
この記事では「CData Arc ハンズオンセミナー ~はじめてのCData Arc~」の「シナリオ1-1」について進めていきます。
ハンズオン環境へサインイン
CData Arc のハンズオン環境には、こちらからサインインします。
http://localhost:8001/
項目 | 設定する内容 |
ユーザー名 | admin |
パスワード | ハンズオン環境のクレデンシャル情報を参照してください |
ハンズオンのシナリオ
業務システムのデータストアなどで利用されているデータベースからSaaS へのデータ連携は、よくあるシナリオです。
このシナリオではMySQL から取得(Select)したデータをkintone に更新(Upsert)します。
MySQL の構成
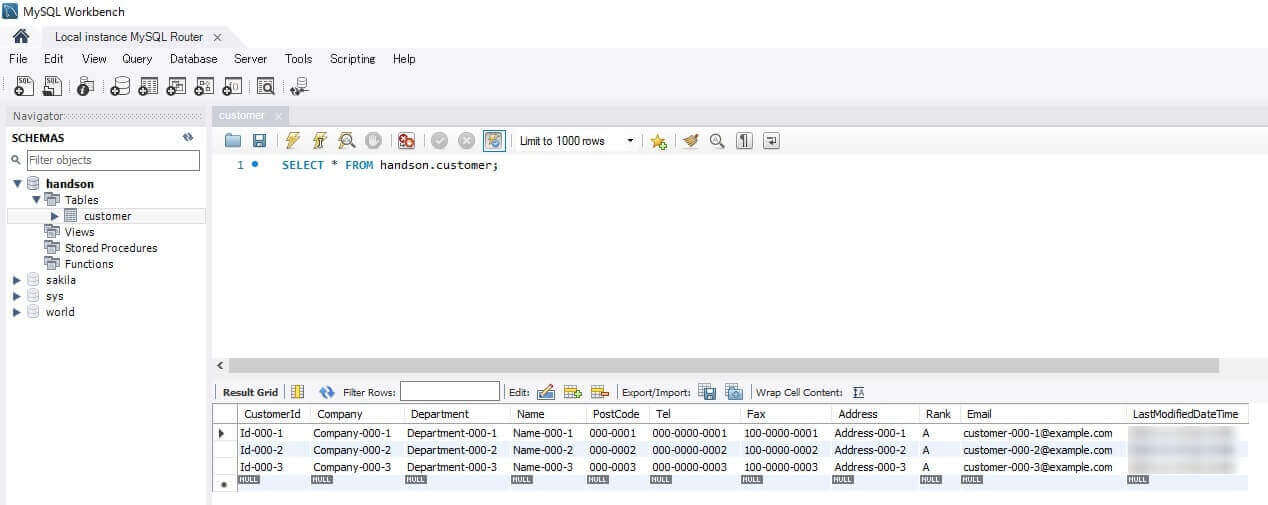
このシナリオでは、ハンズオン実行環境に構成されているMySQL のhandson スキーマの「Customer」テーブルからデータを取得します。
kintone の構成
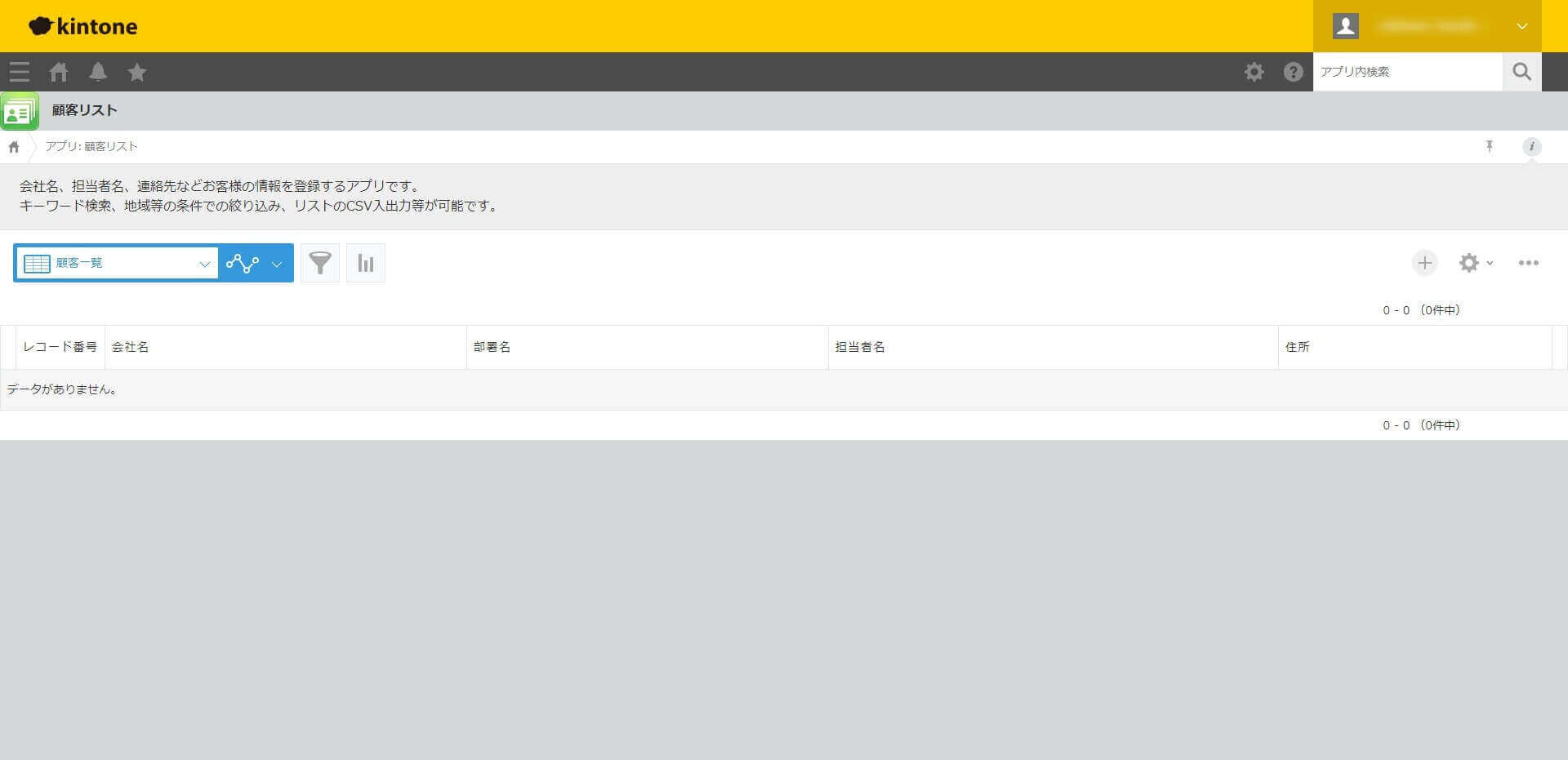
このシナリオでは、ハンズオン用に用意されているkintone の「顧客リスト」アプリへデータを更新します。
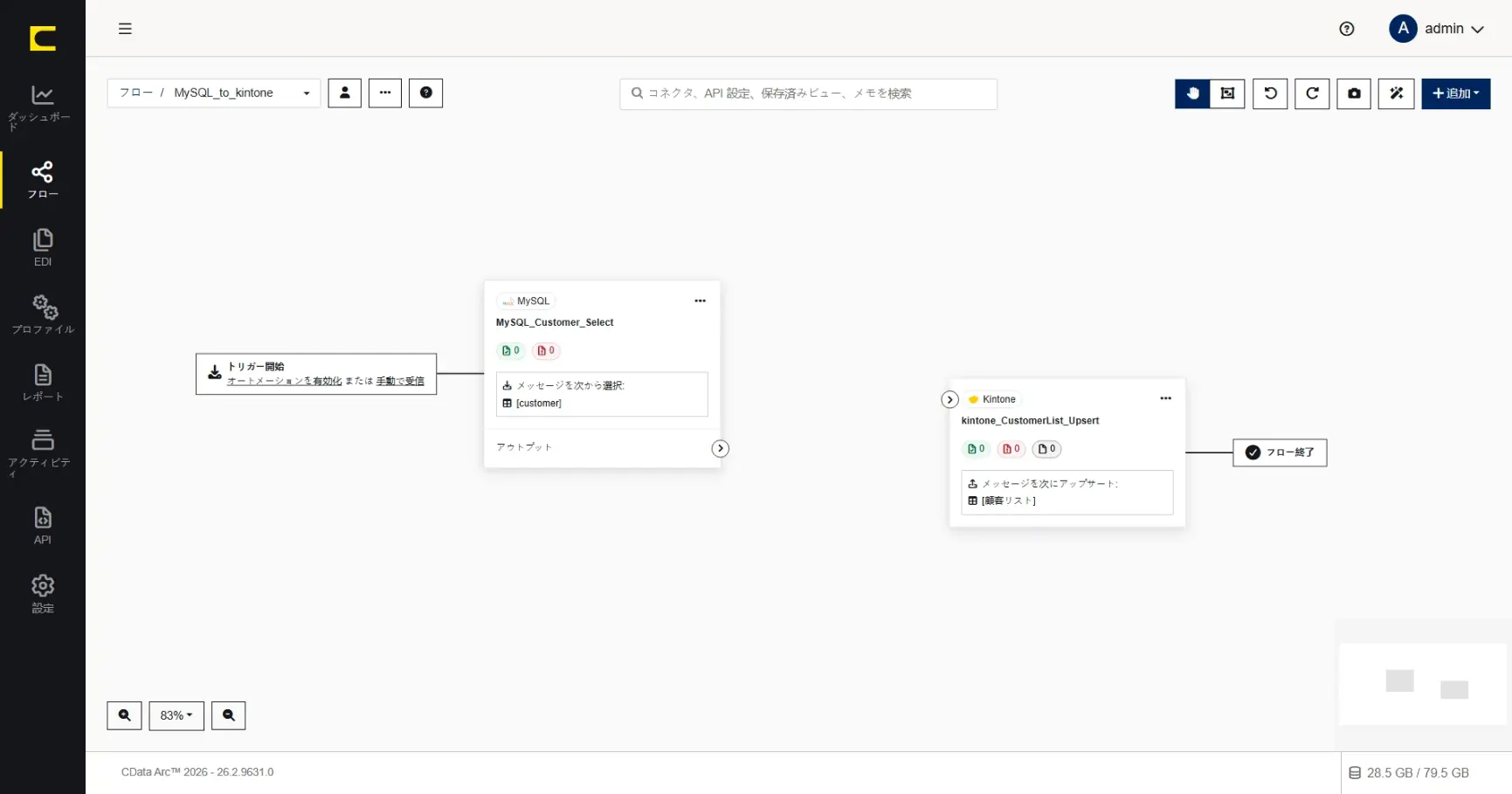
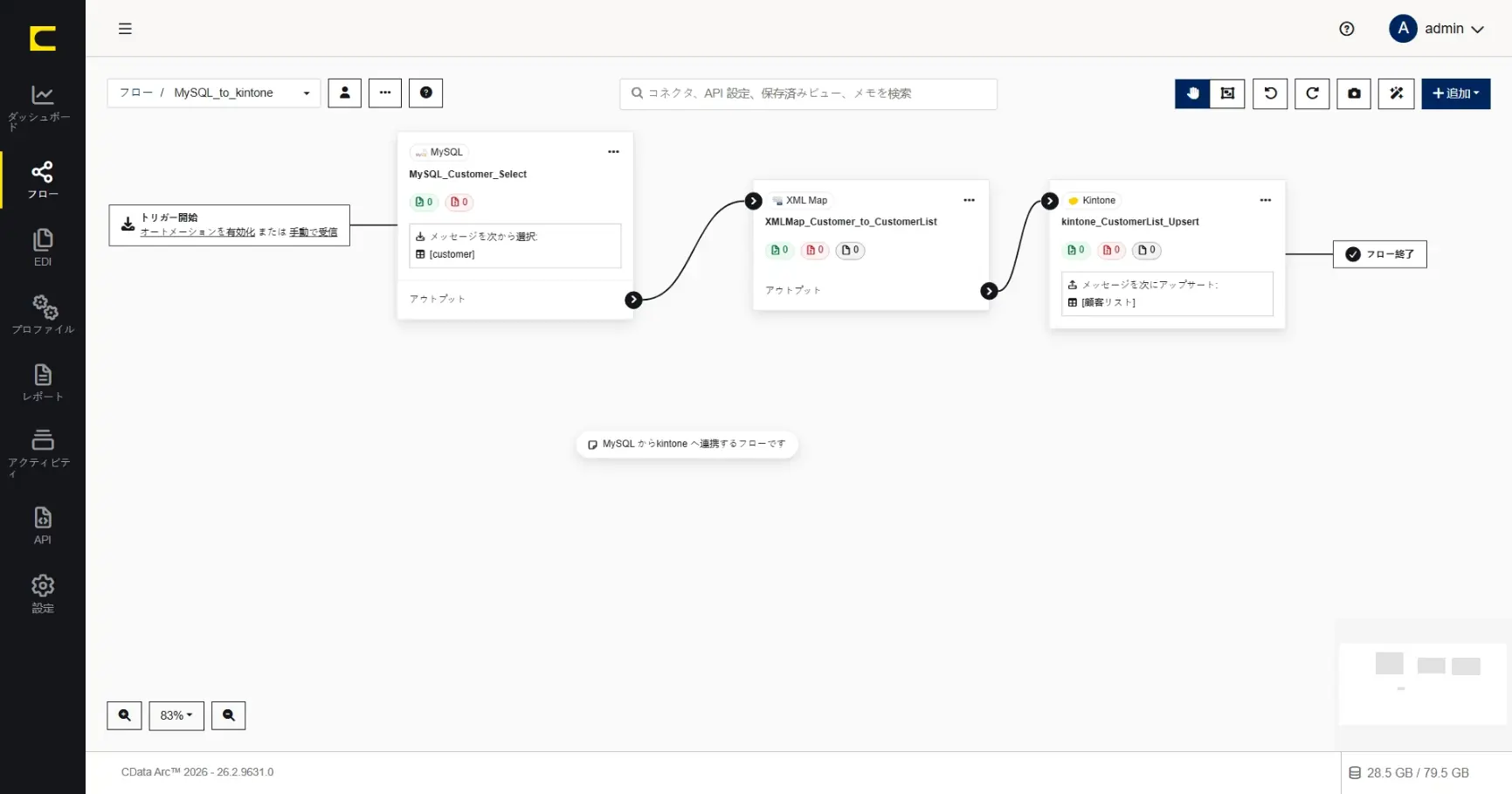
連携フローの概要
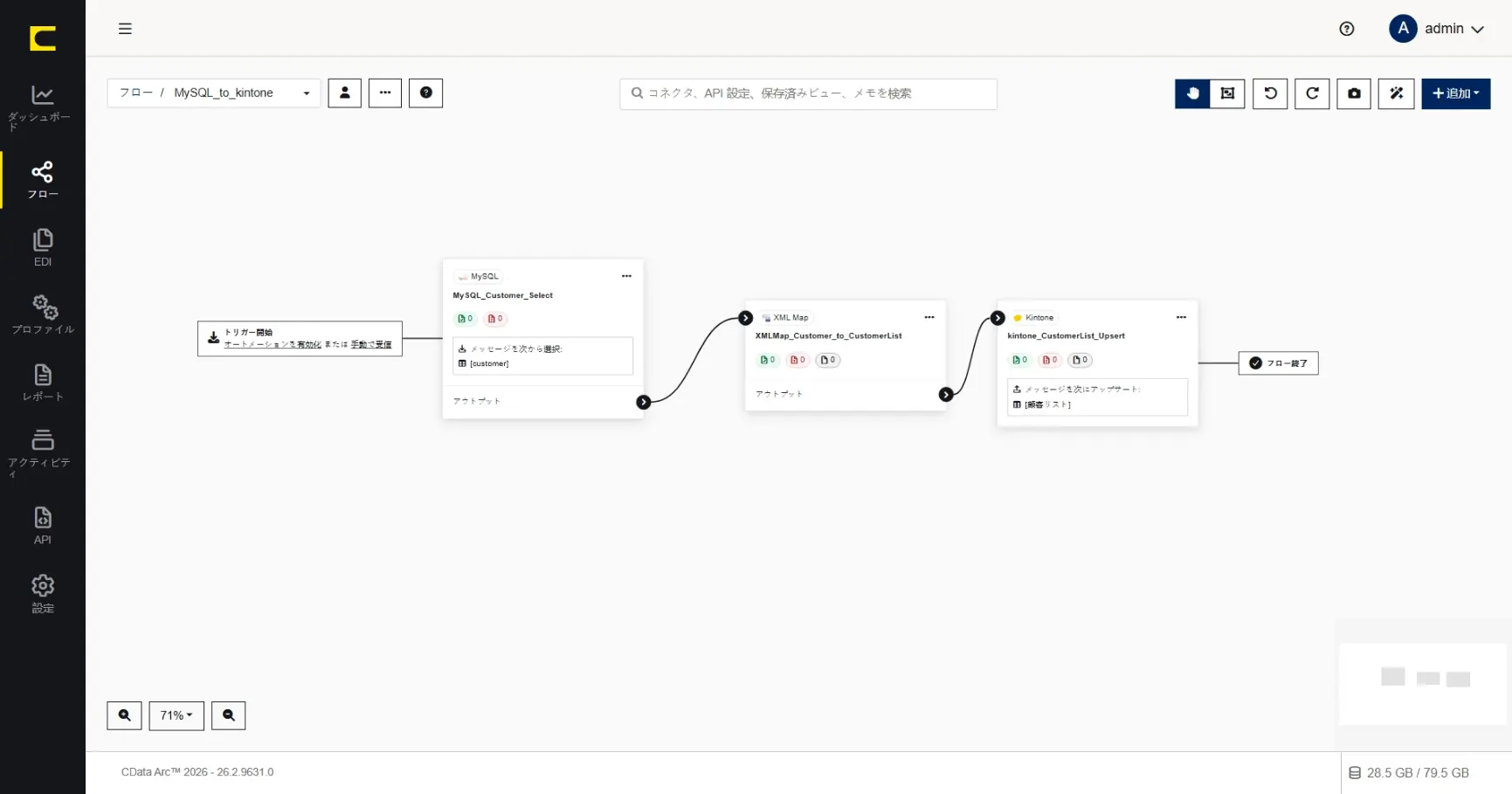
