適合性チェック
すでに稼働中のアイデンティティ基盤に合わせて設計。
自社の環境で本当に機能するのか。CData は既存のアイデンティティスタックを作り直すことなく、その中にそのまま組み込めます。
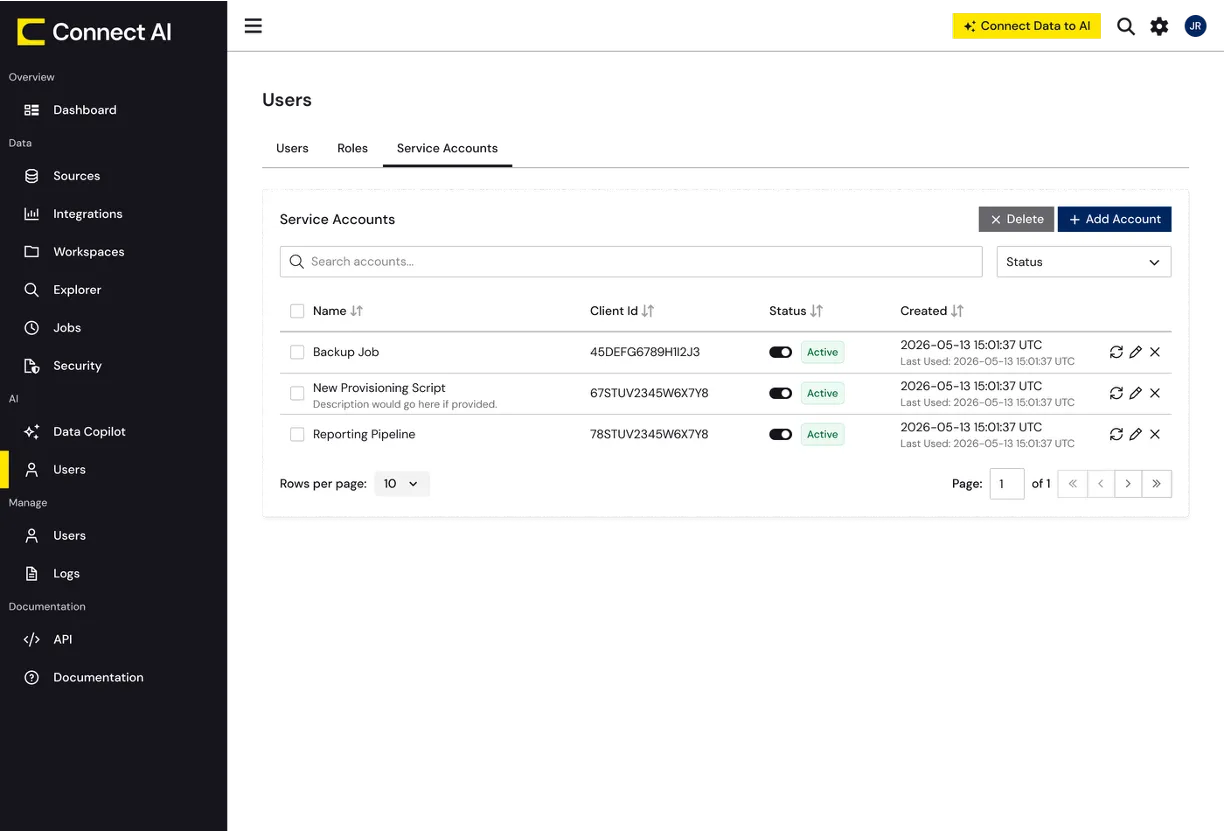
人間、委任、自律のいずれのアイデンティティにも対応。
すべてのやり取りで、実行時に資格情報を検証。
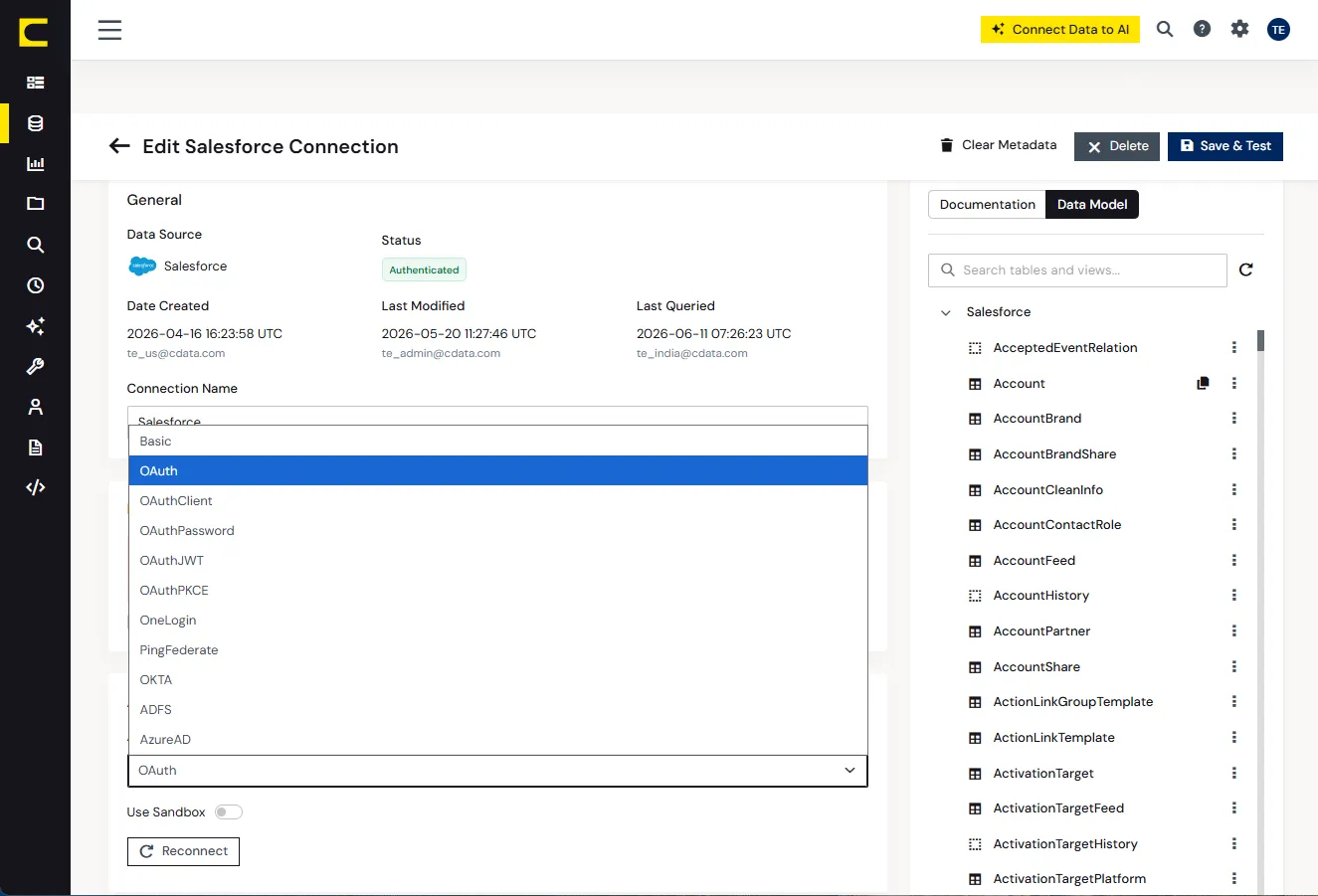
Okta、Azure AD、Ping Identity。
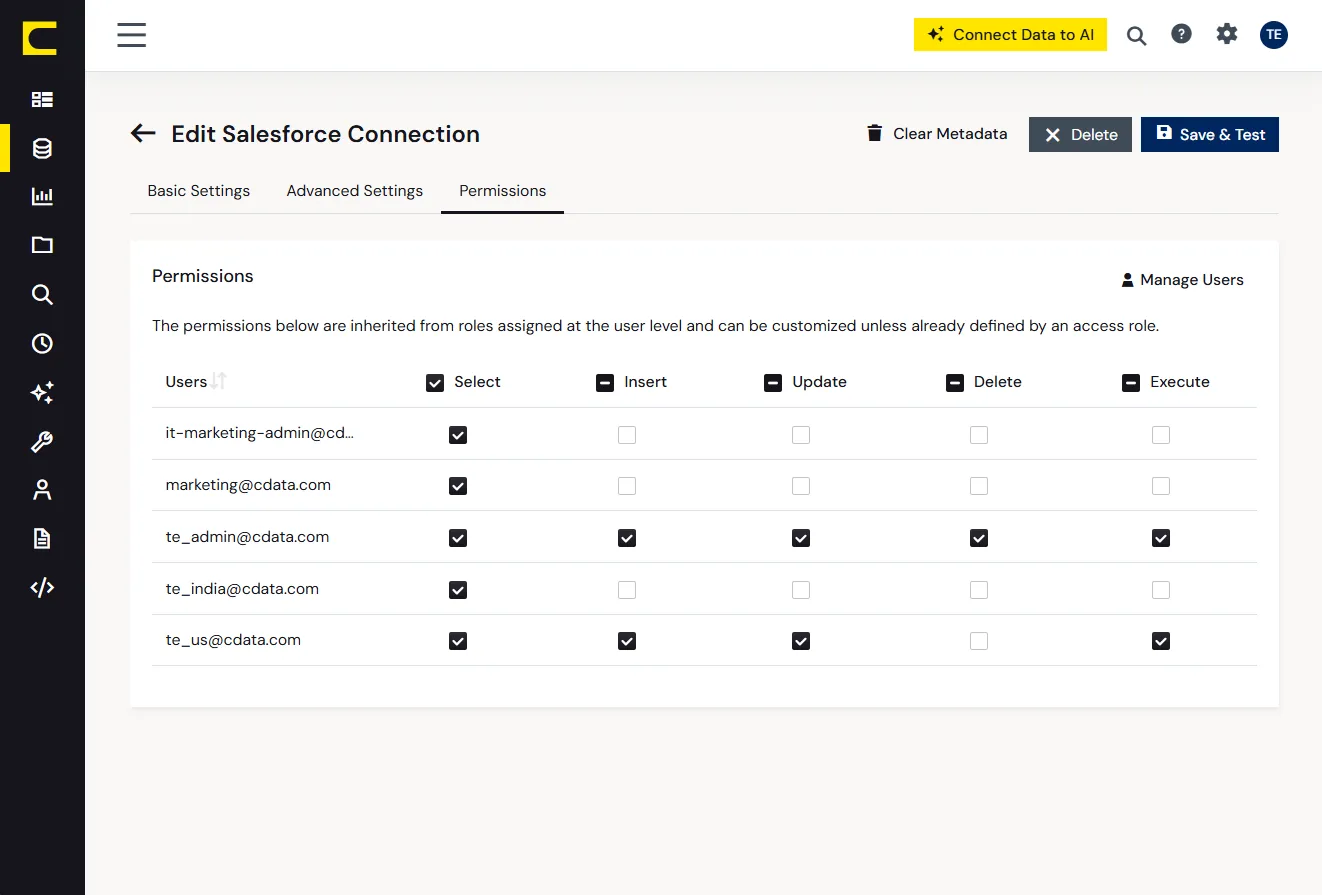
