AI に必要な 一貫した コンテキストを
CData はチームにガバナンスレイヤーを提供します。これにより、すべてのプロンプトとワークフローが同じコンテキスト理解に基づいて動作します。
課題
業務コンテキストがプロンプトや未整形のデータに散在していると、回答はすぐに一貫性を失います。
統制の効いた定義がなければ、すべてのエージェントやダッシュボードが「第 2 四半期の売上」や「アクティブな顧客」を独自に解釈してしまいます。その結果生じるのは、単なる不整合ではなく、信頼の喪失です。
AI が生データに対してロジックをゼロから組み立てると、やり取りのたびに誤りが生じる余地が生まれます。デプロイするエージェントが増えるほど、ツール呼び出し・ばらつき・トークンコストが積み重なっていきます。
スコープを限定したワークスペースがなければ、新しいエージェントは必要のないアクセス権まで引き継いでしまいます。その結果、ユースケースごとにアクセス設計を手作業で行うプロジェクトが発生してしまいます。
仕組み
定義、アクセス、パフォーマンスを集約した、一元管理された統合コンテキストレイヤー。
ロジックは一度だけ定義し、利用範囲はスコープで制御し、鮮度はチューニングで調整します。すべてのエージェント、アナリスト、ダッシュボードの背後に、単一のコントロールプレーンが存在します。
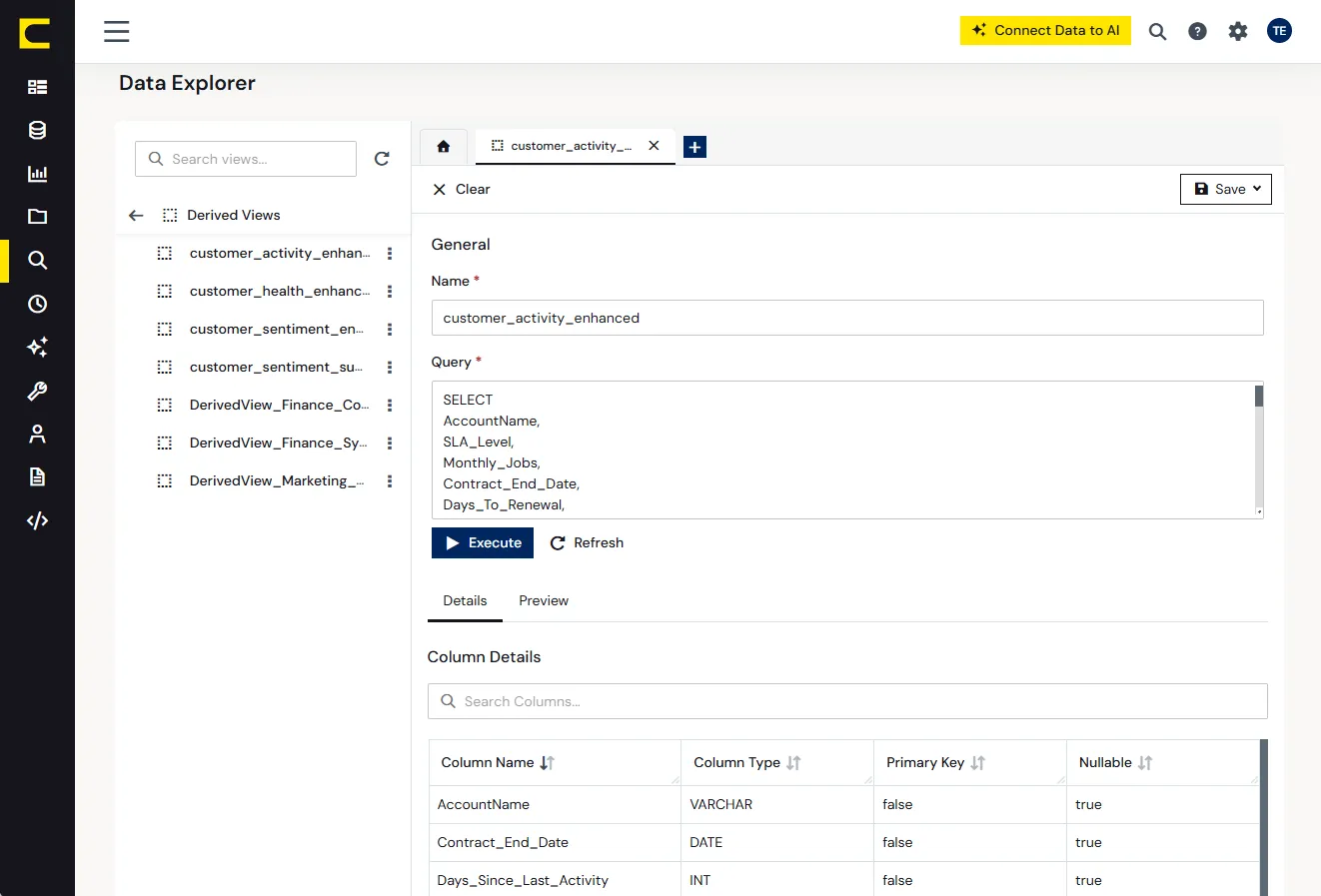