このシナリオでは、このような連携フローを作成していきます。
| コネクタ | 設定内容 |
1 | MySQL | MySQL からデータを取得(Select) |
2 | XMLMap | 1 と3 をマッピング |
3 | Kintone | kintone へデータを更新(Upsert) |
ワークスペースの作成
CData Arc では、目的の異なる連携フローを分離できるように、任意の「ワークスペース」を作成することができます。ワークスペースを作成するにはフローページの「ワークスペースを追加」をクリックします。
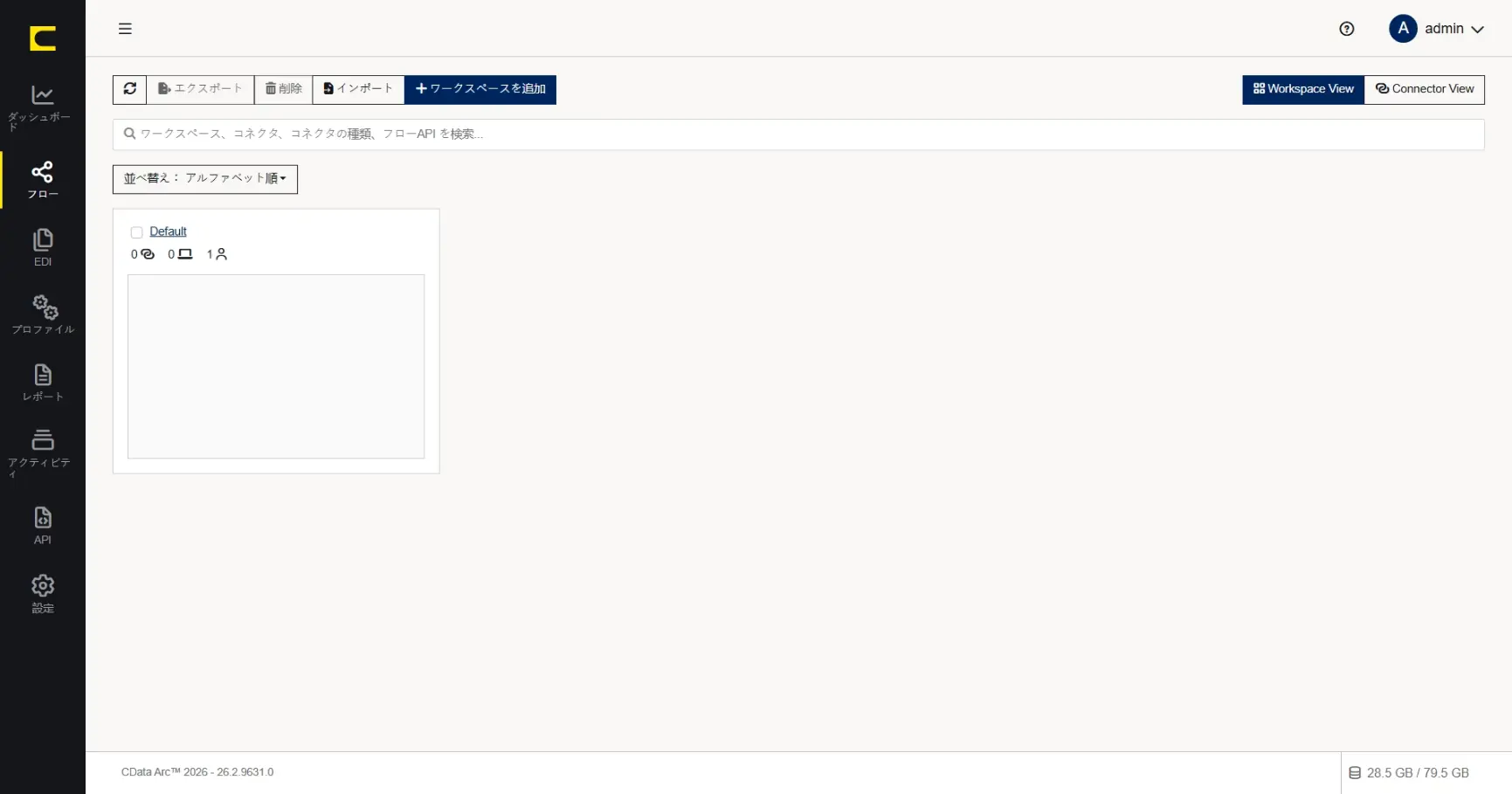
ワークスペース名には任意の名称を設定することができます。何のためのワークスペースか、分かりやすい名前を設定します。ここでは「MySQL_to_kintone」と設定します。
このシナリオでは、この「MySQL_to_kintone」ワークスペースにフローを作成していきます。
MySQL コネクタ
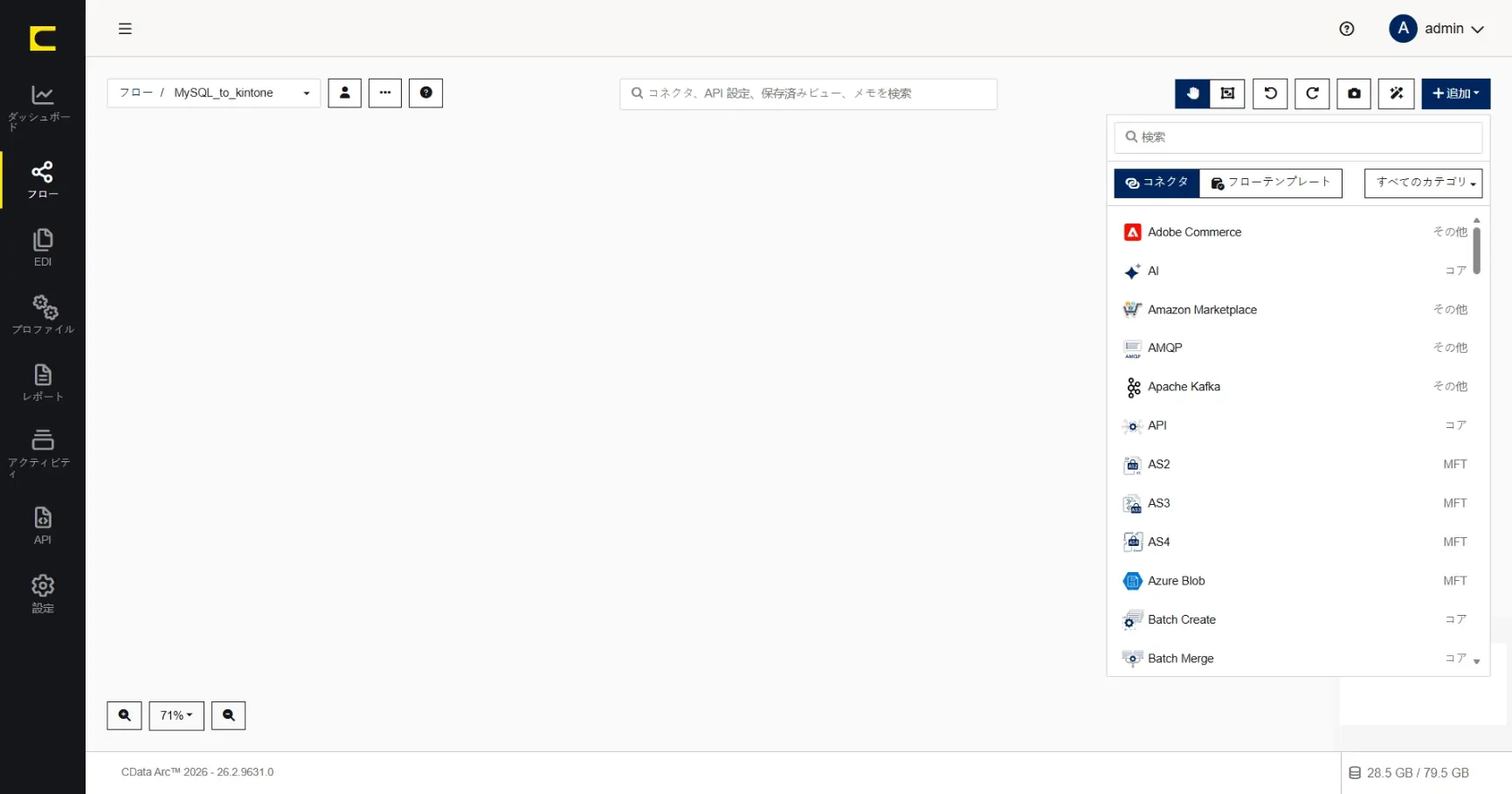
最初に「MySQL のcustomer テーブルからSelect(データを取得)」するMySQL コネクタを設定します。この連携フローのはじまり(起点)となるコネクタです。
コネクタは右上の「+追加」から選択や検索をして追加することができます。またフローキャンバス上での右クリックなどからも追加することができます。
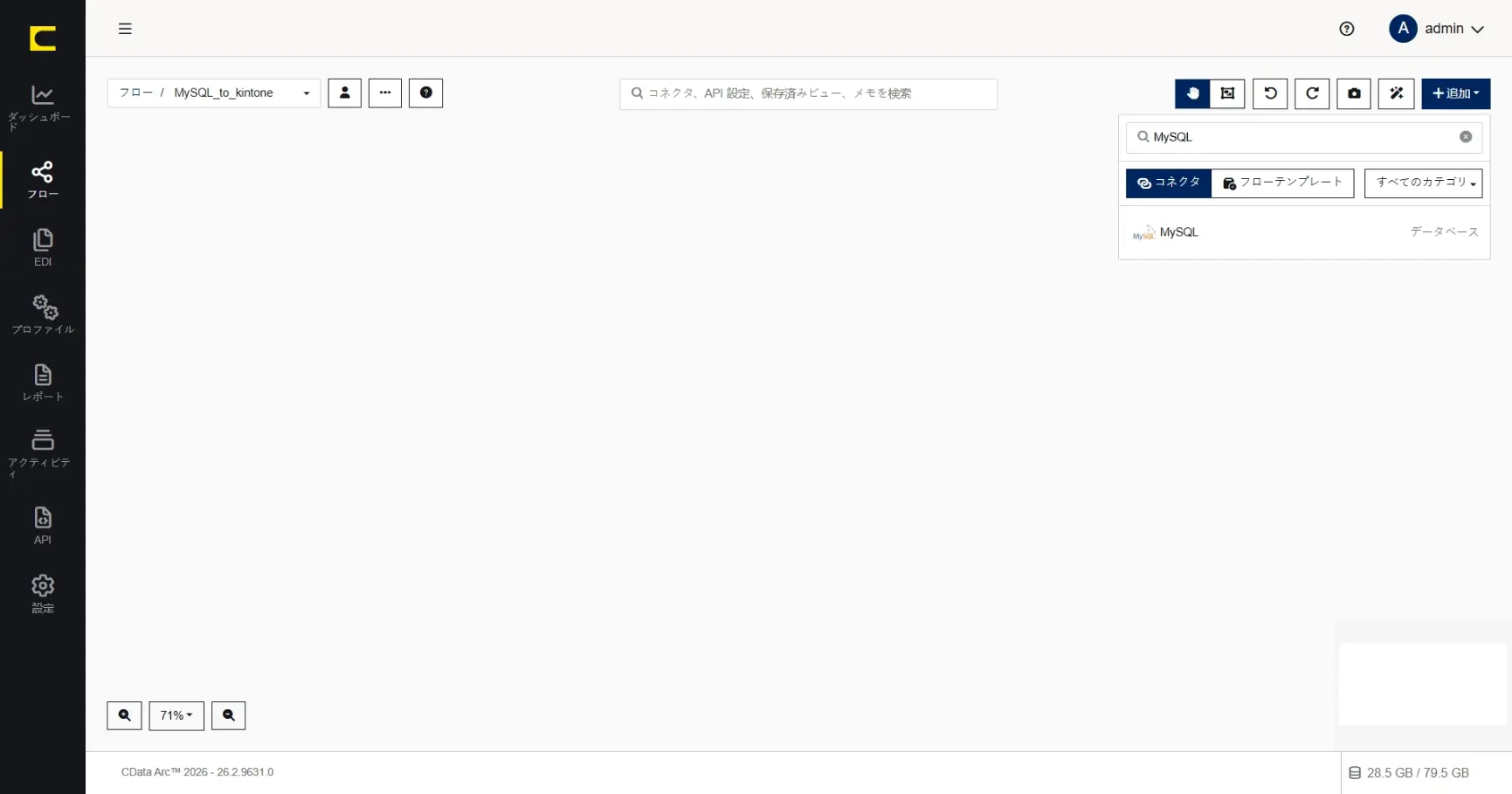
