
こんにちは。CData Software Japan リードエンジニアの杉本です。
「社内の基幹システムのデータをAI エージェントに活用させたい。でも、Salesforce や SAP 、RDB をそのまま MCP で公開するだけでいいのか?」
こういった問いを持ち始めた企業の IT チームやデータ基盤担当のアーキテクトが増えています。私自身、お客様と打ち合わせをする中で、同じような質問を度々受けました。
MCP を通じて接続・連携は技術的にできる。データも取れる。でも、いざ AI エージェントが動き始めると、思ったように使いこなしてくれない。迷う、ズレる、確認を繰り返す。コンテキストウインドウを無作為に消費してしまう。
この記事では、その「なぜ?」を設計の視点から解説してみます。
そして、同じ問いに以前別の文脈で答えた設計思想を MCP の世界に応用することで、社内 AI エージェントが本来の力を発揮できるインターフェースをどのように設計するべきか? その考え方を整理してみましょう。
既存 API をそのまま MCP 化するだけでは不十分な理由
2024年11月に発表されたMCP(Model Context Protocol)の普及とともに、「既存の REST API や社内システムの API を MCP サーバーとして公開する」というアプローチが急速に広がっています。
https://www.anthropic.com/news/model-context-protocol

コネクタライブラリや変換ツールも充実しており、技術的なハードルは下がり続けています。生成AI でMCP サーバーを開発して、業務に組み込んでみた、という実例も度々目にするようになりました。
しかし、「MCP 化した」ことと「AI が使いやすいツールを渡した」ことは、まったく別の話です。
たとえば、「今月の製品別売上を担当者ごとに集計して」という指示を社内の AI エージェントに与えた場合を考えてみましょう。Salesforce の汎用 API をそのまま MCP ツールとして公開していると、AI は次のような行動をとります。
まず、どのツールが目的に合うかを探索します。テーブル一覧を取得し、カラム定義を確認し、どのテーブルに何のデータが入っているかを推論します。次に、対象テーブルからデータを取得しますが、ページネーション対応の API の場合は全件取得まで何度もリクエストを繰り返します。大量のレコードをコンテキストに乗せたうえで、集計処理を行うために Python コードを生成して実行させる、といった手順を踏むことになります。

このプロセスで何が起きているか。探索・取得・加工のすべてのステップがコンテキストを消費します。コンテキストウィンドウの上限に近づくほど AI の判断精度は落ちていきます。最終的に「それらしい答え」を生成するハルシネーション的な挙動が起きやすくなるのは、AI の能力の問題ではなく、渡しているインターフェースの設計の問題です。
汎用的なツールを渡すほど、AI は「どれを使えばいいか」を自力で判断しなければなりません。ツール数が増えれば増えるほど、その探索コストも上がります。API 設計の世界ではとっくに解かれた問題が、MCP の世界でいま改めて浮上しています。
なお「汎用ツールそのものが不要だ」ということではありません。新しいデータソースの構造を把握したいときや、仮説を立てて素早く検証したい探索・分析フェーズでは、汎用ツールは本来の力を発揮します。