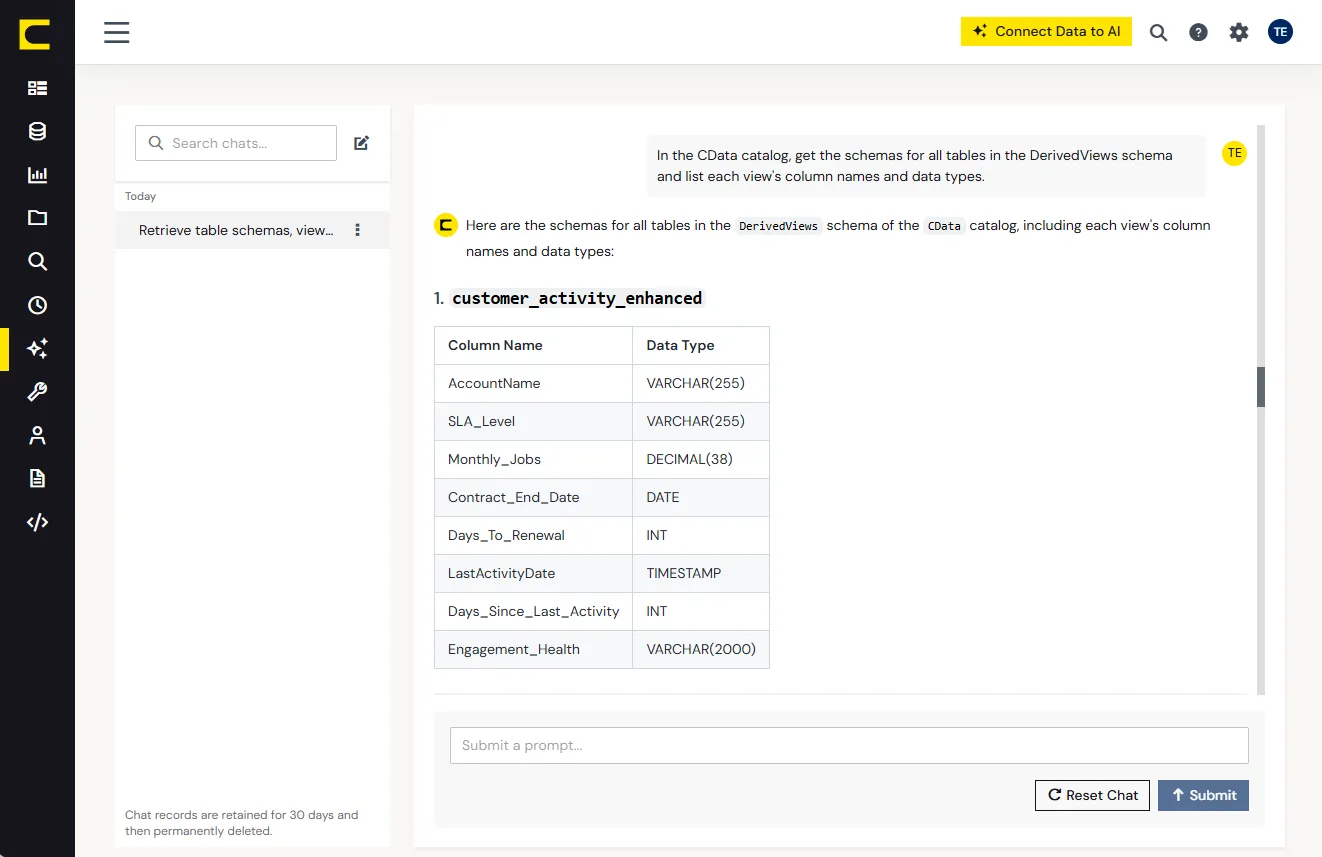
データチームは、信頼できる業務コンテキストのスキーマをDerived Viewsとして一度だけ定義します。たとえば「地域別の第 2 四半期の売上」を、適切な会計カレンダー、日付フィールド、売上定義とともに定義します。
そのDerived Viewsはプラットフォームに登録され、getSchema に自動的に表示されます。AI は生データからクエリを組み立てるのではなく、この定義を見つけて使うだけで済みます。
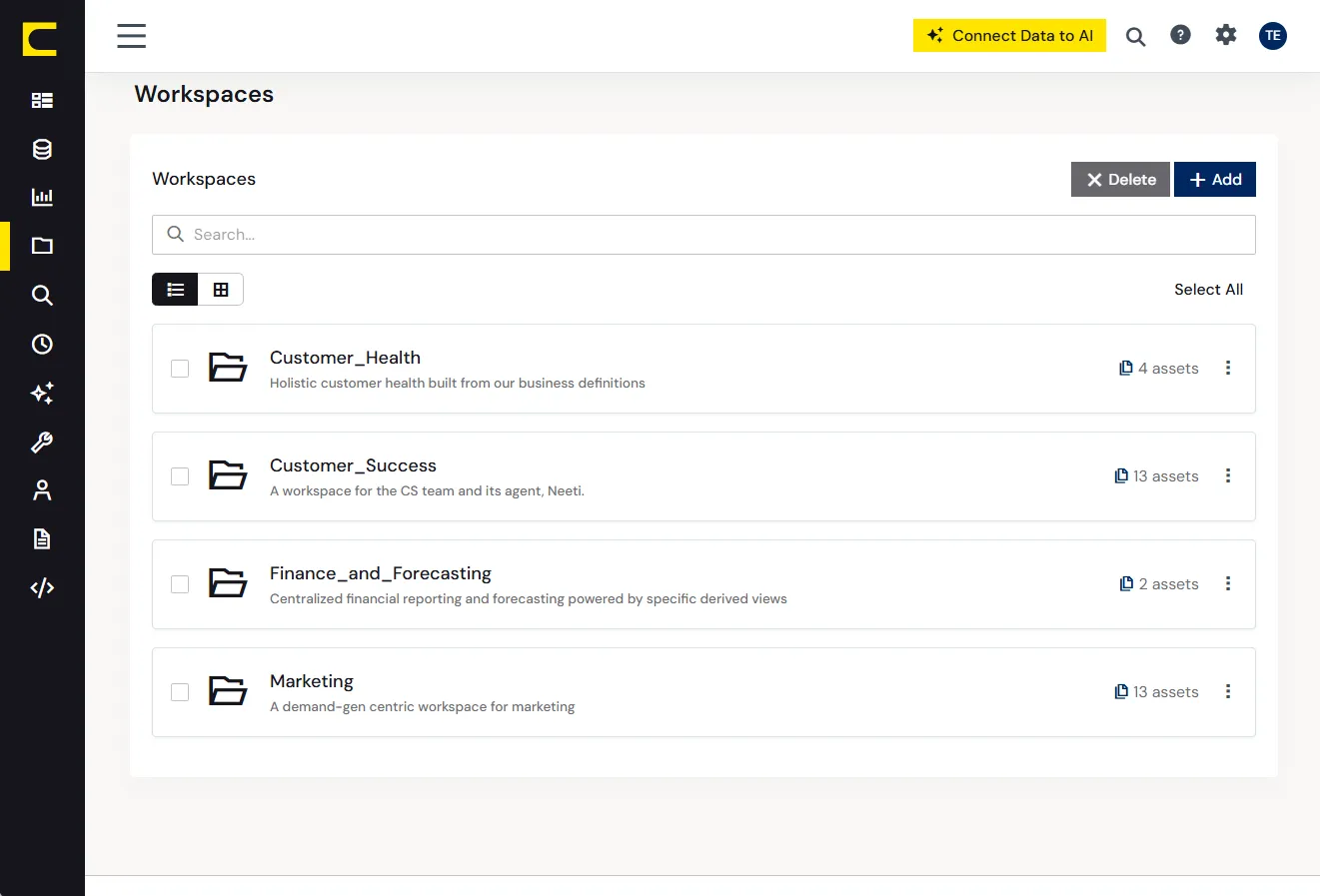
各エージェントやチームは、アクセスを許可されたデータソース、ツール、Derived Viewsだけにスコープされたワークスペースの中で動作します。