コネクタID には任意の名称を設定することができます。何を行うコネクタか、分かりやすい名前を設定します。ここでは「MySQL_Customer_Select」と設定します。
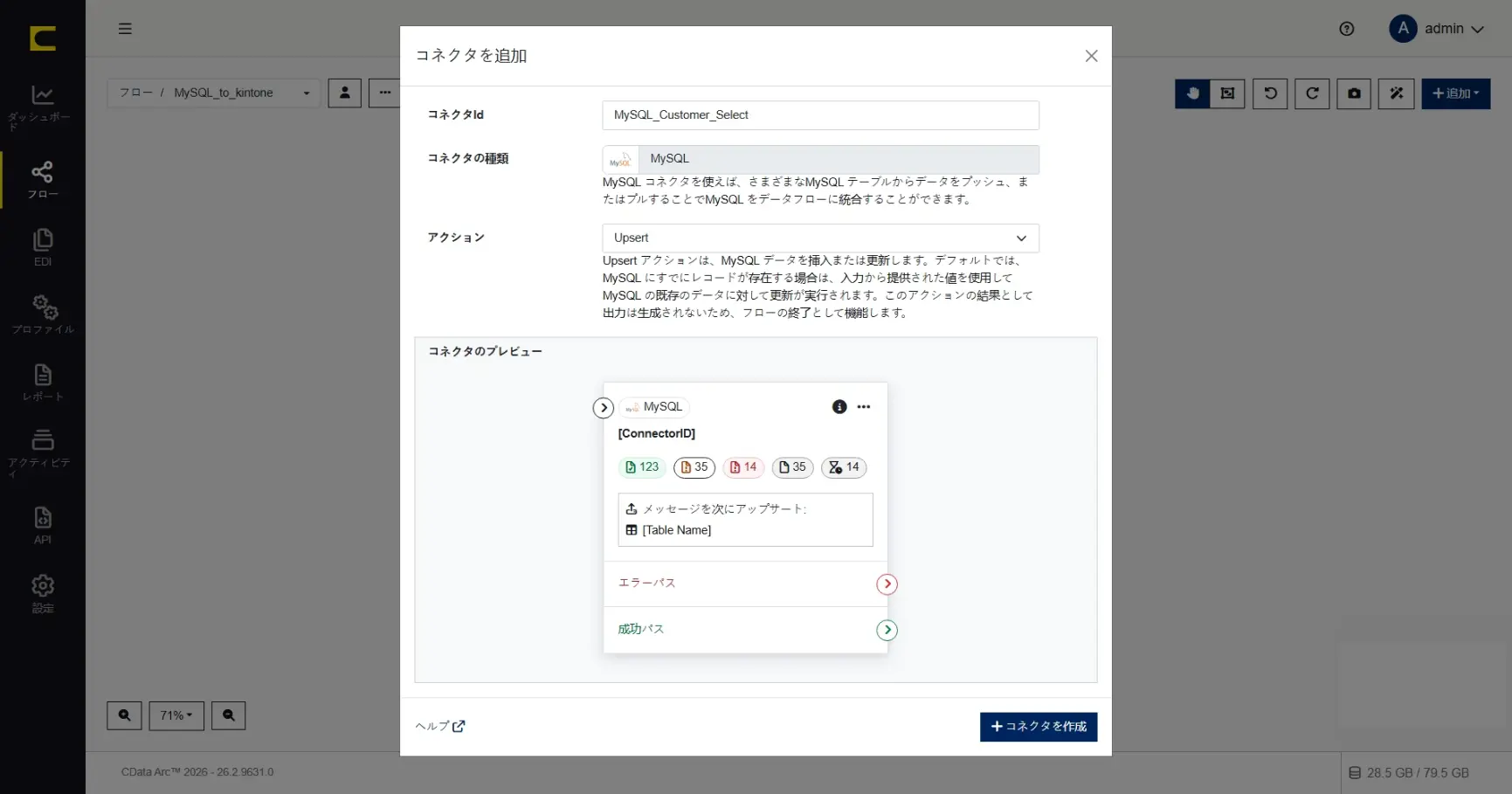
このコネクタが実行するアクションも指定します。ここではデータを取得するための「Select」アクションを選択して「+コネクタを作成」します。
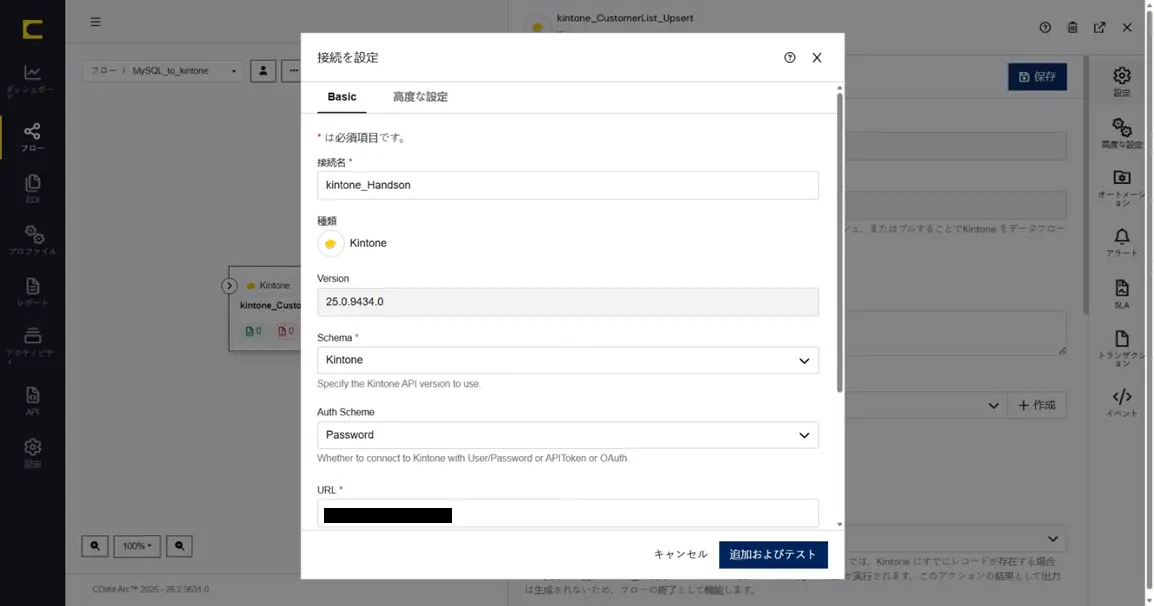
接続の作成
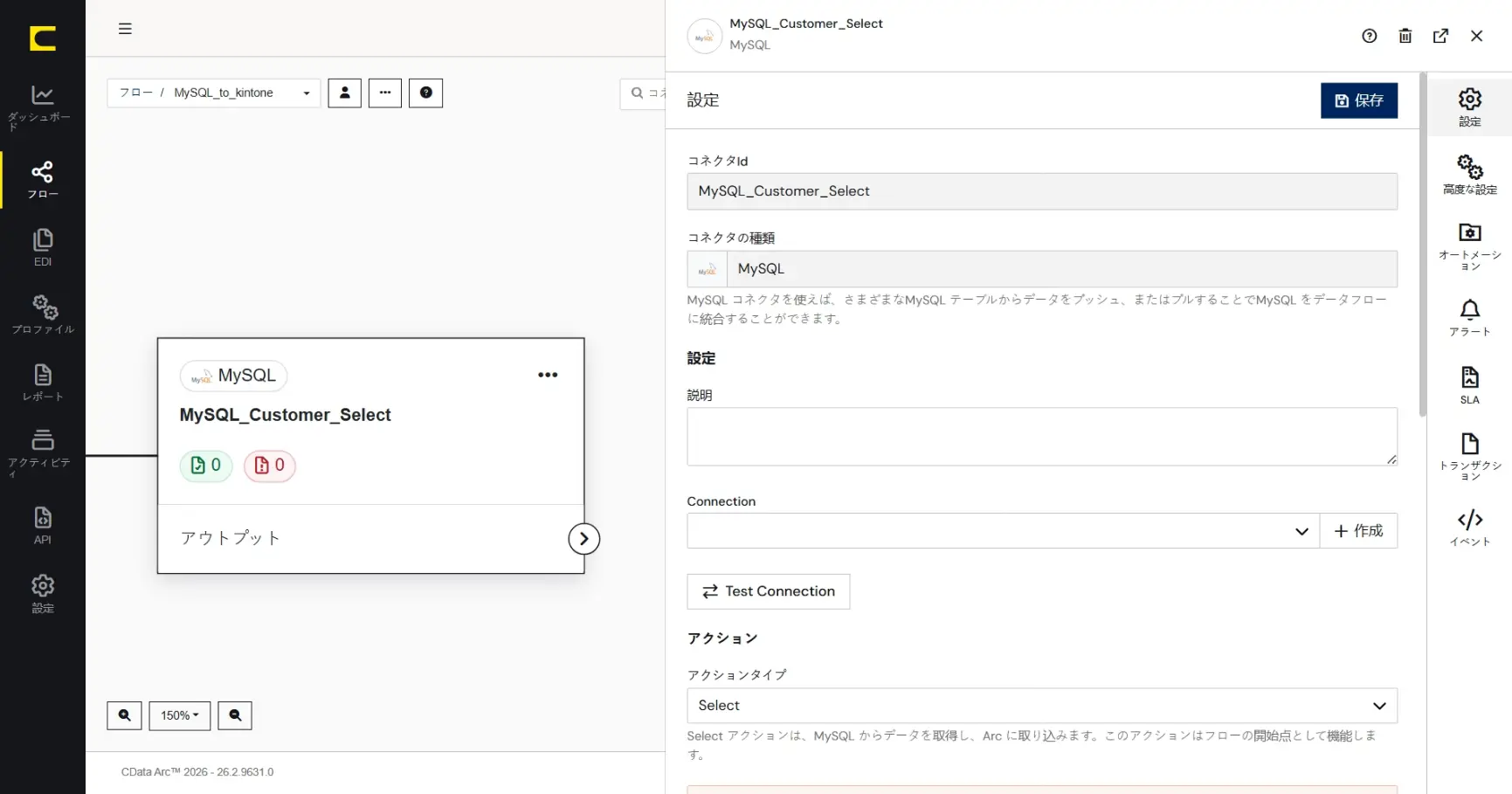
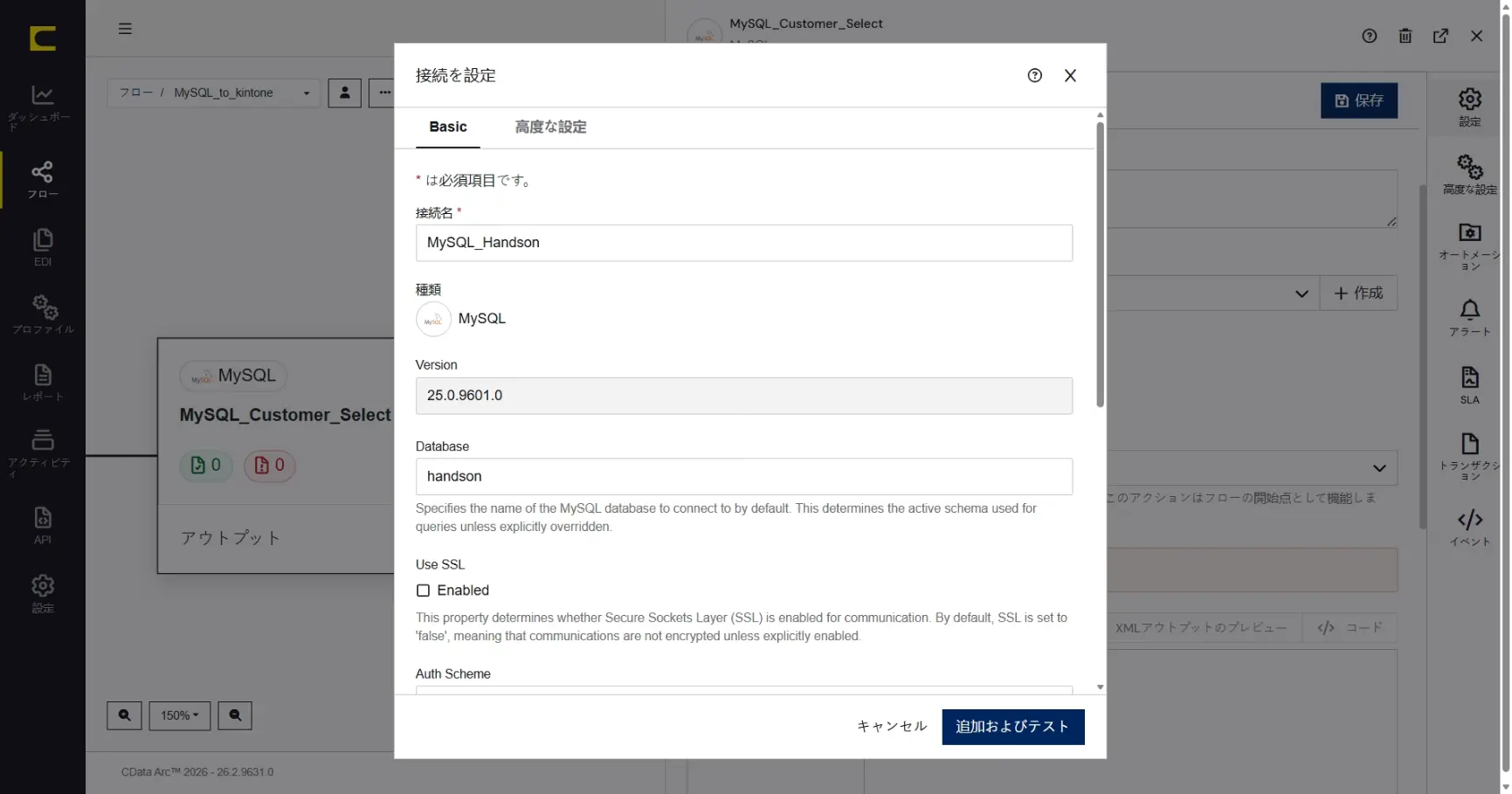
作成したコネクタの設定に移ります。MySQL への接続情報を作成します。「Connection」の「作成」をクリックします。ここで作成した「Connection」は、他のMySQL コネクタでも利用することができます。
「接続の追加」ダイアログで、ハンズオンで利用するMySQL への接続を作成していきます。名前には任意の名称を設定することができます。識別しやすい名前を設定します。ここでは「MySQL_Handson」と設定します。
接続に必要な以下の情報を設定します。
項目 | 設定する内容 |
Server | ハンズオン環境のクレデンシャル情報に従って設定します |
Port | 3306 |
Database | ハンズオン環境のクレデンシャル情報に従って設定します |
User | ハンズオン環境のクレデンシャル情報に従って設定します |