問題が顕在化するのは、業務に定着させようとしたときです。「毎朝パイプラインを確認する」「週次でレポートを生成する」——繰り返しの業務タスクに汎用ツールを使い続けると、毎回 AI が探索から始めるため、同じ質問でも返答の品質が安定しません。再現性のなさが、エンタープライズ現場での AI エージェント定着を妨げる第一の課題です。
もうひとつの問題は、ドメインコンテキストの欠如です。汎用ツールを渡された AI は、業務用語・運用ルール・指標定義を知らないまま動き始めます。技術的にはデータを取得できていても、「受注」が Opportunity なのか Order なのか、「今月のクローズ見込み」に Commit ステージを含めるべきかどうか——そういったドメインの文脈なしには、業務目的に即した答えを返すことはできません。
再現性の欠如とドメインコンテキストの欠如——この 2 つが、既存 API をそのまま MCP 化するだけでは不十分な理由であると考えることができます。
「コンシューマーに合わせたインターフェース」の先例:API-led Connectivity
2010 年代、MuleSoft が提唱した API-led Connectivity という設計思想があります。「API を用途に応じた 3 つの層に分類し、データとアプリケーションの接続における再利用性を高める」というアーキテクチャパターンです。
https://www.salesforce.com/blog/api-led-connectivity/
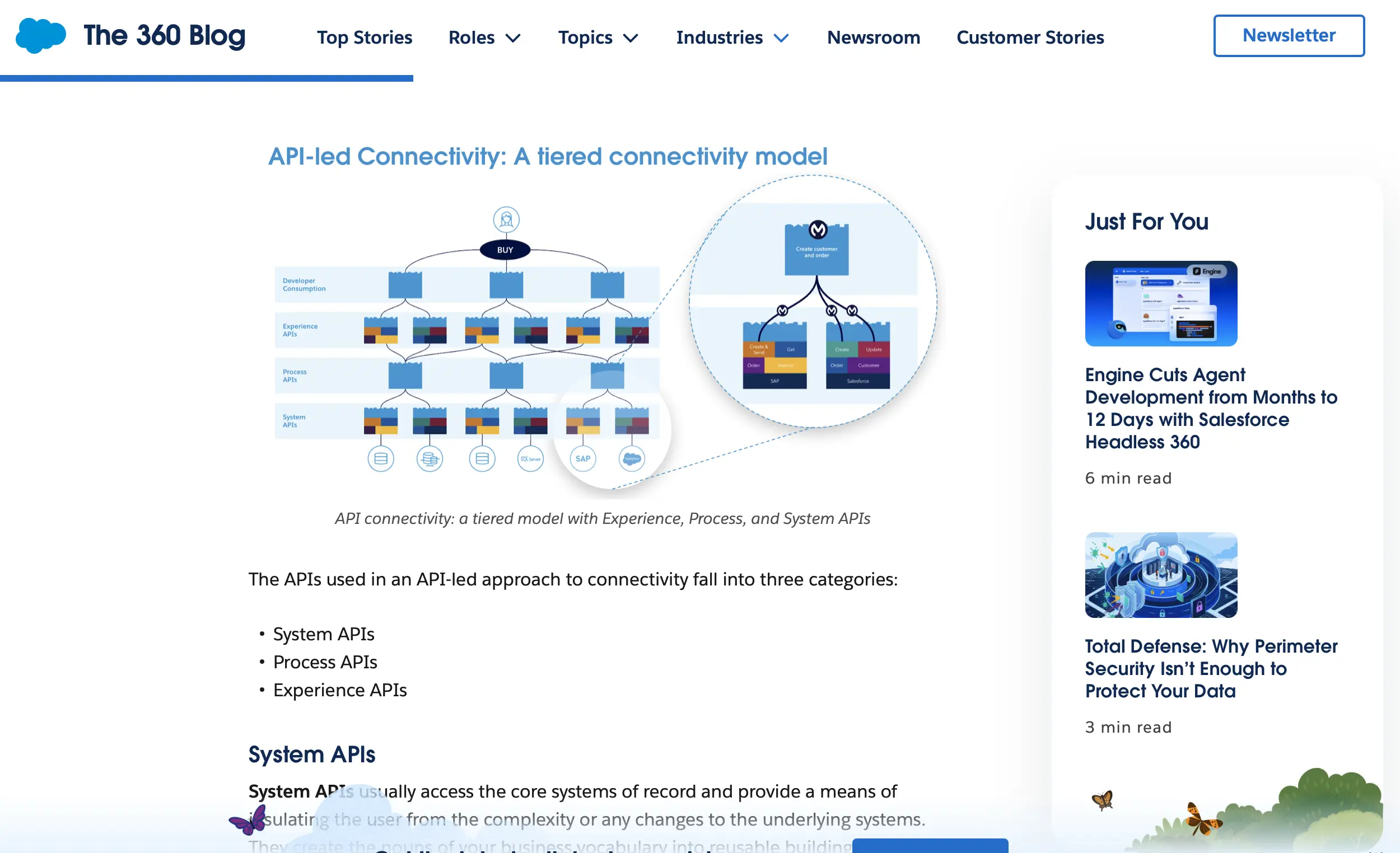
当時の課題は以下のようなものでした。
同じバックエンドシステムに対して、モバイルアプリ・Web ブラウザ・IoT デバイスなど、異なる「コンシューマー」が接続しようとしている。それぞれのコンシューマーが必要とするデータの形・粒度・頻度はまったく異なるのに、バックエンドの生のデータをそのまま渡そうとすると、コンシューマー側の実装が複雑になり、変更にも弱くなる。
その解として提示されたのが、3 層の分離です。
層 | 名称 | 役割 |
|---|
下層 | System API | バックエンドのシステムやデータベースへの直接接続。データの取得・更新を担う |
中間層 | Process API | ビジネスロジックの実装とオーケストレーション。複数の System API を組み合わせ、ルールに従って処理する |
上層 | Experience API | 特定のコンシューマー(デバイス・チャネル・ユースケース)に最適化されたインターフェース。コンシューマーが必要な形・粒度でデータを提供する |

このアーキテクチャが解いた本質は、「コンシューマーが変わればインターフェースも変わるべき」という原則です。モバイルアプリ向けの Experience API とコールセンター向けの Experience API は、裏側の System API を共有しながらも、表に出す形はまったく異なります。
この考え方は、MCP の設計にそのまま応用できます。そして応用先における「新しいコンシューマー」とは「AI エージェント」であると考えることができます。
AI が持ち合わせていない、3 種類の組織の暗黙知
