AI が明確に 理解 できるコンテキスト
CData は各コネクタに、プロンプト・フィールド・ビジネスロジックを正しく解釈するために AI が必要とするコンテキストを与えます。
課題
データにアクセスできることと、AI がその意味を理解できることは別物です。ここで差がつくのは後者です。
基本的な MCP ゲートウェイはプロンプトを API コールに変換できますが、ルールや関係性を理解していないため、回答はもっともらしく見えても間違っています。
AI は各システムの動きを試行錯誤しながら覚えていきます — ツールコールは増え、トークンは膨らみ、レスポンスは遅くなり、精度は下がります。
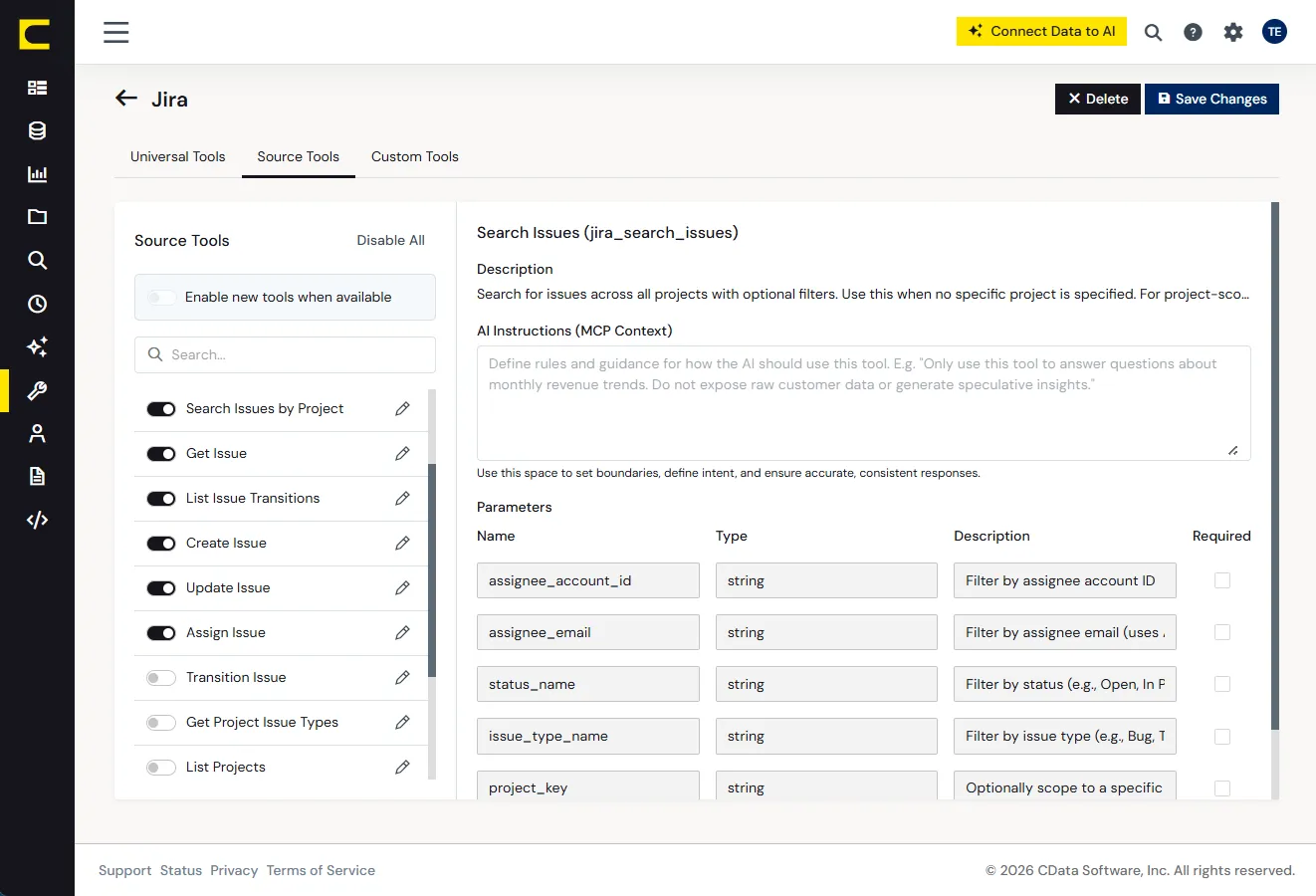
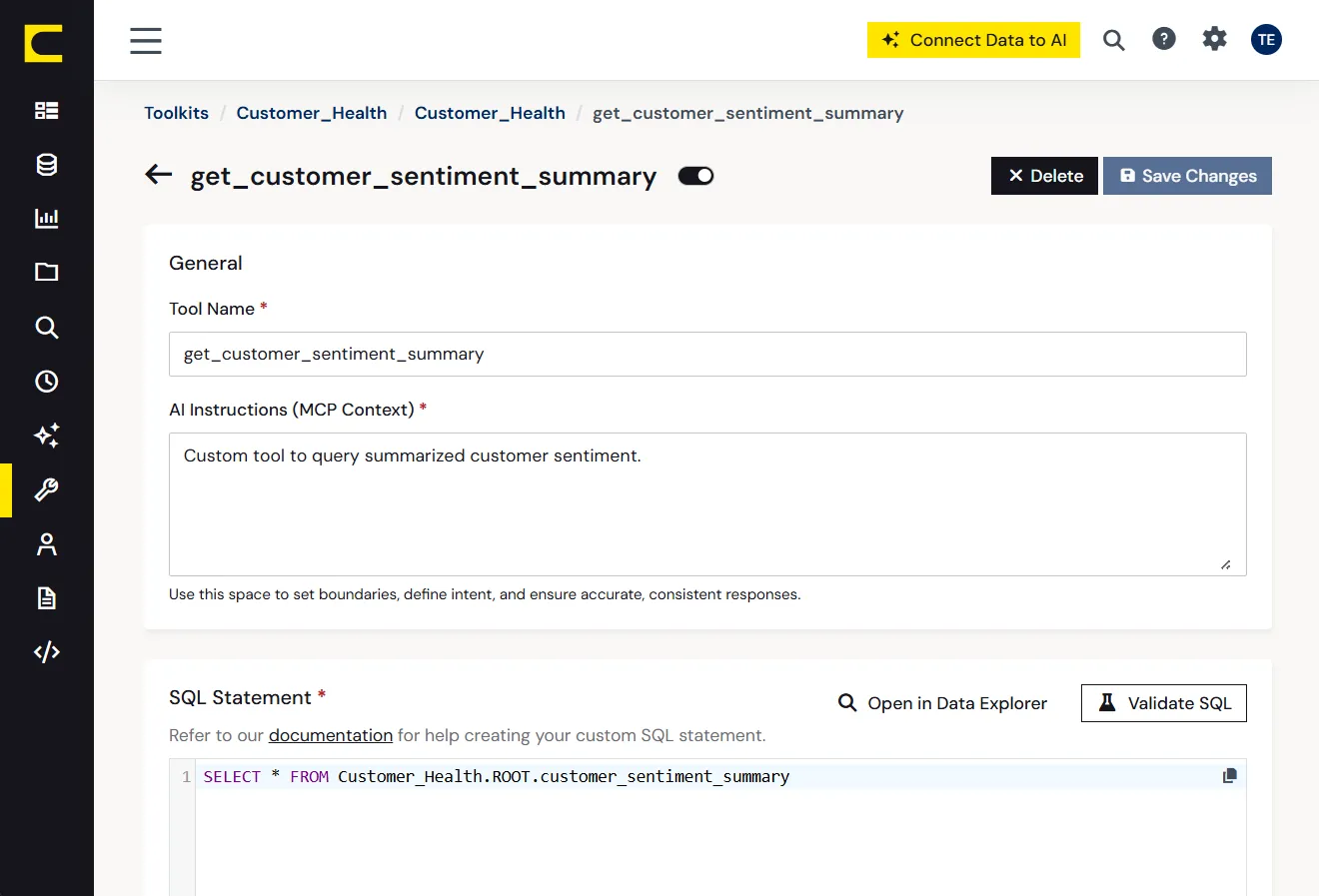
カスタムフィールド、社内定義、独自システムにこそ、本当のビジネスロジックが詰まっています。AI がそのコンテキストを解釈できなければ、信頼できる回答はできません。
適切なコンテキストを統合できないシステムは、LLM を混乱させ、コストを膨らませます。
仕組み
CData がアクセスを理解へと変える仕組み。
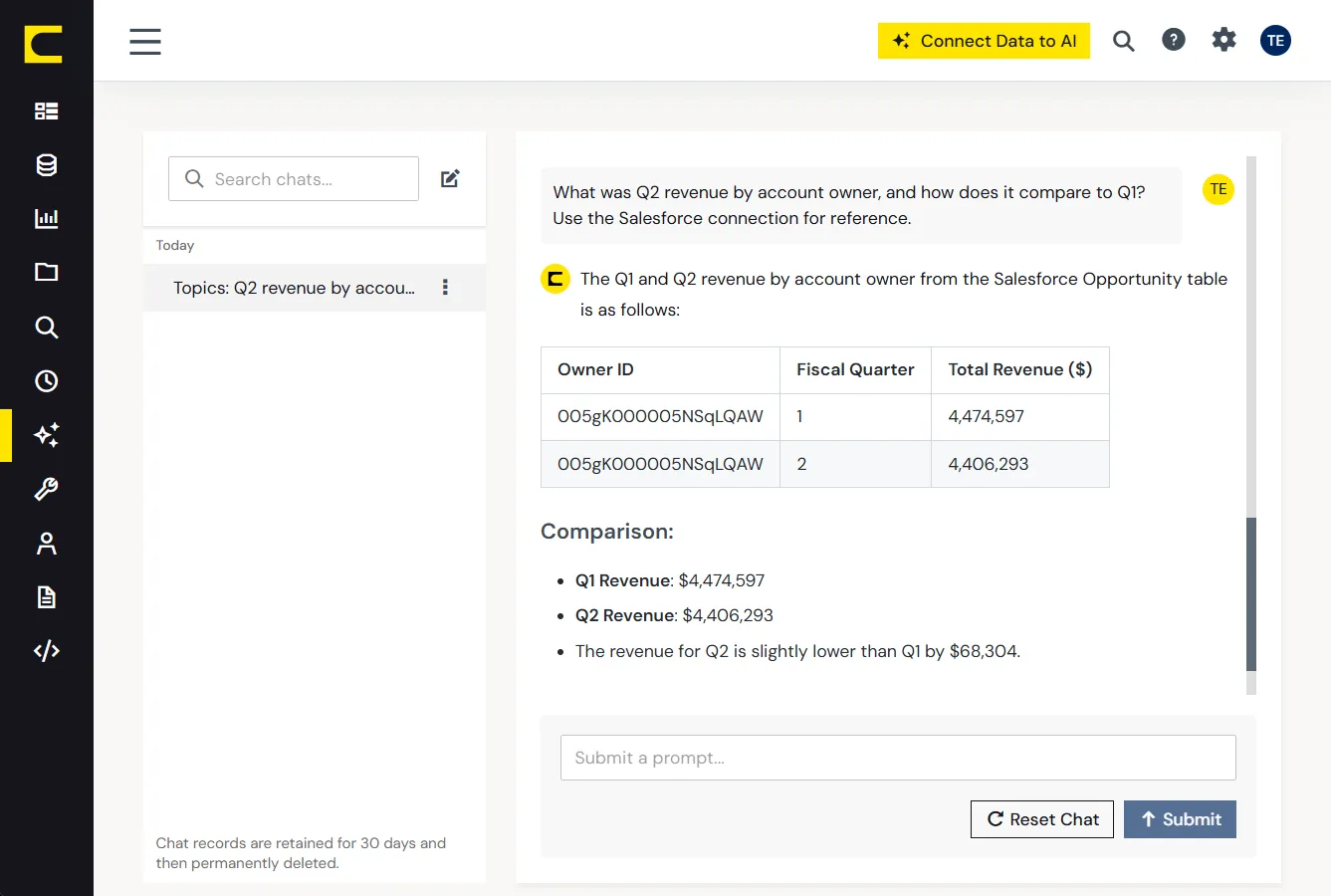
