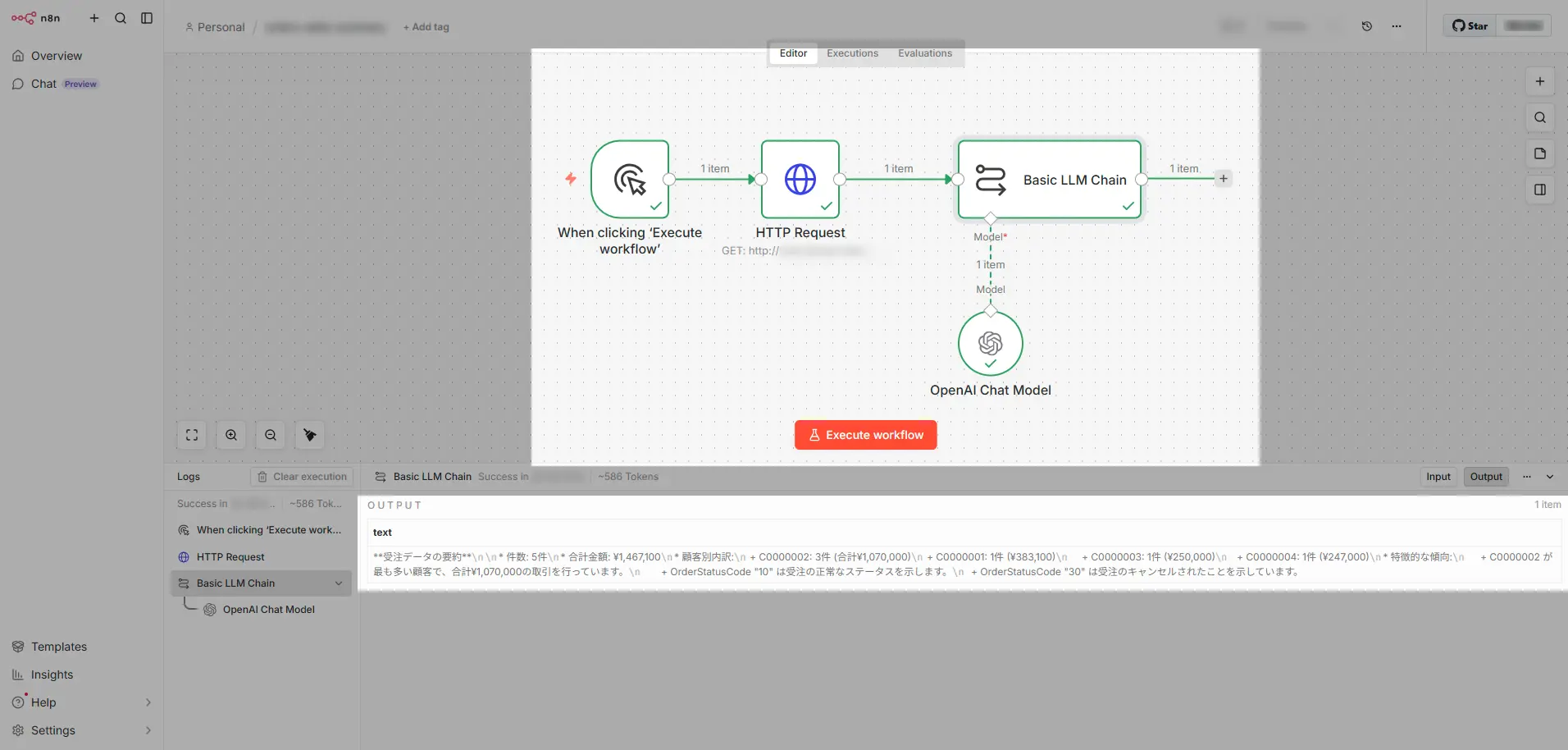
B. 業務スコープを絞ったエージェント型(ex. AI Agent + HTTP Request Tool)
このパターンは「ユーザーが自然言語で問い合わせる対話型エージェントを作るケース」といえます。このケースにおいて、LLM は事前定義されたツール群の中からユーザーの入力に応じて適切なものを選び、実行時の引数を動的に生成します。「エージェント型」の定義は幅広いですが、この記事で「業務スコープを絞ったエージェント型」と整理しているポイントは「AI が推論する境界をツール呼び出しの引数生成だけに閉じ込めている」ことです。n8n フローの実装としては、AI Agent ノードにHTTP Request Tool を接続し、リクエストパラメータの値だけをLLM に決めさせる構成にしています。
なお、このパターンは「Building Effective Agents」でのAgents の定義に該当しますが「利用可能ツールを業務の文脈に絞ることで予測可能性を高めた構成」です。
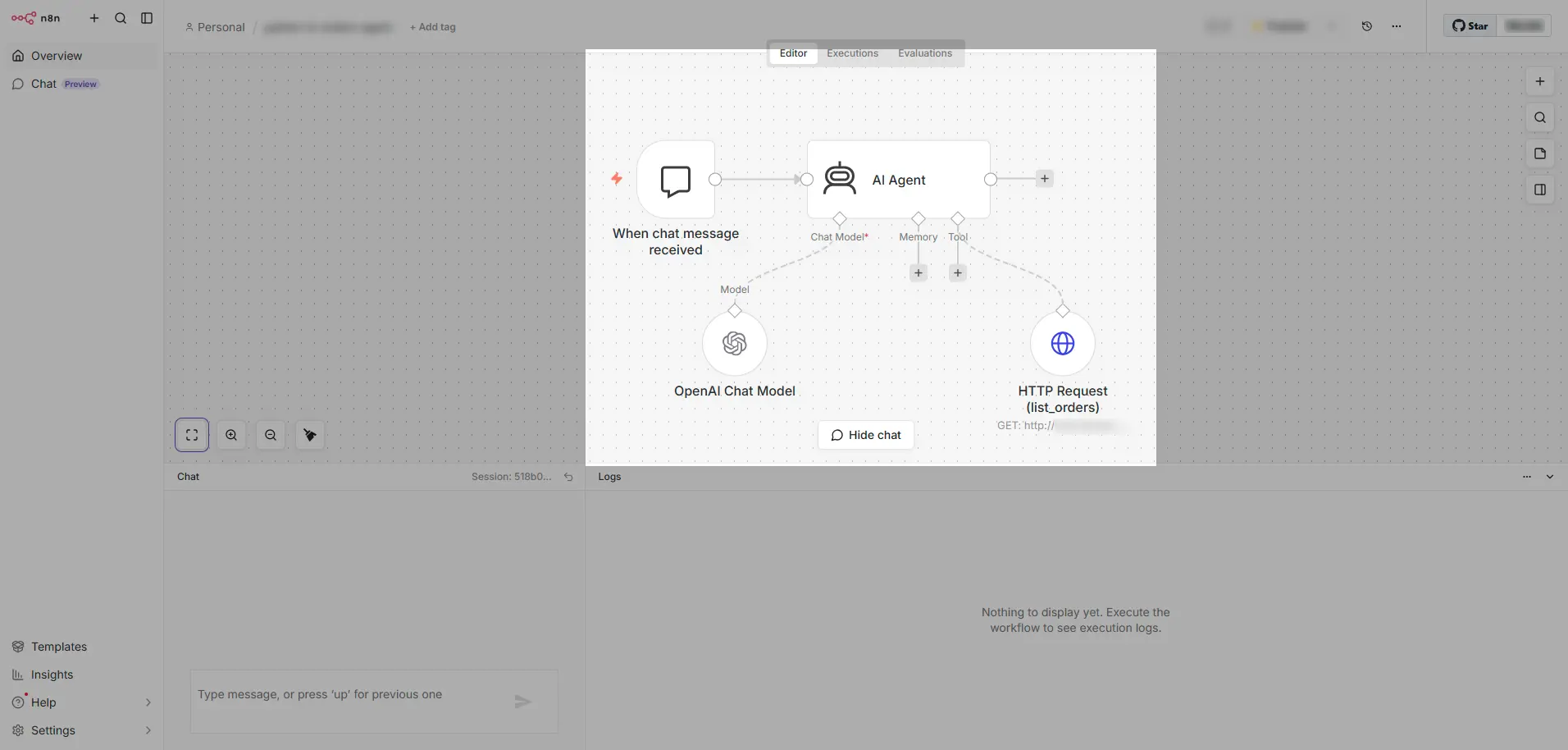
上記のn8n フロー構成を整理すると、以下のように役割分担と考えることができます。この構成の場合、AI Agent ノードがAI 推論の境界です。HTTP Request Tool のQuery Parameter のValue に構成した $fromAI() において、LLM が動的に値を生成して埋め込みます。
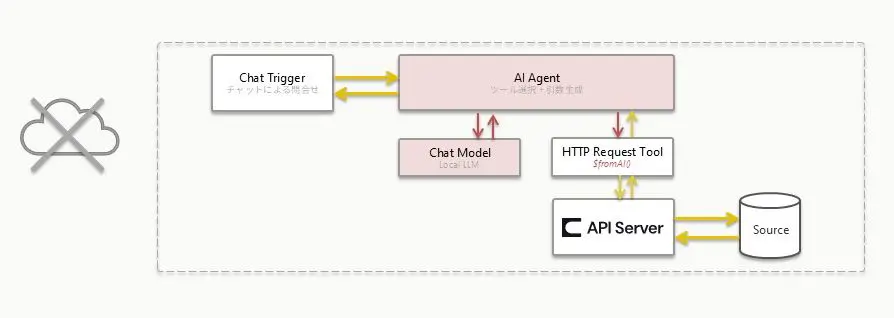
$fromAI() でのLLM による引数の生成