OAuth、SAML、Kerberos、Basic 認証、SSO、RBAC。
SCIM 2.0 に対応し、プロビジョニングとプロビジョニング解除を自動化。
課題
多くの企業の AI 導入は、未成熟または時代遅れのアイデンティティモデルに依存しています。
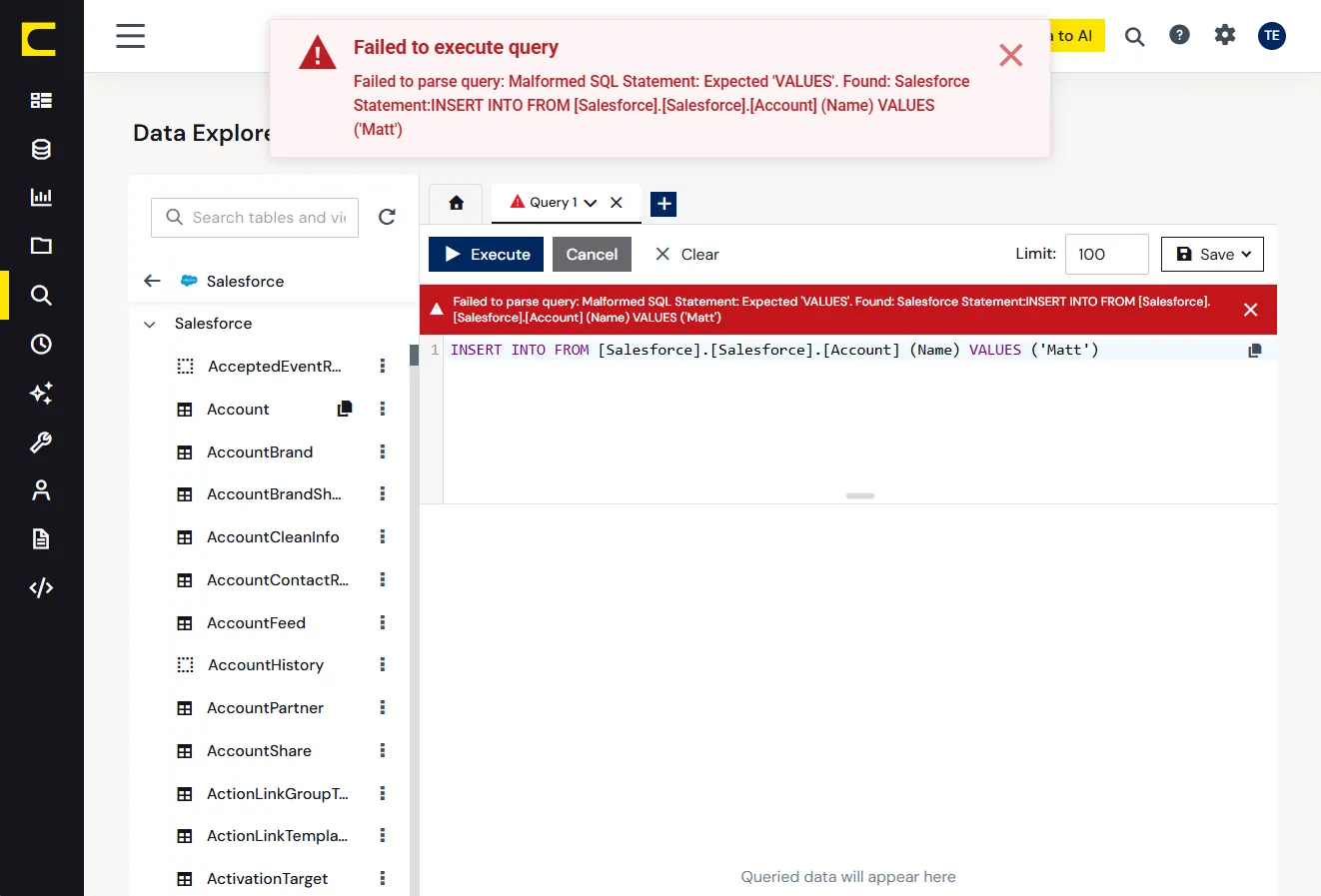
多くの MCP 実装は、サービスアカウントで一度だけ認証を行うため、すべてのユーザーがそのアカウントの広範なアクセス権限を共有する形になります。
多くのプラットフォームでは、権限の広いサービスアカウントを使うか、ワークフローが破綻するかの二択を迫られます。
SSO が機能しなければ、評価は止まってしまいます。手動設定が必要であれば、展開はスケールしません。
PII や機密データが、権限のないユーザーへのクエリレスポンスに表示されてしまいます。
仕組み
CData のパススルーアイデンティティモデルを 5 つのステップで。
アイデンティティをランタイムの基本要素として扱います。すべてのやり取りで評価し、すべてのレイヤーで適用し、すべてのリクエストに対してログを記録します。
ユーザーが AI エージェント(Claude、Copilot、LangChain、その他 MCP 対応プラットフォーム)を通じてリクエストを送信します。
CData はリクエスト元を人間・委任・自律のいずれかとして識別し、適切なアイデンティティモデルにルーティングします。
そのユーザー自身の資格情報が、クエリ実行時にソースシステムへパススルーされます。
解決されたアイデンティティに基づいてガバナンスポリシーが評価され、その後にレスポンスが返されます。
そのやり取りは、複数の権限を組み合わせたスコープの範囲内で実行され、リクエスト元のアイデンティティに紐づけてログに記録されます。
正しいアイデンティティ、正しいデータ、完全な監査証跡を、毎回。