Password | ハンズオン環境のクレデンシャル情報に従って設定します |
設定したら「追加およびテスト」で作成します。作成されたら、接続テストも成功です。
Connection を作成したら、警告メッセージが表示されていますので、コネクタの設定を一度保存します。
アクション
MySQL へのアクション(実行する操作)は先ほど選択した「Select」アクションで構成されています。なお、あとからアクションを変更することもできます。
テーブル
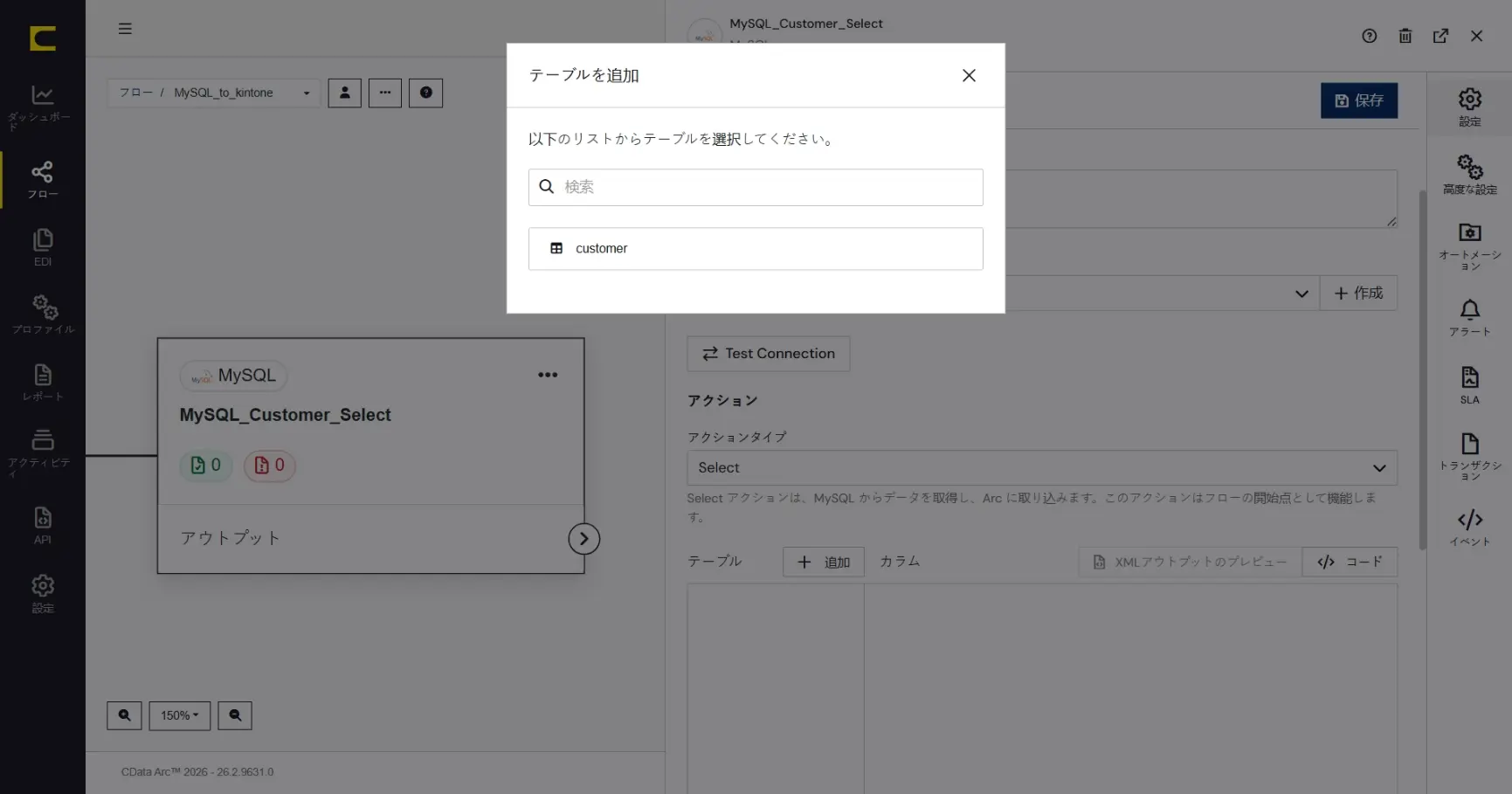
MySQL からデータをSelect するテーブルを選択します。「+ 追加」をクリックして「テーブルの追加」ダイアログを開きます。
「Customer」テーブルを選択して「+追加」をクリックします。「テーブル」に「Customer」が追加され、「カラム」に「Customer」テーブルの列構成が反映されます。「フィルタ」「並べ替え」「クエリ」で取得設定を細かく指定することもできます。対象テーブルの構成次第では「高度な設定」により差分取得を利用することもできます。
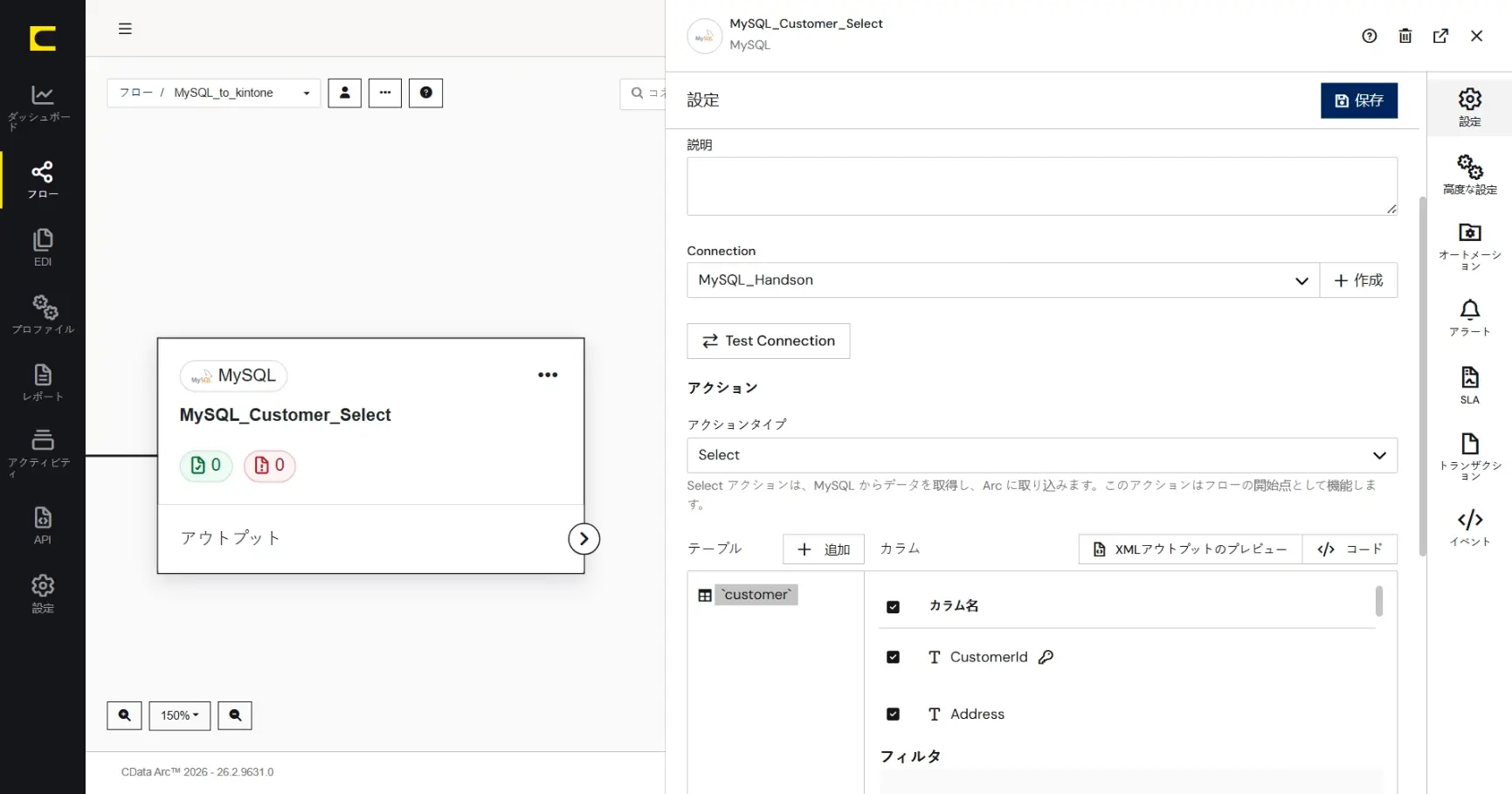
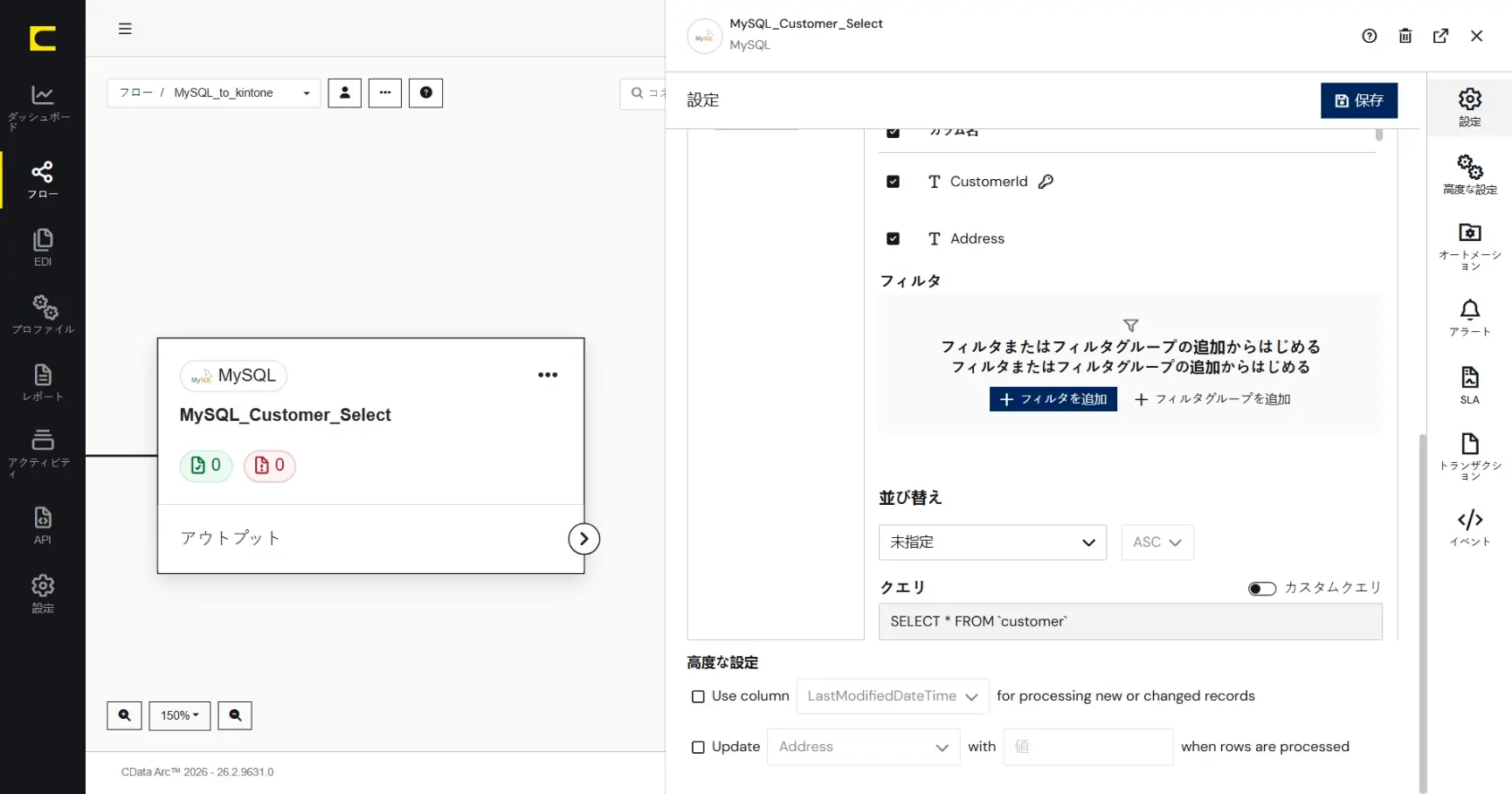
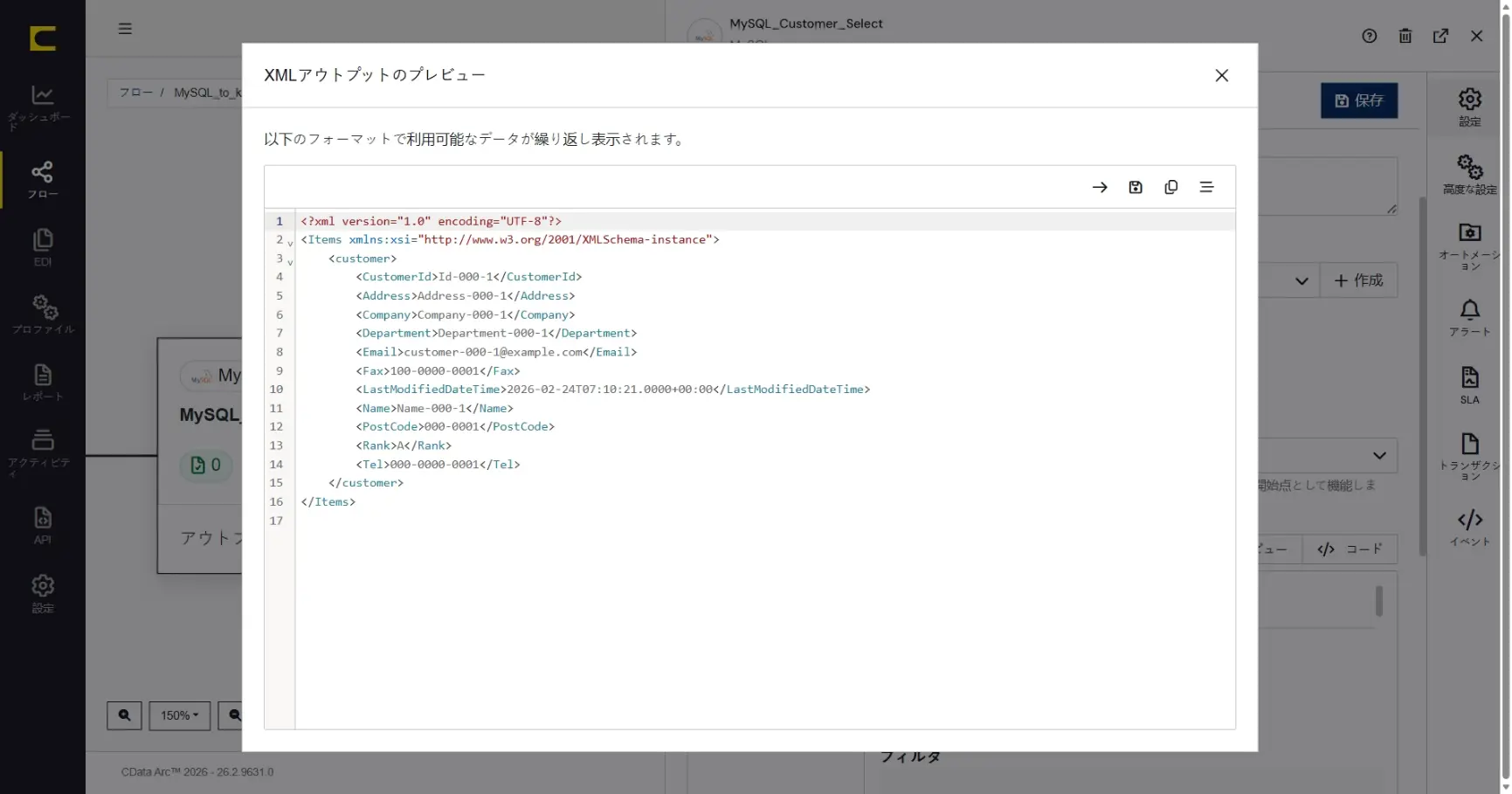
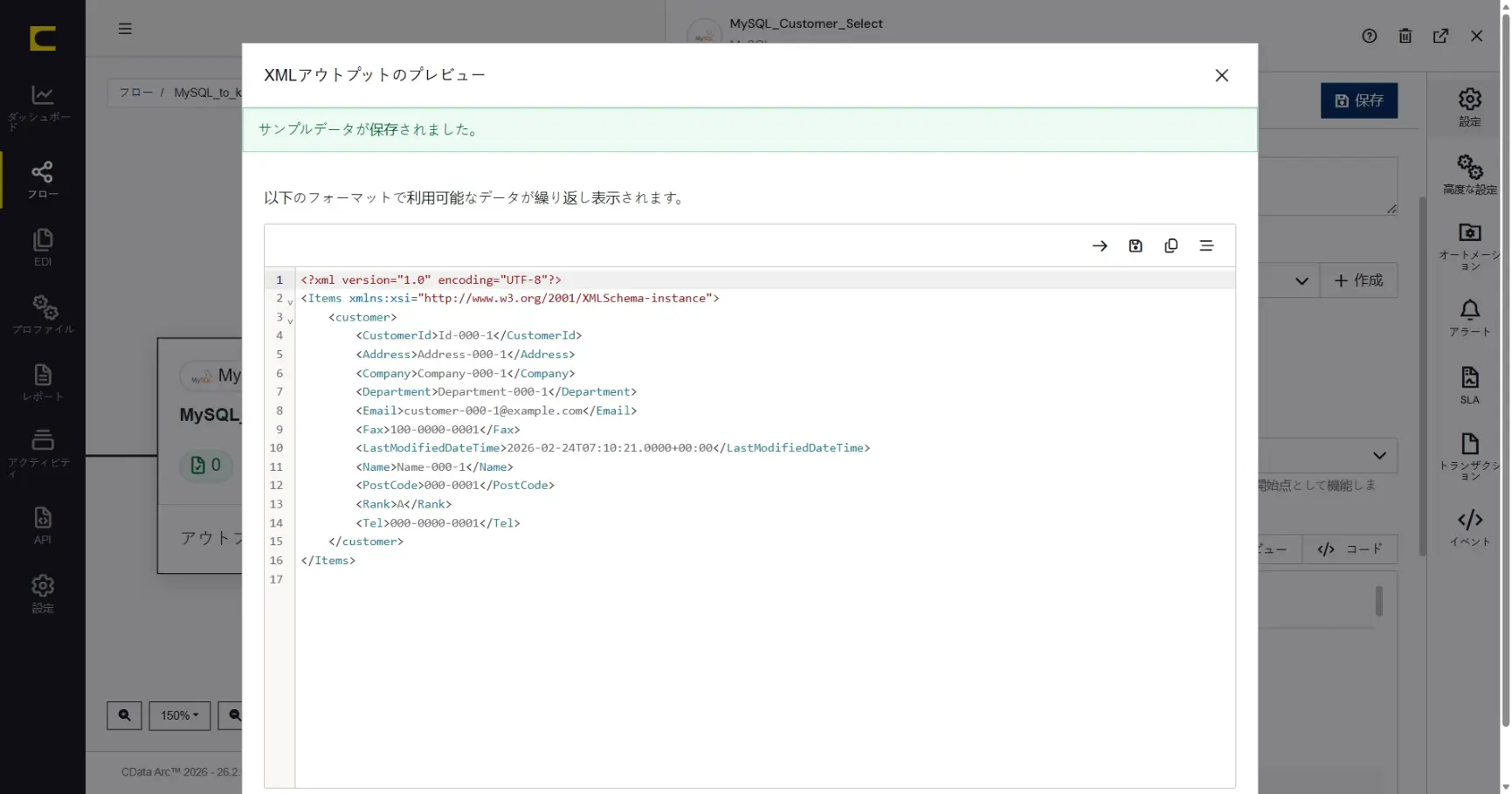