この記事では、HTTP Request Tool のDescription には以下のように設定しました。
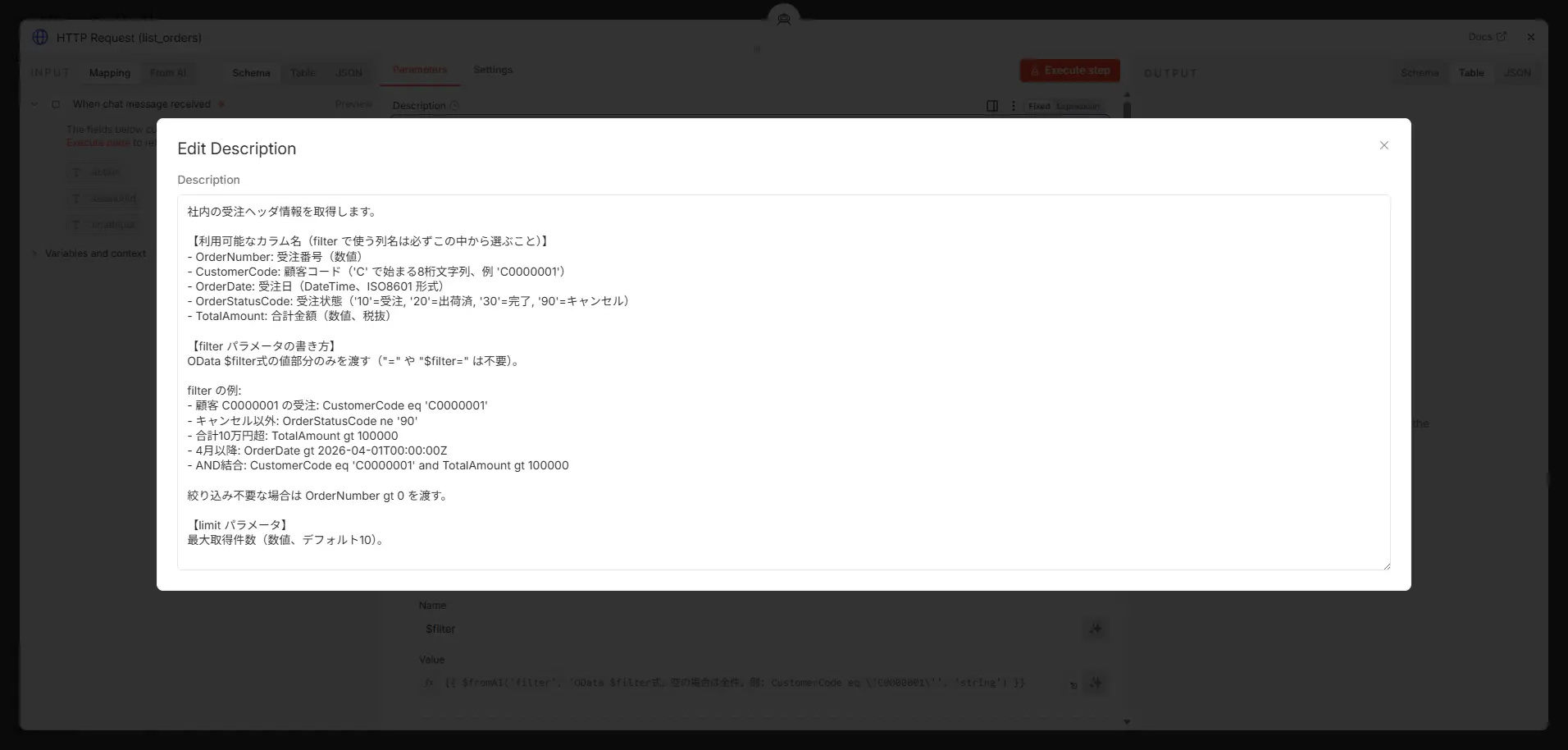
n8n における「$fromAI()」とは、AI エージェントが接続されたツール(Tools)のパラメータを動的に生成・入力するために使用する特別な関数(記述方法)です。「$fromAI()」の第一引数がパラメータ名、第二引数がLLM への説明、第三引数が型です。LLM はこの定義を関数のシグネチャとして認識し、ユーザーの自然言語入力から適切な値を生成します。
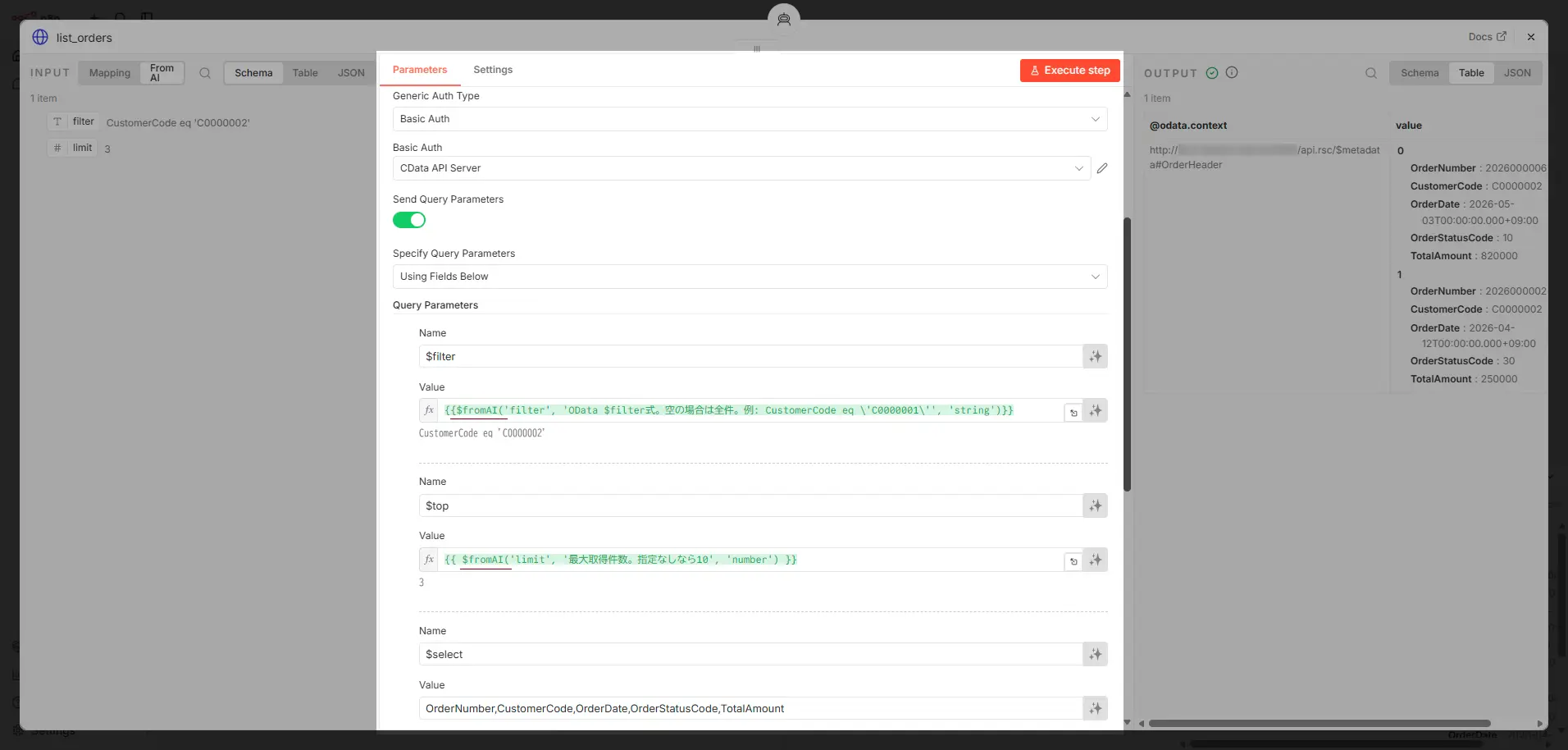
例えば、このフローの場合、ユーザーが「顧客 C0000001 からの1万円を超える受注をみせて」と入力すると、LLM が filter="CustomerCode eq 'C0000001' and TotalAmount gt 10000" と、(指定しない場合のデフォルト指示からlimit=10 を生成し(ここまでがAI 推論)、HTTP Request Tool がAPI Server を呼び(以降は決定的な処理)、結果をAI Agent に返します。
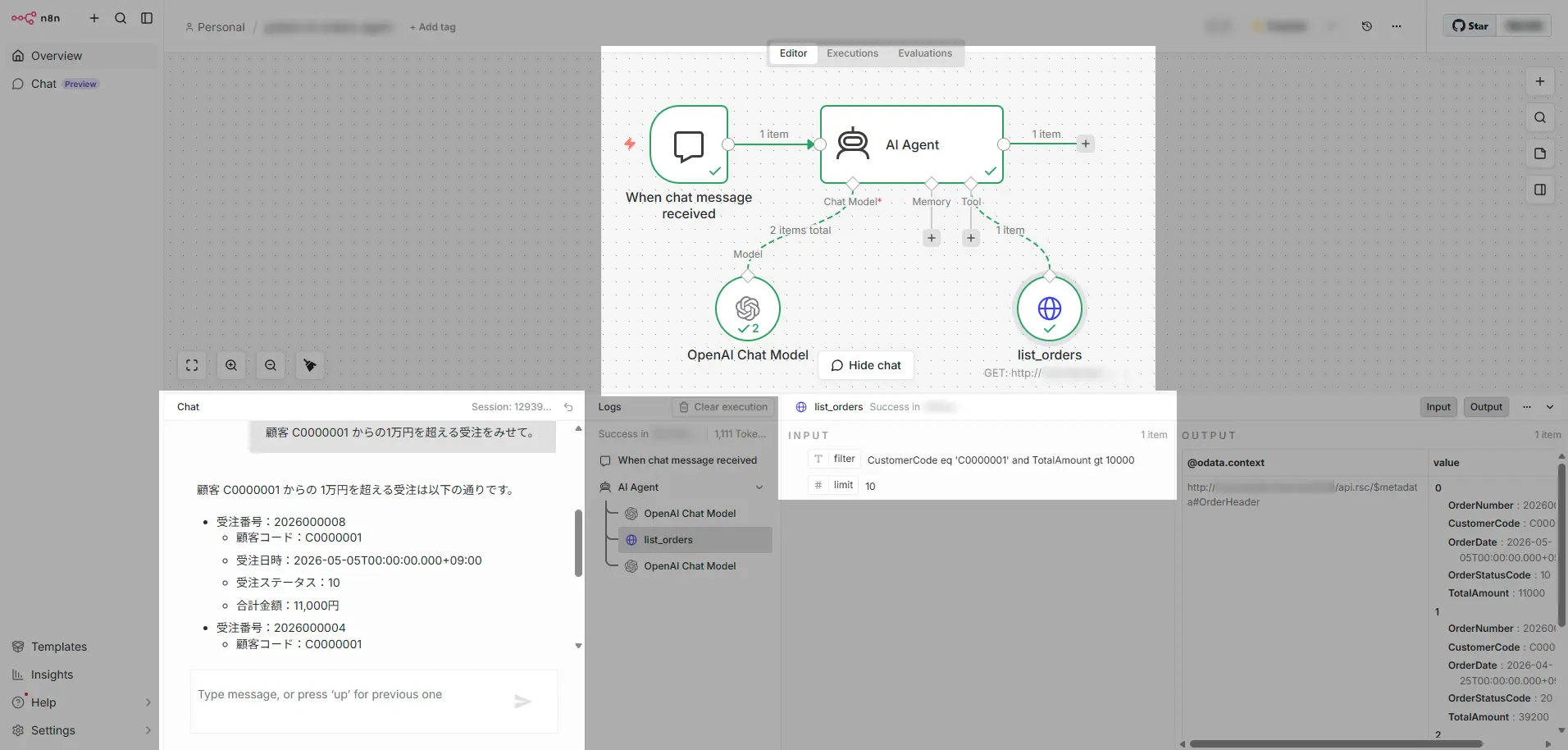
実際の業務運用においてはツールを複数(数個〜十数個程度)登録して構成するのが一般的かもしれません。たとえば「list_orders」に加えて「get_customer(顧客コードから顧客名)」、「list_items(商品一覧)」等をツールとして提供すると「最大金額の受注の顧客名を教えて」のような問い合わせに対して、LLM が複数のツールを連鎖的に呼ぶ「自律的な振る舞い」が現れます。