AI エージェントは、これまでのどの API コンシューマーとも異なる特性を持っています。
人間の開発者であれば、API ドキュメントや社内のナレッジを読んで設計を理解し、適切なエンドポイントを選んで実装します。ツールの使い方を様々なナレッジから「事前に学習」するため、実行時のコストはかかりません。
一方、AI エージェントはツールの一覧から実行時に推論します。ツール名・説明・パラメータ定義を手がかりに「これを使えばいいか」を都度判断します。つまり、ツールの意図や用途が曖昧であるほど、AI が迷い、コンテキストを消費するということです。
ここで重要な概念が「アフォーダンス」です。ドアノブを見ると「ひねる」という操作が自然に伝わるように、ツールの名前・説明・パラメータが「何をどう使えばいいか」を自己説明的に伝えることが、AI には特に重要です。人間の開発者はドキュメントを熟読して理解できますが、AI はツール定義そのものから意図を読み取るしかありません。
https://ja.wikipedia.org/wiki/アフォーダンス
この問題が特に顕著に現れるのが、Oracle・PostgreSQL などの RDB や、Salesforce・SAP・kintone といった Horizontal SaaS を基幹システムとして導入している企業です。
Salesforce に代表される Horizontal SaaS は汎用設計が強みです。標準オブジェクトやフィールドを提供しつつ、各企業が自社のビジネスプロセスに合わせてカスタムフィールドを追加し、ワークフローを定義し、独自の運用ルールを組み込んでいきます。結果として、「同じ Salesforce を使っていても、A 社と B 社のスキーマは実質的にまったく異なる」という状態が生まれます。
AI にとっての問題はここにあります。スキーマは「標準的に見える」のに、その実態は会社固有の知識で埋め尽くされています。そしてその知識は、スキーマではなく組織の中に暗黙知として蓄積されています。
汎用 API をそのまま汎用的な MCP ツールとして渡された AI は、この暗黙知を持たないまま動き始めます。そのときに構造的に生じるのが、次の 3 種類のギャップです。
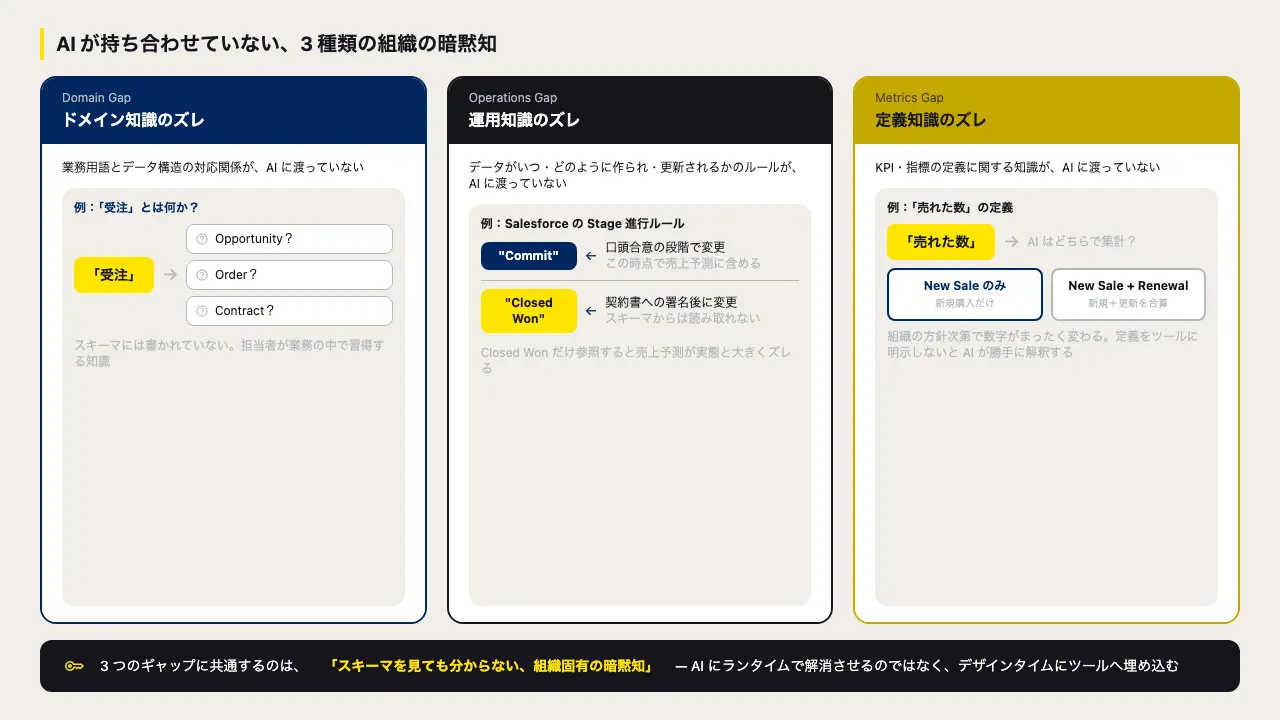
Domain Gap(ドメイン知識のズレ)
業務用語とデータ構造の対応関係に関する知識が、AI に渡っていない問題です。「受注」と言ったときに Salesforce の Opportunity を指すのか Order を指すのか Contract を指すのか。Stage = "Negotiation" が自社のどの営業フェーズを指すのか。こうした対応関係は担当者が業務の中で習得するものであり、スキーマには書かれていません。
新入社員が Salesforce を使い始めたとき、最初に戸惑うのがまさにこの部分です。AI も毎回、同じ問いに直面しています。
Operations Gap(運用知識のズレ)
データがいつ・どのように作られ・更新されるかのルールに関する知識が、AI に渡っていない問題です。