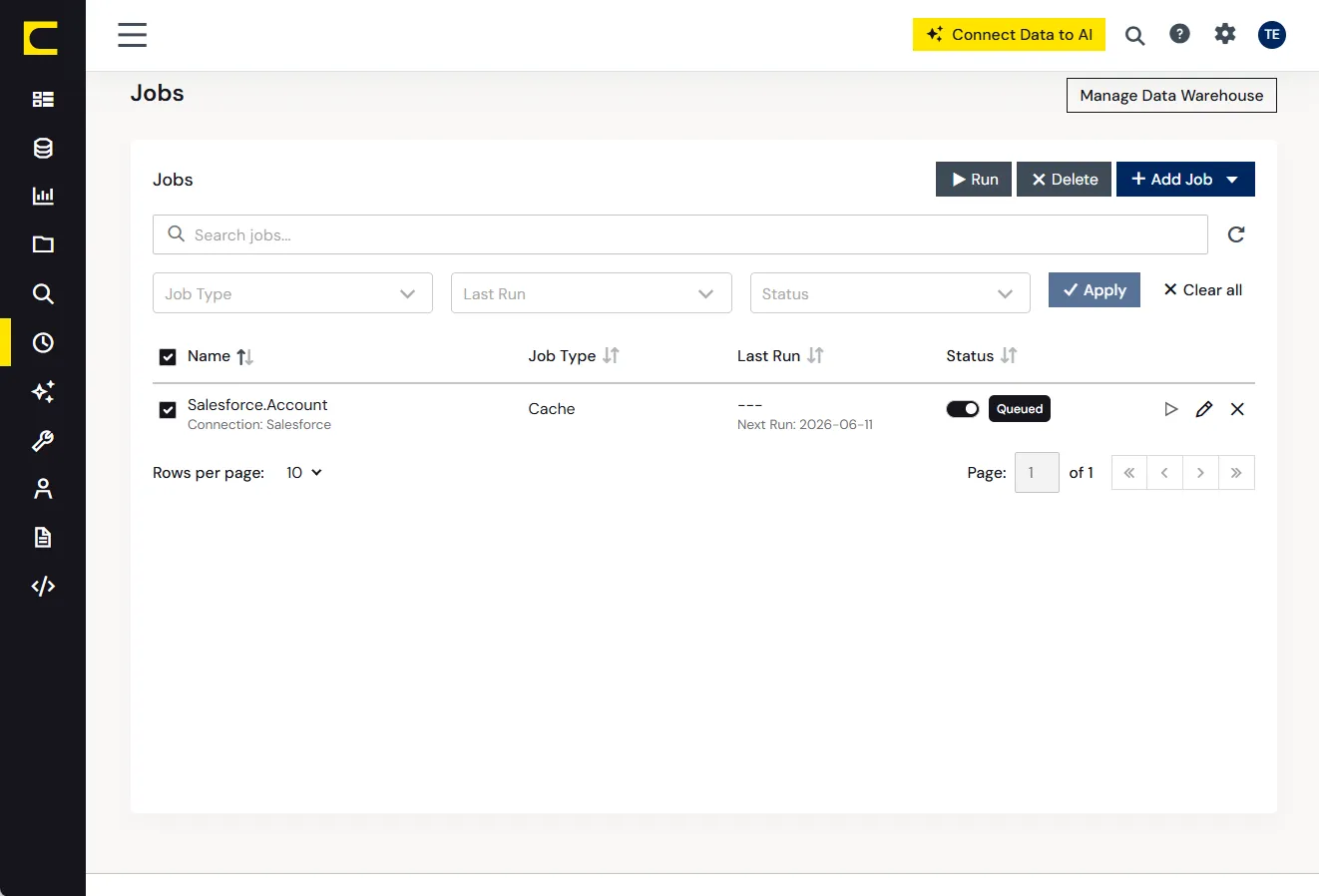
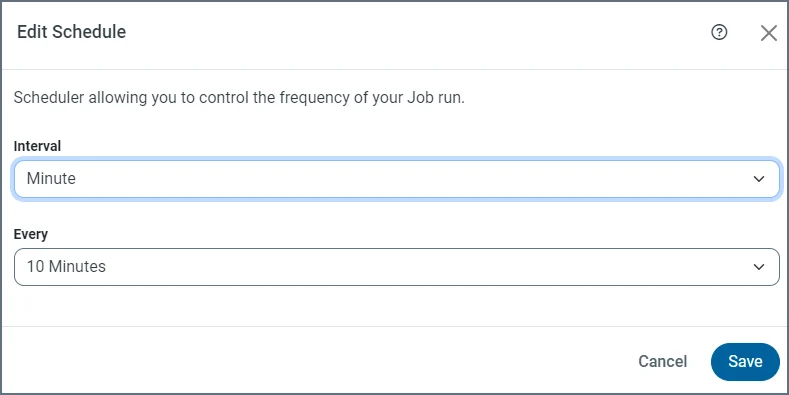
高頻度のメトリクスについては、ビューごとにクエリキャッシュとスケジュール更新を構成します。顧客が管理するストレージと、ユースケースごとに適した鮮度の更新間隔を利用します。
エージェントやユーザーが、リアルタイムデータソース、ガバナンスの効いたビュー、キャッシュされた定義のいずれをクエリした場合でも、すべてのやり取りが同じガバナンスモデルの下でログに記録されます。
一つの信頼できる定義が、一つの統制の効いた回答をあらゆる場面で生み出します。