「XML アウトプットのプレビュー」することで、コネクタからの出力データをプレビューすることができます。プレビューにより取得されるデータを簡単に確認することができます。
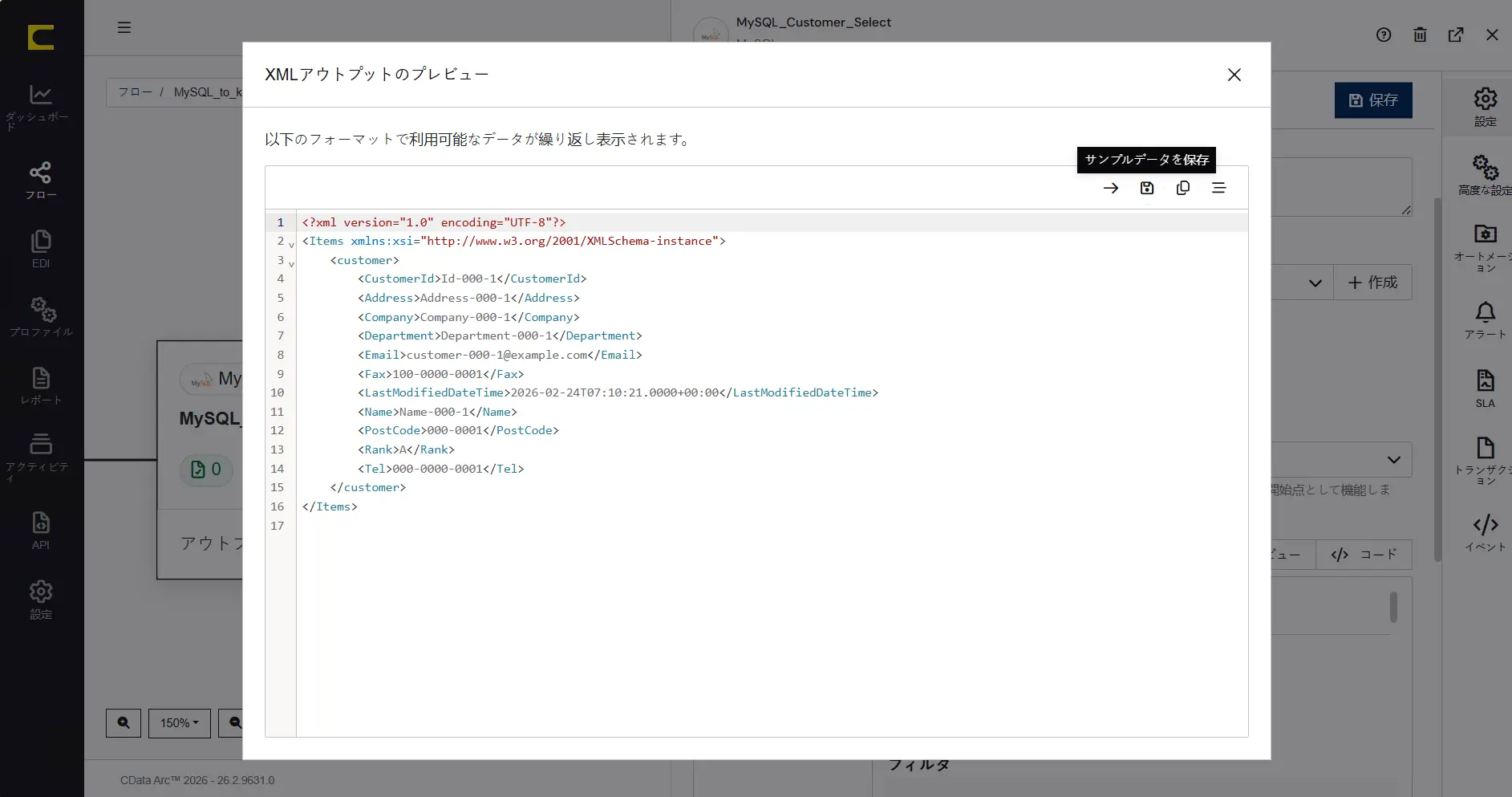
後続のXML Map コネクタの設定をより分かりやすく実施できるように「サンプルデータを保存」しておきます。「サンプルデータを保存」しておくと、XML Map のマッピングエディタ上で、データソース側にデフォルトのサンプルデータが表示された状態になりますので、マッピングを施す際にもより判断しやすくなります。
「保存」で、コネクタの設定を保存します。これでMySQL コネクタの設定は完了です。
取得(受信)のテスト
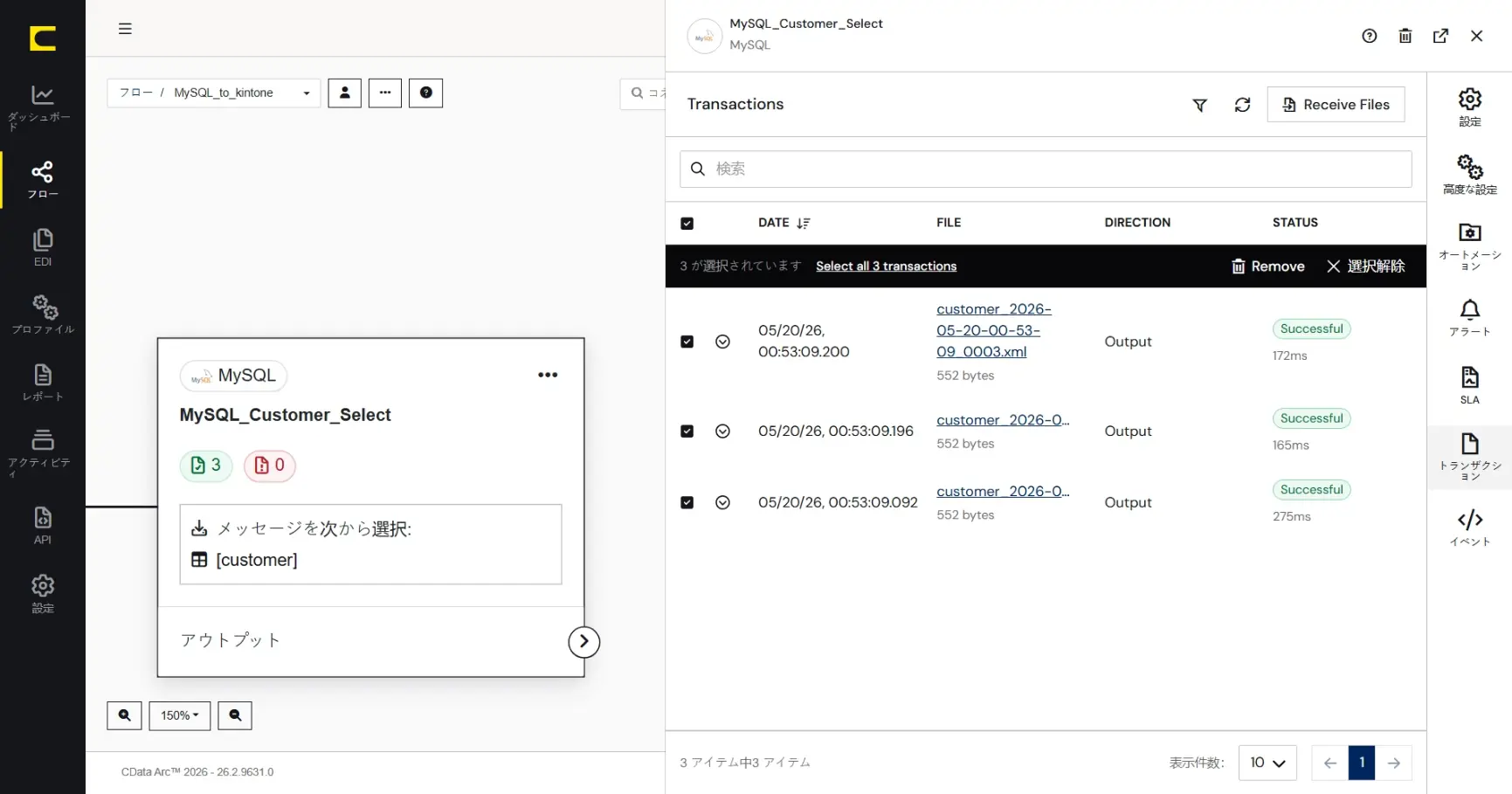
実際にデータを取得できることを確認してみます。「トランザクション」タブの「Receive Files」をクリックします。
MySQL コネクタでは、デフォルトでは取得したデータがレコード単位にメッセージファイルとして生成されます。
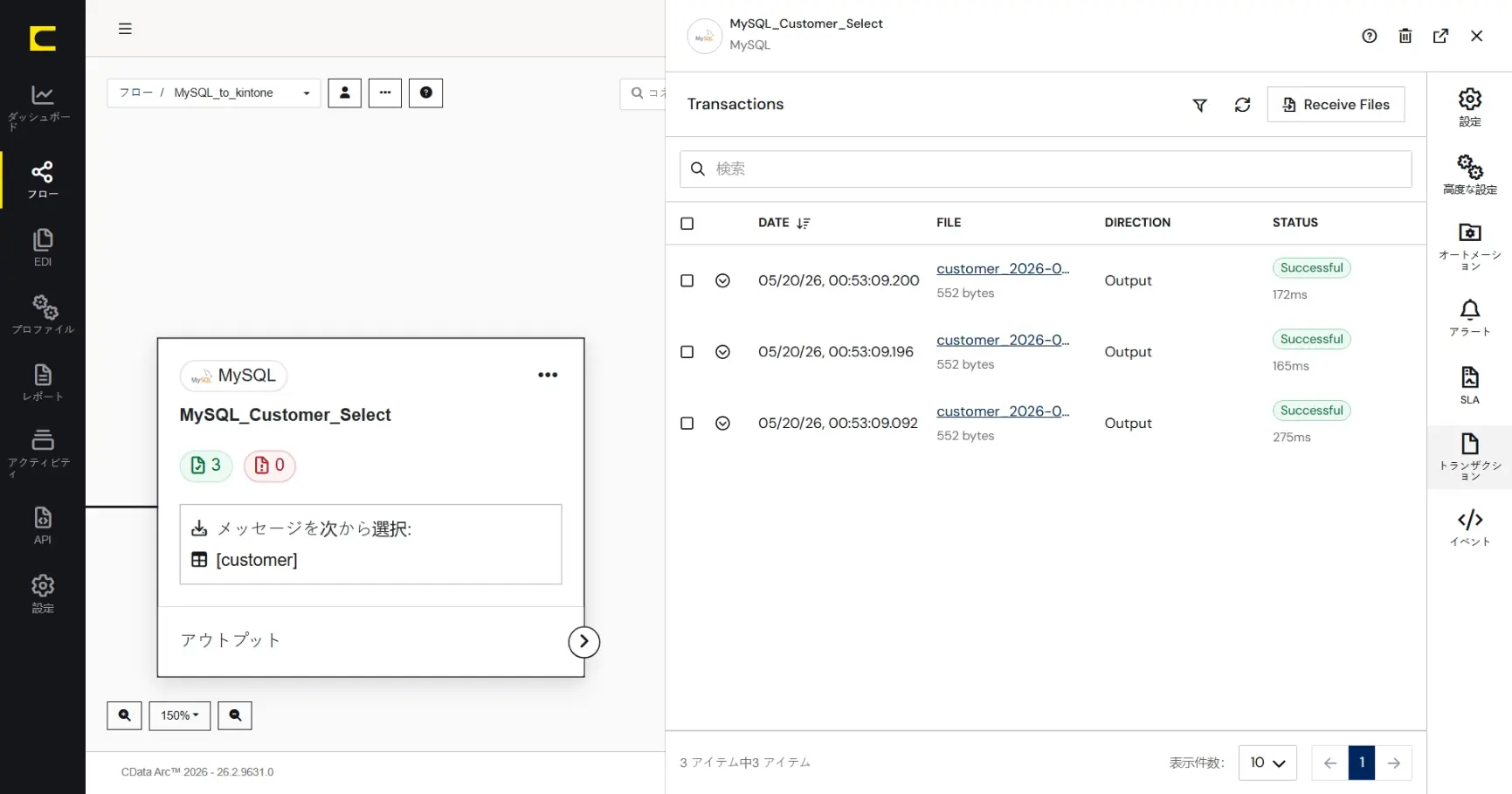
メッセージファイル名をクリックすると、データを確認することができます。
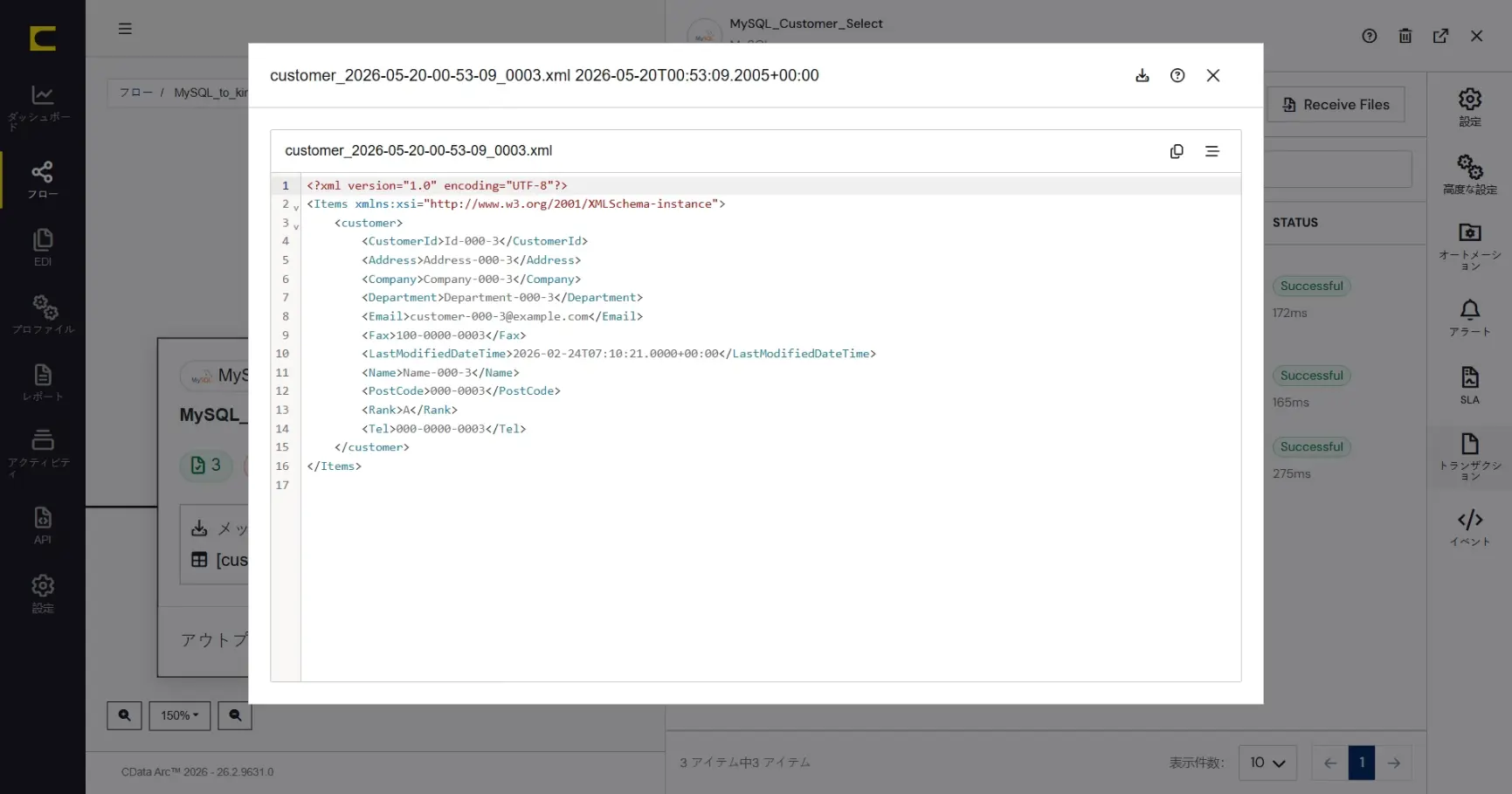
また各レコード左端の下矢印で展開すると、CData Arc が自動的に付与するメッセージファイルのメタデータ(メッセージヘッダ)やログの内容を確認することができます。メッセージファイルやログはダウンロードすることもできます。