Salesforce の Stage フィールドを例に考えてみましょう。標準の Stage 値として "Negotiation" や "Closed Won" が並んでいますが、「どの段階でステージを進めるか」の基準は各社が独自に定めています。ある企業では口頭合意の段階でカスタムステージの "Commit" に変更し、その時点で売上予測に含めるルールがあります。Closed Won に変更するのは契約書への署名が完了した後です。
AI が「今月のクローズ見込みを教えて」と問われたとき、Closed Won だけを参照すると、実態の売上予測から大きくズレた数字を返します。データに誤りはなく、スキーマも正しい。「いつ・どの基準でステージを進めるか」という運用ルールを AI が持っていないことが原因です。このような運用知識は、チームのオンボーディング資料や担当者の経験値として存在しており、スキーマからは読み取れません。
なお、表記ゆれや入力の揺れといったデータ品質の問題は Operations Gap と似て非なるものです。Operations Gap はルール自体が AI に渡っていない問題であり、データ品質問題はデータ移行・外部統合・入力の徹底不足に起因する別の問題です。前者はツール設計で吸収できますが、後者は完全には解消できない部分もあります。ツール設計と並行してデータガバナンスの整備も求められます。
Metrics Gap(定義知識のズレ)
ビジネス指標や KPI の定義に関する知識が、AI に渡っていない問題です。「売れた数」という一言の中に、新規購入(New Sale)と更新(Renewal)が混在していても、どう集計するかは組織の方針によって異なります。Horizontal SaaS では部門やチームごとにカスタムフィールドで独自の指標を管理していることも多く、「売上」「受注」「成約」という言葉が指す数字が組織内で統一されていないケースも珍しくありません。
指標の定義が曖昧なままツールを渡すと、AI は都合よく解釈して集計するか、確認のやり取りを繰り返すかのどちらかになります。
この 3 つのギャップに共通するのは、「スキーマを見ても分からない、組織固有の暗黙知」だという点です。AI でアドホックにこれらを解消させようとすると、探索コストが積み重なり、コンテキストが圧迫され、最終的な答えの精度が下がります。暗黙知をデザインタイムにツールへ埋め込むことが、MCP インターフェース設計の核心です。
MCP-led Architecture:3 層モデル
この3 つのギャップは「何が問題か」を示す動機軸です。それに対して、MCP-led Architecture の 3 層は「どう解決するか」を示す構造軸です。ギャップと層は 1 対 1 に対応するわけではなく、3 層全体が協調することで暗黙知をインターフェースのデザインとして吸収します。
API-led Connectivity の 3 層をそのまま MCP に対応させると、以下の構造になります。
API-led の層 | MCP での役割 |
|---|
Experience Tools | AI エージェントのユースケースに特化したインターフェース |
Process Tools | ビジネスロジックの実装・データ変換・複数ソースの結合 |
System Tools | バックエンドへの汎用接続・スキーマ探索 |
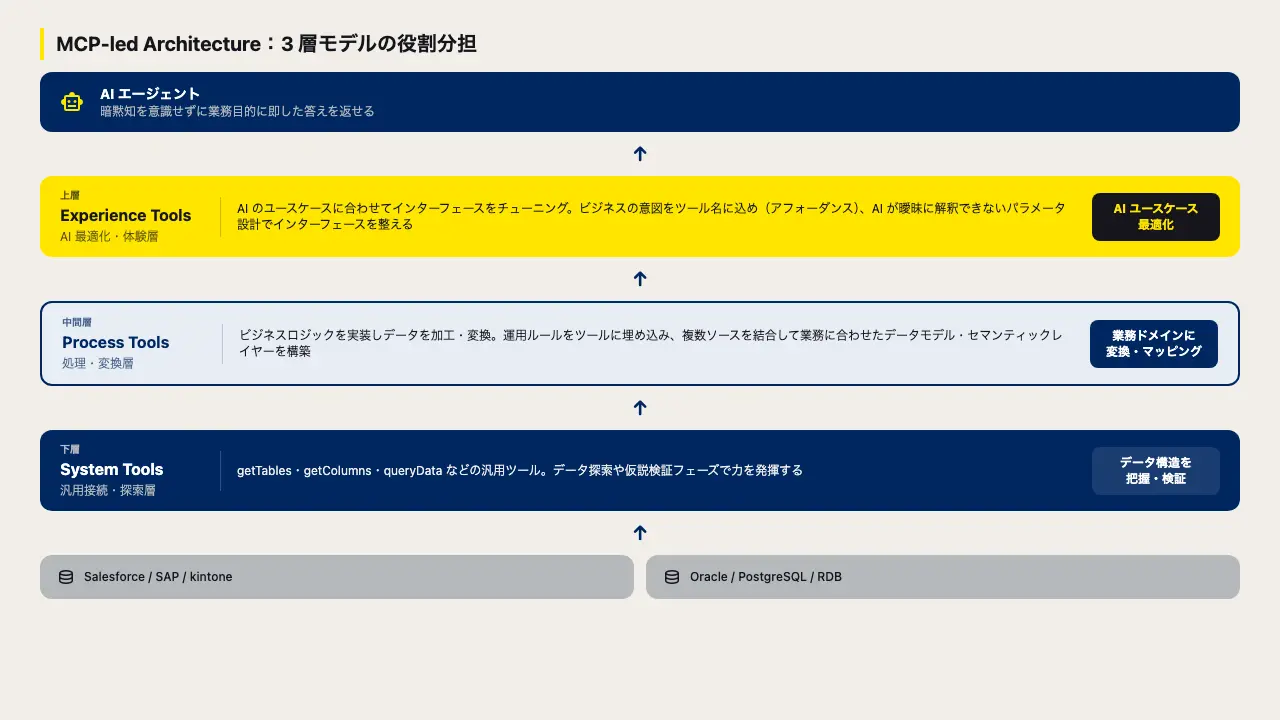
各層の役割を詳しく見ていきましょう。
Experience Tools(AI 最適化・体験層)