CData はクエリが実行される前に、データソース固有の意味を解決します。そのため AI は、試行錯誤で失敗を重ねるのではなく、最初から正しいコールを計画できます。
データソースのシステムのコンテキストの中でリクエストを解釈
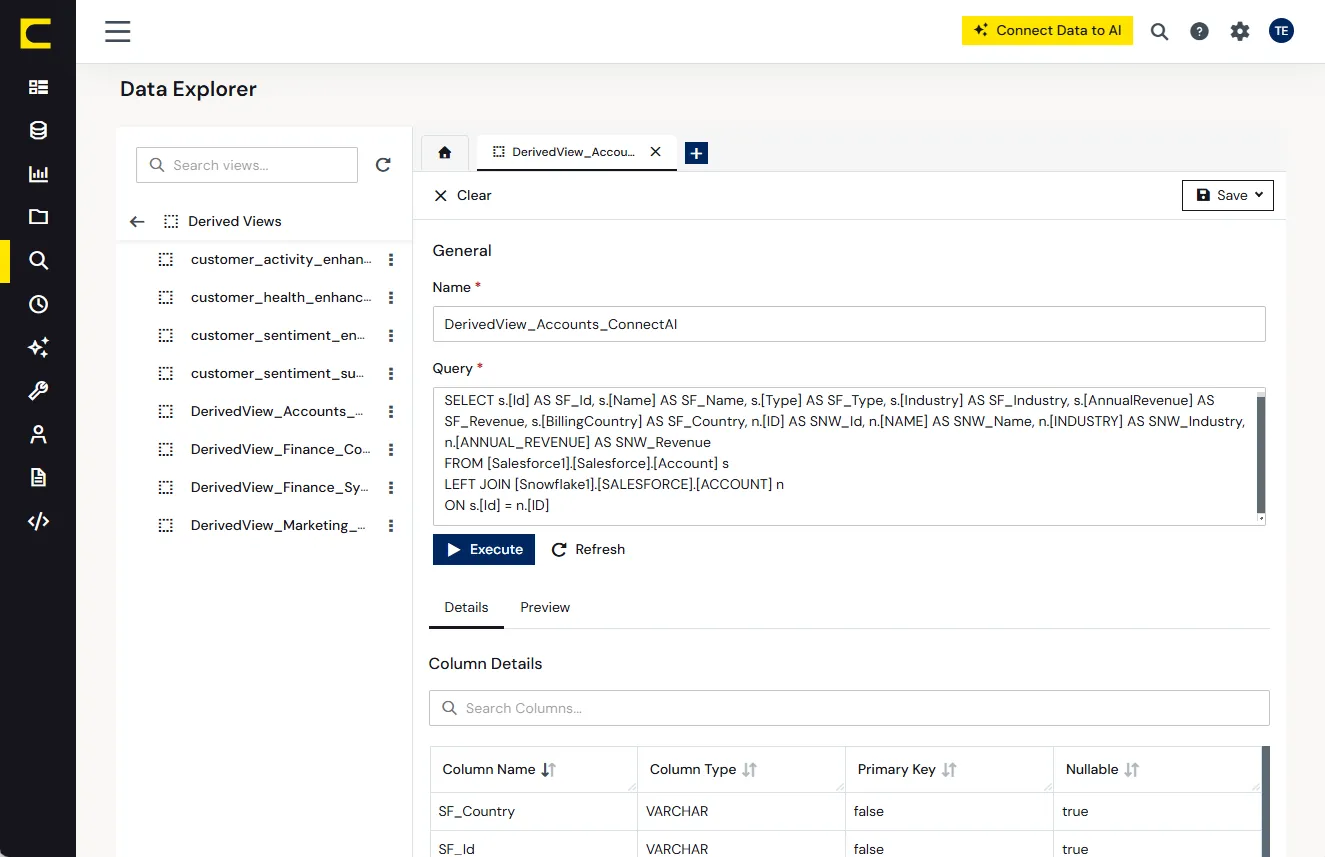
CData はクエリの背後にあるシステムを識別し、フィールドマッピング、エンティティ間の関係、会計ロジック、プラットフォーム固有の慣習といったデータソース固有のコンテキストを適用します。
適切な実行プランを構築
試行錯誤で推測するのではなく、最初から適切なフィールド、フィルター、操作を選択します。複数のデータソースにまたがるクエリやワークフローでは、CData がシステム横断でコンテキストを集約・正規化します。これにより、実行の一貫性を保てます。
コンテキスト化されたリクエストを実行レイヤーへ引き継ぐ
コンテキストが解決されると、CData は完全にコンテキスト化されたリクエストを実行レイヤーへ渡し、ガバナンスされたクエリ実行を行います。実行がデータソース側でどのように最適化されるかは、「データアクセス&アクション」をご覧ください。
コンテキストを第一に。もっともらしい間違いではなく、正確な回答を。