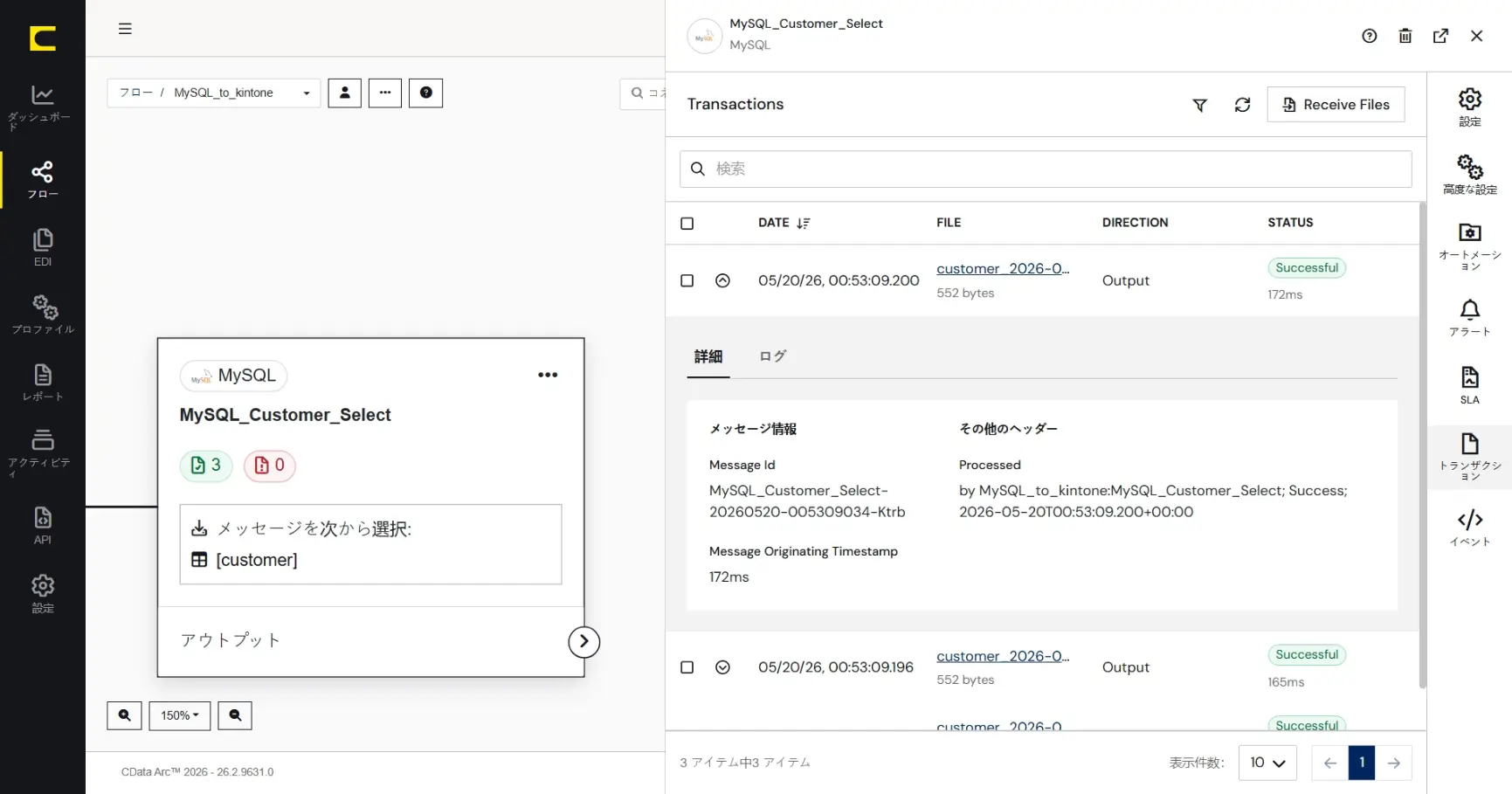
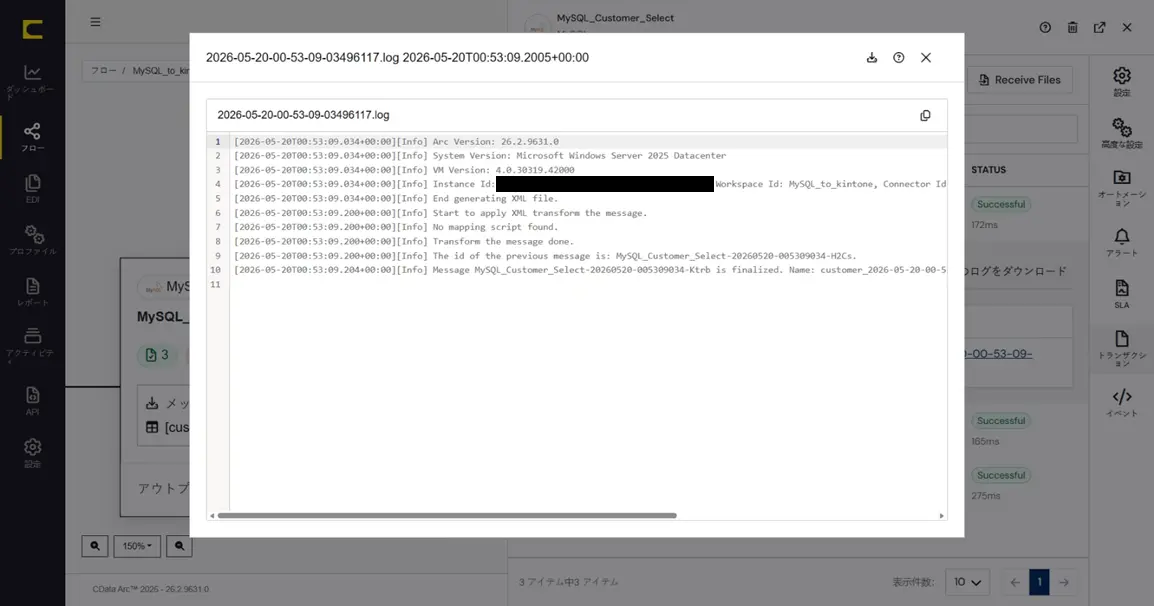
このようにCData Arc ではコネクタ単位に設定や動作を確認しながらフロー作成を進めることができます。
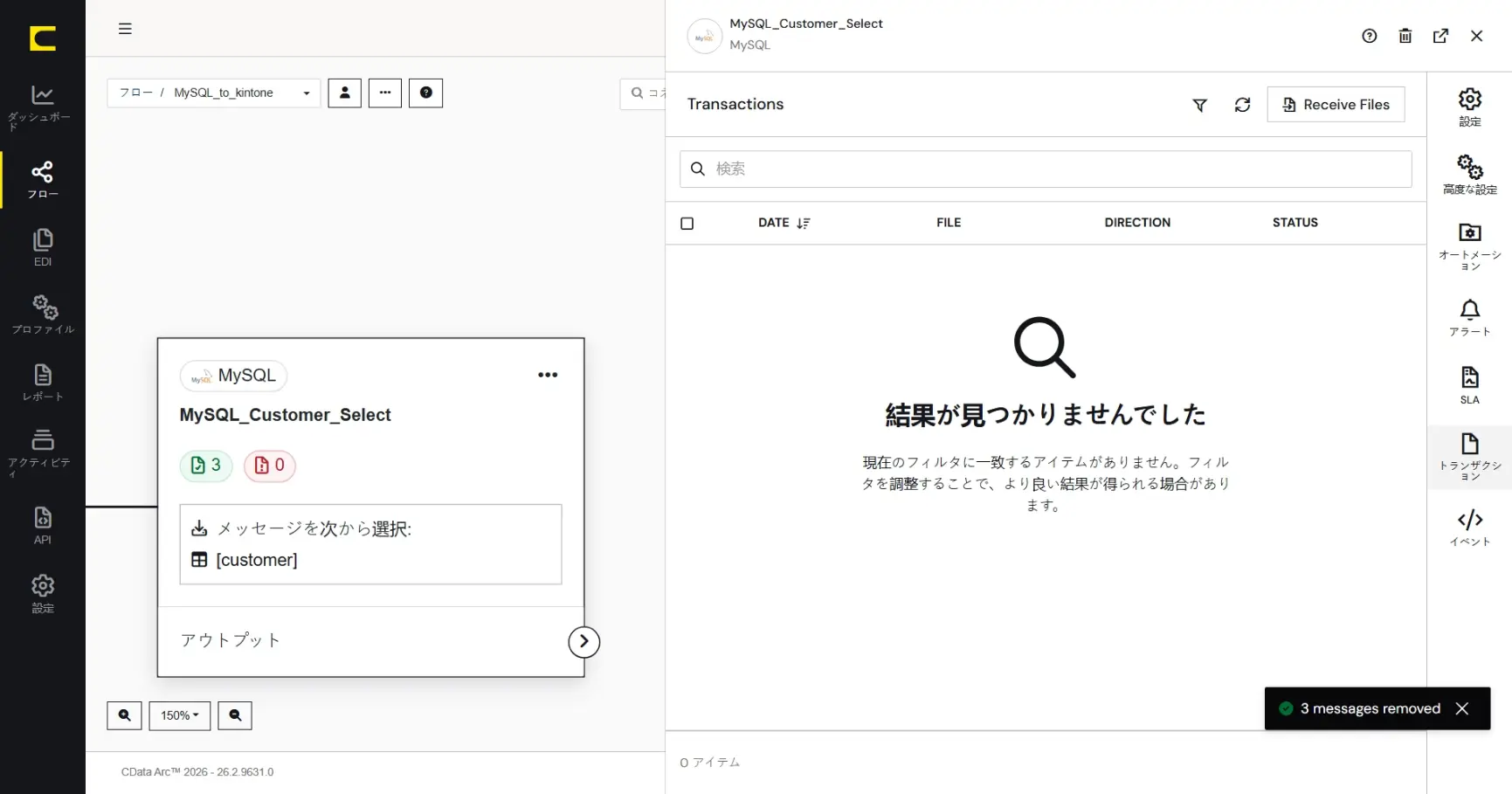
テストで取得(受信)したメッセージやログは、選択して「削除」できます。
Kintone コネクタ
次に「kintone の顧客リストへUpsert(データを更新)」するKintone コネクタを設定します。この連携フローのおわり(終点)となるコネクタです。
コネクタは右上の「+追加」から選択や検索をして追加することができます。またフローキャンバス上での右クリックなどからも追加することができます。今回はフローキャンバス上での右クリックから「+コネクタを追加」してみましょう。
コネクタID には任意の名称を設定することができます。何を行うコネクタか、分かりやすい名前を設定します。ここでは「kintone_CustomerList_Upsert」と設定します。
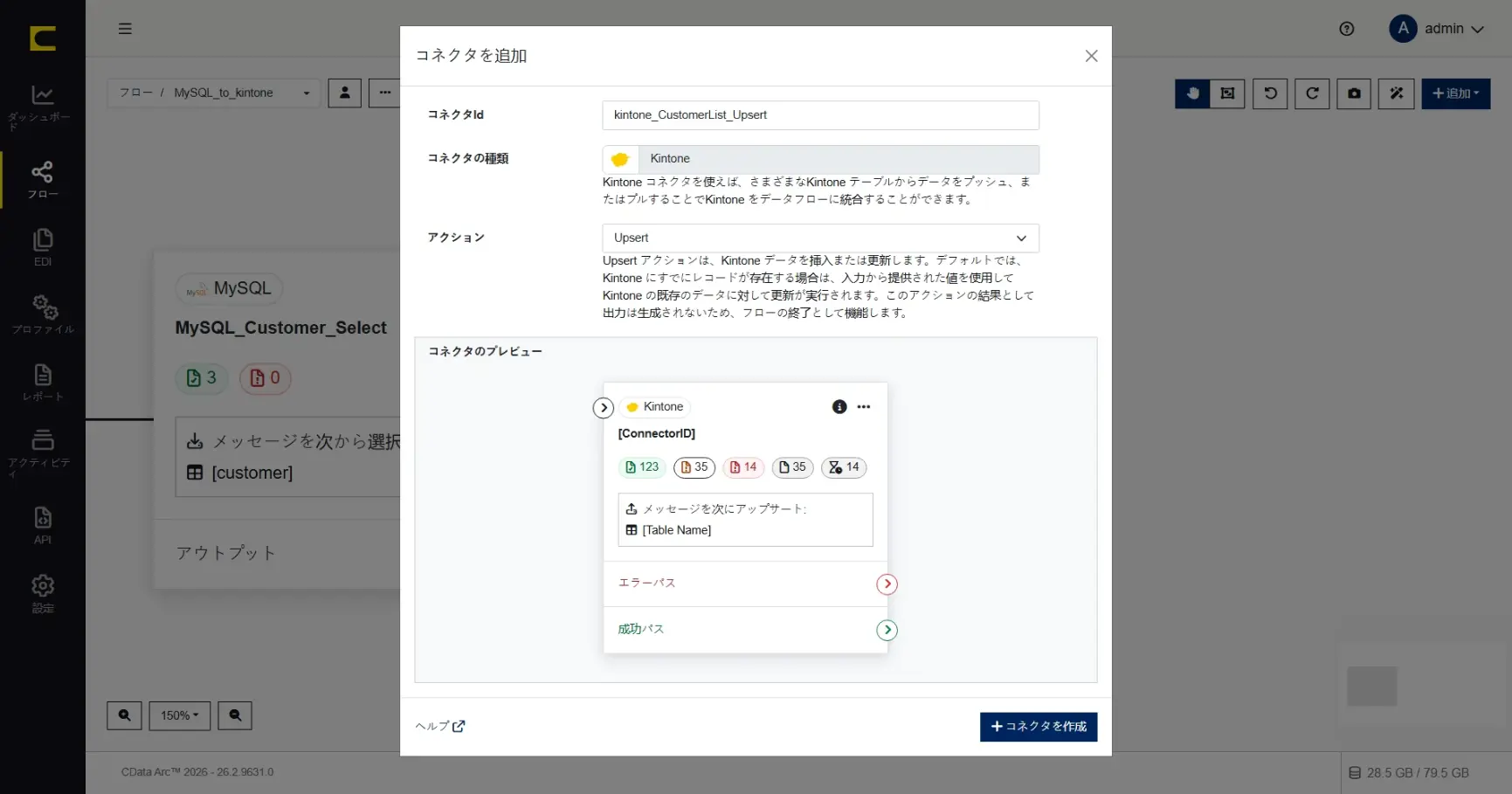
このコネクタが実行するアクションも指定します。ここではデータを更新するための「Upsert」アクションを選択して「+コネクタを作成」します。
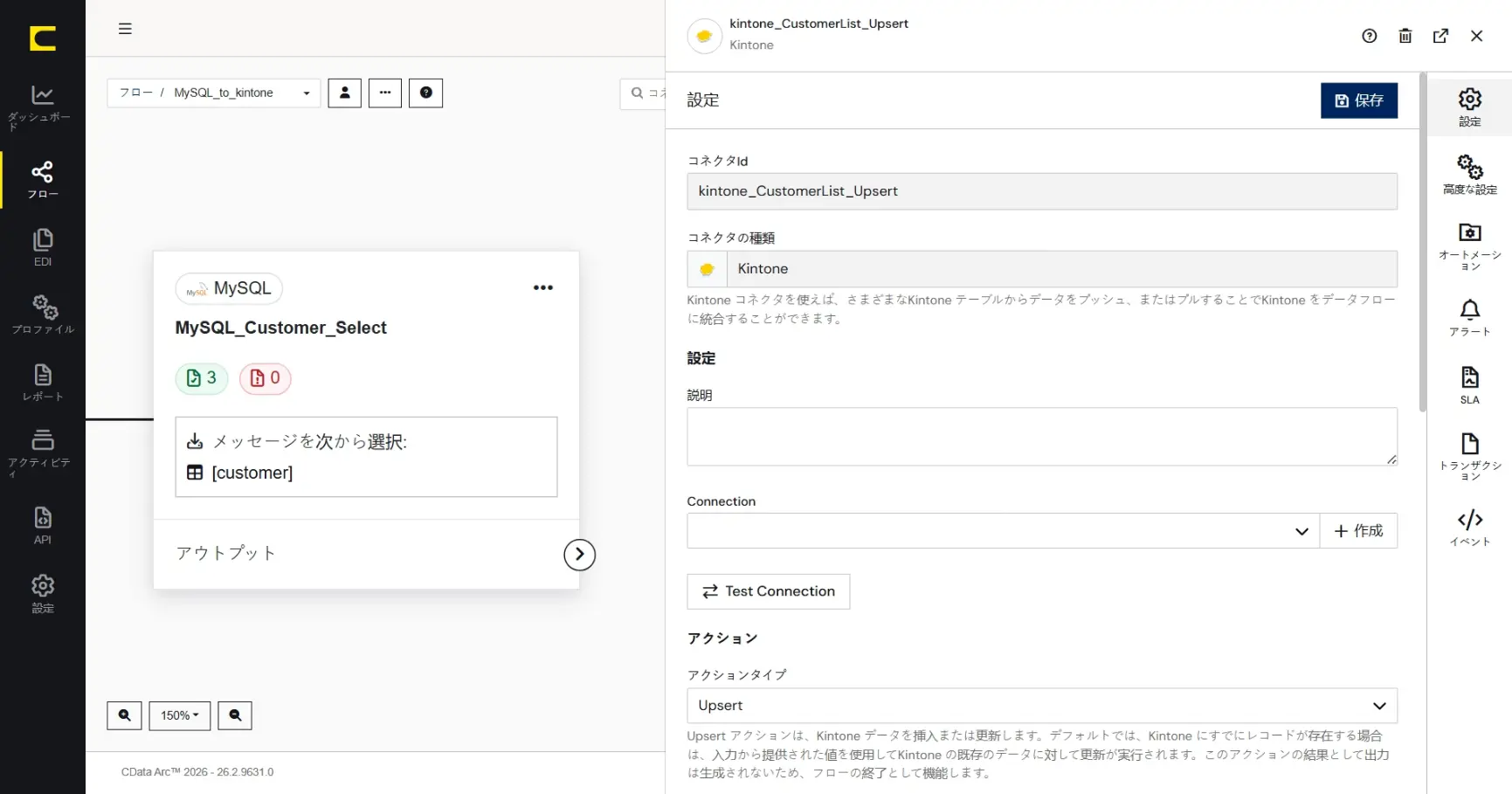
接続の作成