AI エージェントというコンシューマーに特化して最適化された最上位の層です。この層の役割は、「AI のユースケースに合わせてインターフェースをチューニングする」ことです。Process Tools で業務ドメインに変換・マッピングされたデータをベースに、営業担当者向けエージェント・バックオフィス向けエージェントといった具体的な AI ペルソナに対して、必要なツールだけを過不足なく提供します。この層の設計原則は、「AI が考えなくても使えるツールを作る」ことです。
Domain Gap への対処としては、ビジネスの意図をツール名に込めることが重要です。queryData ではなく get_monthly_sales_by_owner、search ではなく search_high_priority_unassigned_issues のように、ツール名と説明だけで「いつ・何のために使うべきか」が自明に伝わる設計が理想です。これがアフォーダンスの実践であり、ドメイン知識をツール定義に翻訳する作業でもあります。
Metrics Gap への対処としては、AI が曖昧に解釈できないパラメータ設計が重要です。「New Sale のみ」と「New Sale + Renewal」のどちらで集計するかという定義そのものは Process Tools に実装しておき、Experience Tools ではそれを get_monthly_sales_summary(month, owner?, sale_type?) のようにパラメータで明示的に選ばせる設計にします。sale_type で「新規」「更新」「両方」を指定させることで、AI が勝手に解釈して集計することを防げます。
Process Tools(処理・変換層)
ビジネスロジックを実装し、データを加工・変換する中間層です。この層の役割は、「業務ドメインに合わせてデータを変換・マッピングする」ことです。
先の Stage の例で言えば、「有効な商談」の定義(どのステージ・どの期間・どのフィールドが入力済みか)を SQL に埋め込んでおくことで、AI は運用ルールを知らなくても正しいデータセットを受け取れます。また、複数データソースをまたぐ分析が必要な場合も、この層でデータを結合・統合してから上位層に渡すアーキテクチャが有効です。「Salesforce の商談データと Jira のチケットを突き合わせる」ような処理を AI に逐次実行させると、ツール呼び出しのたびにコンテキストが積み重なります。Process Tools でセマンティックレイヤーとして統合済みのビューを用意しておくと、AI から見ると「1 つのデータソース」として扱えます。
System Tools(汎用接続・探索層)
バックエンドのシステムやデータベースに対して汎用的にアクセスするための層です。getTables・getColumns・queryData のようなスキーマ探索・汎用ツールがここに属します。
この層の特徴は「何に使うかが決まっていない段階」に適している点です。新しいデータソースに接続して構造を把握したい場合や、仮説を立てて素早く検証したい探索・分析フェーズでは、System Tools が本来の力を発揮します。