これが Agents(エージェント)の本質的な特徴です。「Tool Description」には業務の文脈とカラム名・コード値の意味・典型的な絞り込み例を含めると、生成される「filter」の精度が大きく上がります。API Server 側のスキーマ整形と組み合わせれば、AI が理解しやすい構造でアクセスできますので、この部分の記述もスマートに構成できるでしょう。
2つのパターンの比較
ワークフロー型とエージェント型は適材適所であり、排他的な関係ではありません。実際の業務では、内容に応じて両方を組み合わせるケースが多いでしょう。たとえば「日次のサマリ生成はワークフロー型で」「営業担当からの個別問い合わせ対応は業務スコープを絞ったエージェント型で」のように、用途に応じて使い分けます。前述の「Building Effective Agents」の中でも「シンプルな解決策から始めて、必要なときだけ複雑さを上げる(finding the simplest solution possible, and only increasing complexity when needed)」ことを推奨しています。本記事のA.パターンを出発点に、必要に応じてB.パターンへと拡張していくという段階的なアプローチは、この推奨に沿った自然な考え方かも知れません。
| A. ワークフロー型 | B. 業務スコープを絞ったエージェント型 |
LLM の役割 | 固定(例: 要約・整形) | ツール選択 + 引数生成 |
クエリパラメータ | 人間が事前に固定 | LLM が動的に生成 |