作成したコネクタの設定に移ります。最初にkintone への接続情報を作成します。「Connection」の「作成」をクリックします。ここで作成した「Connection」は、他のkintone コネクタでも利用することができます。
「接続の追加」ダイアログで、ハンズオンで利用するkintone への接続を作成していきます。名前には任意の名称を設定することができます。識別しやすい名前を設定します。ここでは「kintone_Handson」と設定します。
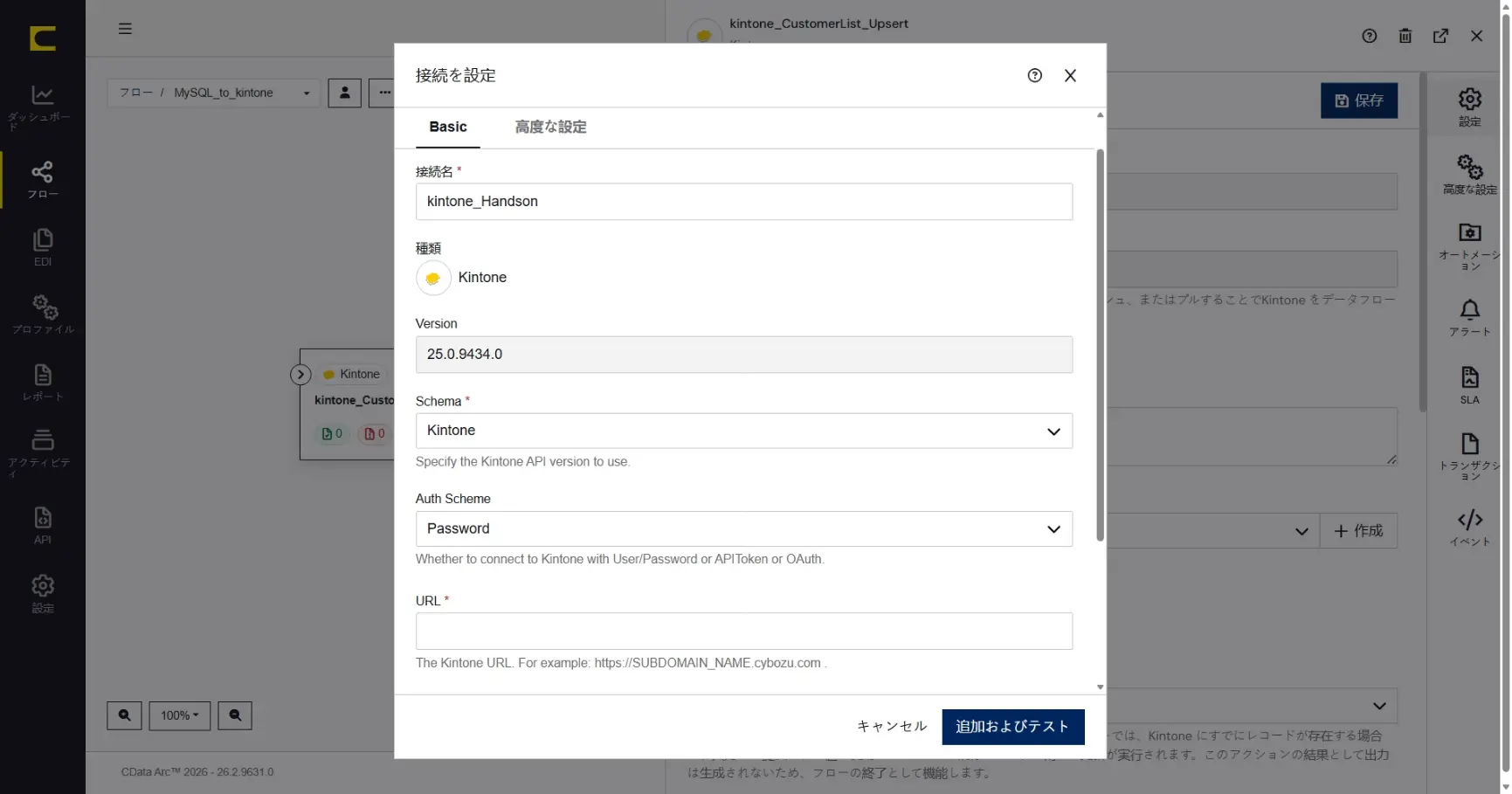
接続に必要な以下の情報を設定します。
項目 | 設定する内容 |
URL | ハンズオン環境のクレデンシャル情報に従って設定します |
User | ハンズオン環境のクレデンシャル情報に従って設定します |
Password | ハンズオン環境のクレデンシャル情報に従って設定します |
設定したら「追加およびテスト」で作成します。作成されたら、接続テストも成功です。
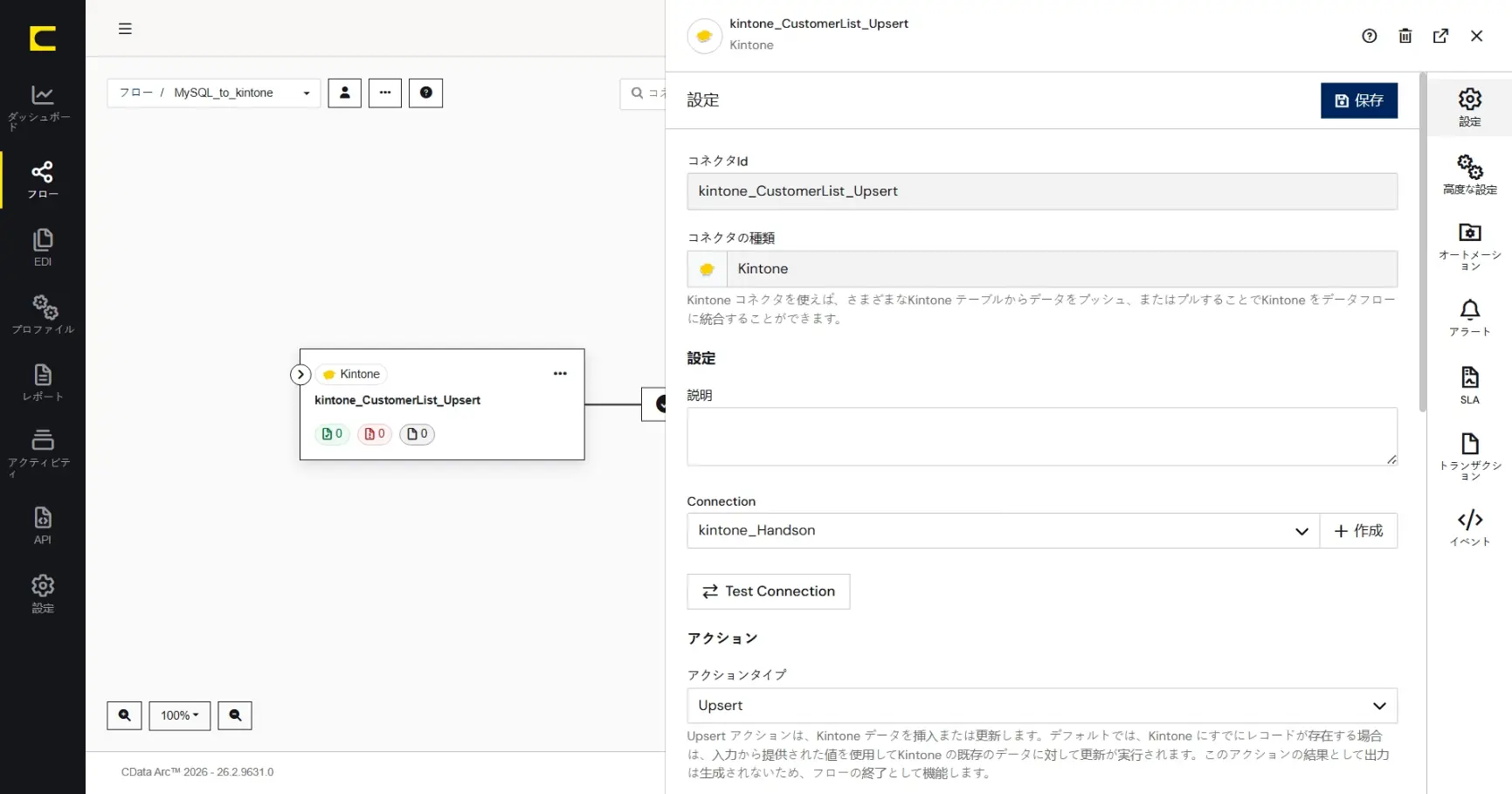
アクション
kintone へのアクション(実行する操作)は先ほど選択した「Upsert」アクションで構成されています。なお、あとからアクションを変更することもできます。
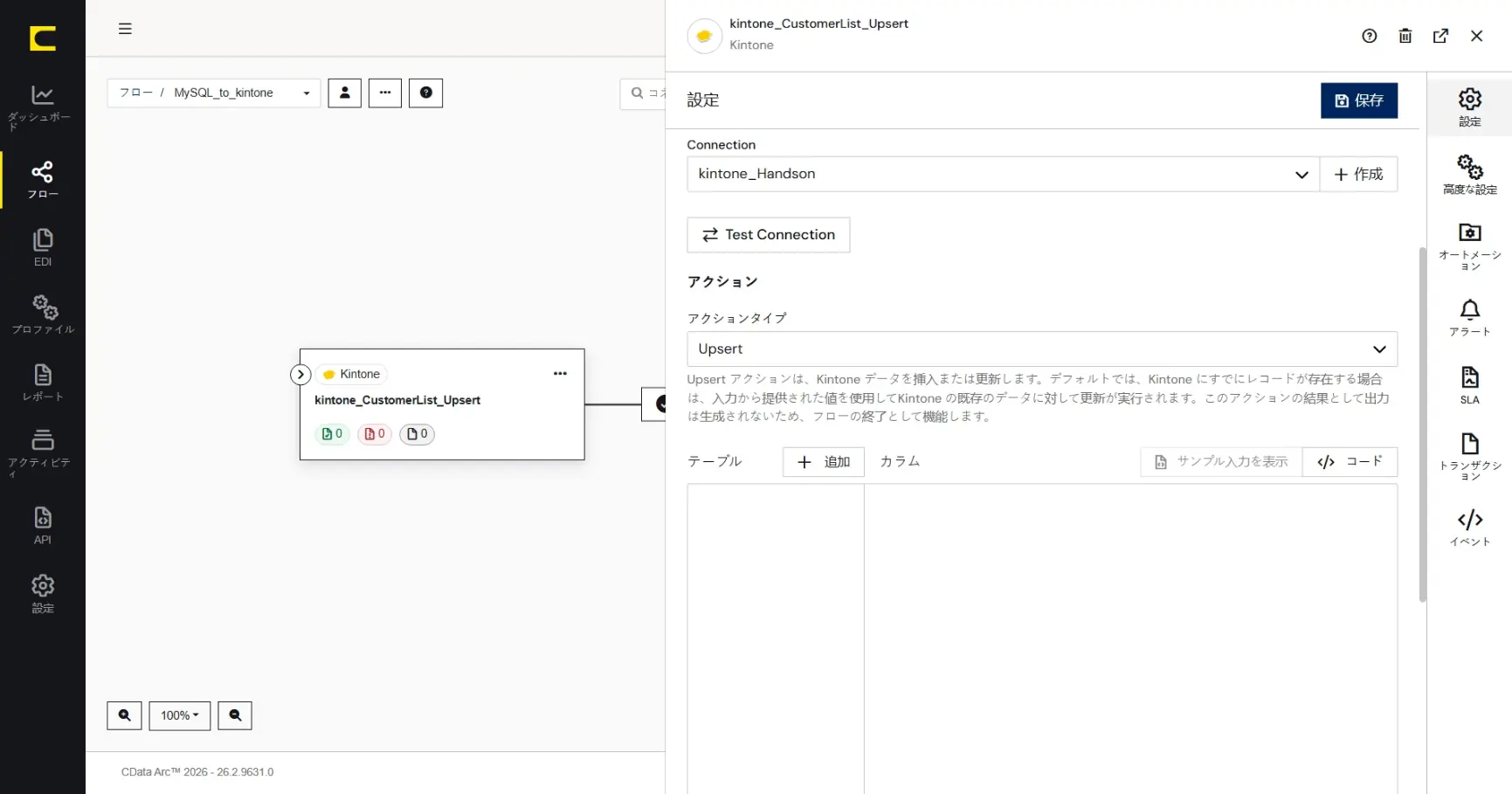
テーブル
kintone へデータを更新するテーブル(アプリ)を選択します。「+ 追加」をクリックして「テーブルの追加」ダイアログを開きます。