ただし、繰り返しの業務タスクや定常レポートを担う本番フェーズに System Tools だけを渡すのは避けるべきです。AI は毎回探索から始めるため、同じ質問でも返答の品質が安定しません。System Tools は探索フェーズに割り当て、業務定着を目指す本番フェーズには渡さないという使い分けが、再現性を確保するうえで重要です。
横断的な設計原則:認可や権限をインターフェース・ツールの設計で制御
3 種類の暗黙知と同様に、認可や権限の設計もAI に判断させるのではなく、インターフェース・ツールの設計で制御することが重要です。AI が「このデータを見ていいか」を自分で判断するのではなく、そもそも見えないように設計しておく、という発想です。
AI は自律的に動くため、「整理して」という指示を「不要なレコードを削除する」と解釈することがあります。意図しない操作を防ぐには、AI に意志を持たせないのではなく、物理的にできない設計にしておくことが本質的な対策です。
3 層それぞれに認可の境界を設けることができます。

認可の設計は後付けで行うことが難しく、ツール設計の初期段階から組み込んでおく必要があります。
実践例:Salesforce・SAP で 3 層を設計する
ここまでの考え方を、実際のエンタープライズシステムに当てはめてみましょう。Salesforce と SAP は導入企業数が多い Horizontal SaaS の代表例であり、それぞれ 3 種類の暗黙知が異なる形で顕在化します。
Salesforce:営業パイプライン分析エージェントの場合
Salesforce の標準オブジェクトは一見わかりやすいように見えますが、「受注」「売上」「契約」という業務用語がどのオブジェクトに対応するかは、各社の運用によって大きく異なります。
3 種類の暗黙知の顕れ方
暗黙知の種類 | Salesforce での具体例 |
|---|
Domain Gap | 「受注」は Stage = "Closed Won" の Opportunity か、作成済みの Order か。「製品」は Product2 か OrderItem の ProductCode か。会社ごとに違う |
Operations Gap | ステージ進行の基準(口頭合意で "Commit"、署名完了で "Closed Won" にするなど)、Opportunity の作成タイミング、必須フィールドの入力ルール |
Metrics Gap | 「売上」は Opportunity.Amount か OpportunityLineItem の合計か。税込みか税抜きか。更新(Renewal)を新規と同じ軸で見るか |
3 層の設計例
層 | 設計内容 |
|---|
System Tools | getTables・getColumns・queryData を探索フェーズ専用に用意。本番フェーズには渡さない
|
Process Tools | "active_opportunities" ビュー(自社の有効ステージ・必須フィールド条件を SQL に埋め込む)。OpportunityLineItem を JOIN して金額を正規化 |
Experience Tools | get_pipeline_summary(owner?, stage?, period?) でパイプラインを集計済みで返す。get_won_deals(month, include_renewal?) で新規・更新を明示的に分離
|
SAP:受注・売上分析エージェントの場合