入力 | スケジュール / 固定パラメータ | ユーザーの自然言語 |
再現 | 最も高い | 高い(業務対象範囲を絞っているため) |
コスト予測性 | 最も高い | 高い |
実装の複雑さ | 低 | 中 |
規制業界との相性 | ◎ | ○ |
適用シーン | 定例レポート、定期サマリ通知 | 対話型業務問い合わせ、社内検索 |
また「Building Effective Agents」の中では、エージェント型システムには「コストの増加や、連鎖的なエラーを引き起こす可能性(higher costs, and the potential for compounding errors)」のリスクがあり、ガードレール(guardrails)が必要だとも述べています。この記事ではAgents に対して「業務スコープを絞る」アプローチを採っていますが、これはガードレールをAI パイプラインの設計レベルで構造的に埋め込んでいるとも言えます。LLM の自由度を引数生成だけに閉じ込め、API Server 側のスキーマ・認証・レート制限・監査ログでデータアクセス層をガードすることで、データアクセスに対して堅牢なガードレールを敷いています。規制の厳しい業種業界などで「予測可能性を高めつつAI を導入したい」というニーズに対する、答えのひとつかも知れません。
社内ネットワーク完結のAI データアクセス基盤としてCData API Server を利用する価値
「社内ネットワーク完結のAI 活用」を検討する場合に、そのデータアクセス基盤としてCData API Server を利用する価値は「こちらの記事」と同じく、Connectivity / Context / Control の3つの観点で整理することができます。
Connectivity : Oracle、SQL Server、IBM i(AS/400)、SAP、ファイル系など270 を超えるデータソースに対応。ライブデータアクセスのハブとして機能します。
Context : 豊富なスキーマカスタマイズ機能により、AI フレンドリーなエンドポイントを提供できるため、LLM の推論精度が上がり、ツール定義もシンプルになります。
Control : ユーザー単位のレート制限、メソッド・オブジェクトごとのアクセス制御、IP 許可リスト、API リクエストの監査ログなど確実な運用に必要な機能性を提供します。
この記事の例でもわかるように、API Server は単純なREST API ではなくOData に準拠したAPI を生成します。これによりクライアント側(n8n の HTTP Request、Tools の $fromAI 等)から $filter / $top / $select / $orderby などの標準化されたクエリ表現でデータを絞り込むことができます。LLM がSQL を生成するわけではなく、業界標準のOData クエリ式を生成するだけで済むため、推論コストにも安全性にも寄与します。
なにより「CData API Server で整備したAPI 資産」は、AI 経由のアクセスに限らず、業務アプリケーションやWeb システムのバックエンドなど豊富な用途から「同じデータモデル」として活用いただけることも大きな価値の1つです。たとえば、AI 用途のために整備した受注API は、そのまま社内モバイルアプリやBI ツール、業務Web 画面のバックエンドとしても活用できます。「AI 専用に作ったAPI」ではなく「全社共通のデータアクセス層」として活用できる点が、CData API Server をデータアクセス基盤の中核に据える構成の中長期メリットです。