SAP は Salesforce 以上にスキーマが複雑で、同じ「受注」を指すテーブルや項目でも、使用するモジュール・導入構成・伝票タイプ(Belegart)によって実態が異なります。以下は SD モジュール・FI モジュールを中心とした一般的な例です(実際の実装は構成次第です)。
3 種類の暗黙知の顕れ方
暗黙知の種類 | SAP での具体例 |
|---|
Domain Gap | 「受注」は VBAK(受注ヘッダ)の伝票タイプ OR か、自社カスタムの ZOR か。「売上計上」は VBRK(請求ヘッダ)か BKPF(会計伝票)か。会社・モジュール設定次第 |
Operations Gap | 伝票タイプの使い分けルール(OR / ZOR / RE 等)、プラントコード(Werke)の意味、売上計上タイミング(出荷基準か請求基準か)は社内設定に依存 |
Metrics Gap | 「純売上」は VBRP.NETWR か BSEG の貸方金額か。税額(MWST)を含むか。「受注残」は未出荷の VBAP 行の NETWR 合計か |
3 層の設計例
層 | 設計内容 |
|---|
System Tools | 汎用アクセスを探索フェーズ専用に用意 |
Process Tools | "sales_orders" ビュー(VBAK ⊕ VBAP ⊕ KNA1 を JOIN し、自社で使用する伝票タイプのみにフィルタ)。プラント・販売組織コードを人間が読めるラベルに正規化 |
Experience Tools | get_open_orders(customer?, material?, plant?) で受注残一覧を返す。get_monthly_revenue(month, sales_org?, material_group?) で月次売上を集計済みで返す
|
SAP の場合、Process Tools で「自社が使っている伝票タイプと販売組織の定義」を SQL に埋め込んでおくことが特に重要です。これをしないと、AI は全伝票タイプのデータを引いてきて、自社に関係ない伝票が混入した集計結果を返します。
2 つの例に共通するのは、「スキーマを知るだけでは不十分で、そのシステムをこの会社がどう使っているかを知らなければ AI は正しく動けない」という点です。その「使い方の知識」を 「Process Tools」で適切にモデリングし、「Experience Tools」でAI に理解しやすいように届ける設計することが、MCP-led Architecture の実践です。
まとめ:「MCP で公開する」から「AI のインターフェースを設計する」へ
3 層の対応関係を改めて整理すると、以下のようになります。
API-led の層 | MCP での役割 | 設計のポイント |
|---|
Experience API → Experience Tools | AI コンシューマーに最適化されたインターフェース | AI ユースケースに合わせてインターフェースをチューニング |
Process API → Process Tools | ビジネスロジックの処理・変換・結合 | 業務ドメインに合わせてデータを変換・マッピング |
System API → System Tools | バックエンドへの汎用接続・スキーマ探索 | 探索フェーズに限定して使う |
3 層モデルが生む明確なオーナーシップ
3 層モデルの利点は、技術的な整理にとどまりません。「誰が・何を・いつ管理するか」という責任の境界も自然に明確になります。

多くの企業では、情報システム部門が既存システムの安定運用を担う「守り」の役割を、DX チームや AI 導入推進チームが新しい活用方法を模索する「攻め」の役割を担っています。System Tools は前者が、Experience Tools は後者が自然なオーナーになりやすく、Process Tools はその接点として両チームが協業する領域です。この境界が明確になることは、AI エージェント導入を組織として推進するうえでの大きなメリットです。
API-led Connectivity が「モバイル・Web・IoT という多様なコンシューマー」に答えたように、MCP-led Architecture は「AI エージェントという新しいコンシューマー」に答える設計思想です。
重要なのは、この設計アプローチが AI の賢さに依存していない点です。AI がどれだけ優秀であっても、渡されるツールの設計が悪ければパフォーマンスは下がります。逆に言えば、組織の中に蓄積された暗黙知を 3 層のどこかに適切に埋め込むことで、AI は本来持っている推論能力を余すことなく発揮できます。
「社内システムを MCP で公開する」という発想から「社内 AI エージェントのためのインターフェースを設計する」という発想への転換が、エンタープライズにおける AI エージェント活用の鍵だと考えています。
MCP を使った AI エージェントの構築を進めている方のヒントになれば幸いです。
CData Connect AI でこの設計を実践する
本記事で説明した 3 層モデルは、CData Connect AI の Toolkits 機能によっても実践できます。
CData Connect AI は 350 種類以上のデータソースに対してリモート MCP 経由でのアクセスを提供するプラットフォームです。Toolkits 機能では、AI エージェントに渡すツール群を用途ごとに分離・管理でき、本記事の 3 層モデルに対応した構成を取ることができます。

MCP-led Architecture の層 | Toolkits での実装 |
|---|
Experience Tools | Custom SQL Tools でパラメータ付きの事前定義クエリを作成し、AI が曖昧に解釈できないインターフェースを設計。Source Tools に AI Instructions を設定してドメイン文脈を明示する |
Process Tools | Workspace 上で Derived Views として複数データソースを結合。運用ルールをクエリに埋め込み、業務ドメインに合わせたデータモデルを構築する |
System Tools | Universal Tools(getTables・getColumns・queryData 等)を有効化したツールキット。スキーマ探索フェーズ専用として切り出す |
認可の設計については、CData Connect AI が提供する多層アクセス制御モデル(データソース側の権限・認証モデル・コネクション権限・公開範囲・Toolkit の 5 層)を活用することで、3 層それぞれの認可の境界を実装できます。詳細はこちらの記事を参照ください。