[補足]: 自由探索型エージェントを検討する場合
この記事では「ワークフロー型」や「業務スコープを絞ったエージェント」を対象としましたが、「自由探索型エージェント」を構築する場合、ツール接続は MCP サーバー等で動的に束ねる構成が一般的です。
複数のAI クライアントからMCP プロトコル経由で同じデータ基盤を共有したい場合、CData のソリューションではCData Connect AI が標準的な選択肢ですが、社内ネットワーク完結が必須要件のケースにおいては残念ながらフィットしません。このようなケースにおいては、CData API Server とMCP 対応の API Management 製品等を組み合わせて検討することもできます。多様なデータソースをAPI として公開する「CData API Server」と、公開されているAPI に各種制御や統合認証・MCP 化などのガバナンスを提供する「API Management 系製品」は基本的に補完関係であり、競合ではありません。このパターンでの構成例などはまた別の記事であらためてご紹介したいと思います。
まとめ
この記事では「社内ネットワーク完結が必須要件なシーン」において「AI データアクセスの基盤として CData API Server を利用する方法」について、n8n x Local LLM x API Server の構成パターンを例にご紹介しました。
記事の中では「ワークフロー型」と「業務スコープを絞ったエージェント型」として整理しましたが、どちらもポイントは「LLM の役割と権限を明示的に制御」していることにあります。「ワークフロー型」はLLM の役割を固定(要約・整形)し、API Server からのデータ取得は完全に決定的です。「業務スコープを絞ったエージェント型」はLLM の自由度を「ツールの引数生成まで」に制御し、ツール実行によるAPI Server からのデータ取得以降は決定的です。どちらも「LLM が予期せぬデータアクセスを行うことはない」ことが構造的に確認できますので、規制や制約の厳しい業種業態での運用設計と整合しやすい構成だと言えるでしょう。
なお、オンプレミスにあるデータをさまざまなAI から自由度高く活用したい(社内ネットワーク完結を制約されない)シナリオでは、「こちらの記事」でご紹介したパターンの方がフィットするでしょう。AI によるオンプレミスデータの活用といっても要件や制約はさまざまです。それぞれの要件や制約に応じて使い分けてください。
CData API Server は、AI エージェントはもちろん、ビジネスアプリケーションやWeb システムのバックエンドなど豊富なツールから利用できるOData 準拠のAPI をノーコードで開発・運用できるAPI 基盤です。使いやすく堅牢なAPI を提供するAPI Server は、業種業界を問わず幅広く活用いただけます。ぜひ、CData API Server を試してみてください。
製品を試していただく中で何かご不明な点があれば、テクニカルサポートへお気軽にお問い合わせください。
この記事では CData APIServer™ 2026 - 26.1.9595.0 を利用しています