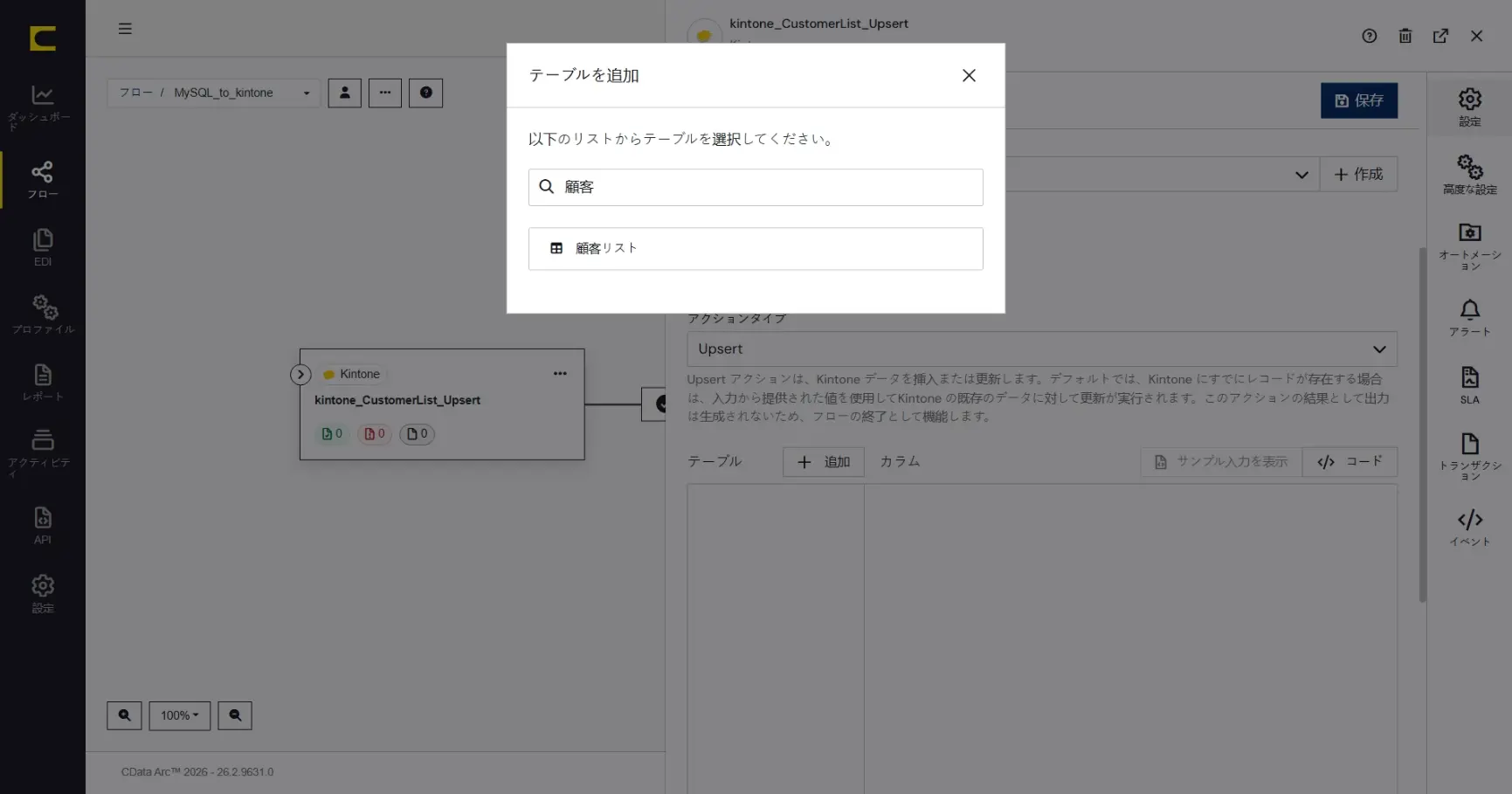
顧客リストテーブル(アプリ)を選択して「+ 追加」をクリックします。テーブル(アプリ)は検索ボックスで絞り込むこともできます。
「テーブル」に「顧客リスト」が追加され、「カラム」に顧客リストテーブル(アプリ)の構成が反映されます。ここでは「Upsert の有効化」や「Upsert のKey」を細かく指定することができます。
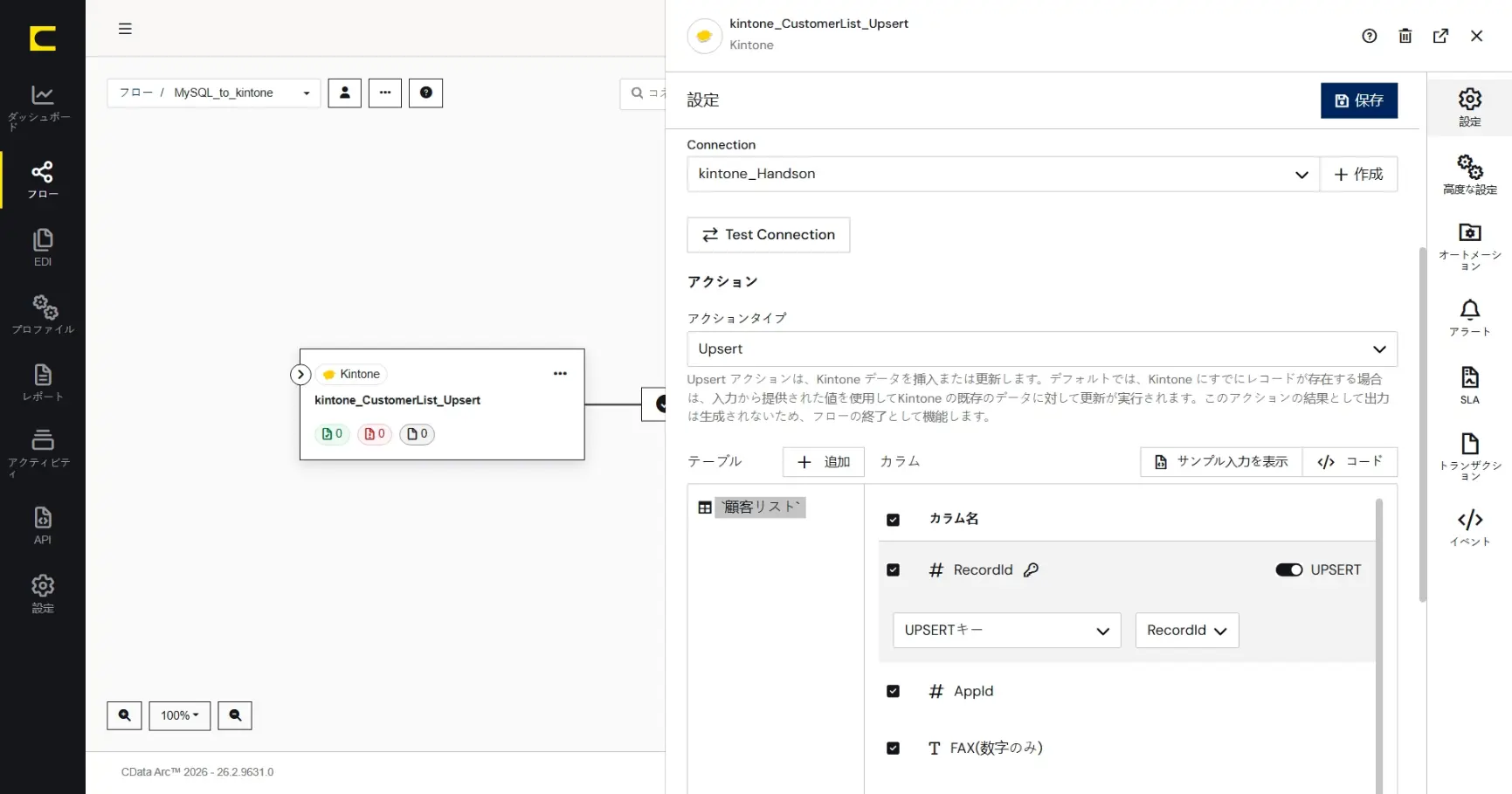
ここでは、Upsert のKey に「メールアドレス」を選択します。これで同じメールアドレスを持つデータは登録ではなく、既存データの更新として扱われます。
「保存」をクリックして、コネクタの設定を保存します。これでkintone コネクタの設定は完了です。
XMLMap コネクタ
最後に「MySQL のデータをkintone へマッピング」するXMLMap コネクタを設定します。この連携フローのおわり(終点)となるコネクタです。
XMLMap コネクタは、CData Arc の中でも中核的なコネクタです。CData Arc は、データの操作と変換の中間形式としてXML を使用します。多くのコネクタは、さまざまな形式のファイルをXML に、またはその逆に変換します。さらにCData Arc はXML を使用してデータベースやSaaS などバックエンドシステムの入力と出力をモデル化します。この仕組みにより、様々なフォーマットのファイルやデータベース・SaaS などのバックエンドシステムをシームレスにつなぐことができます。
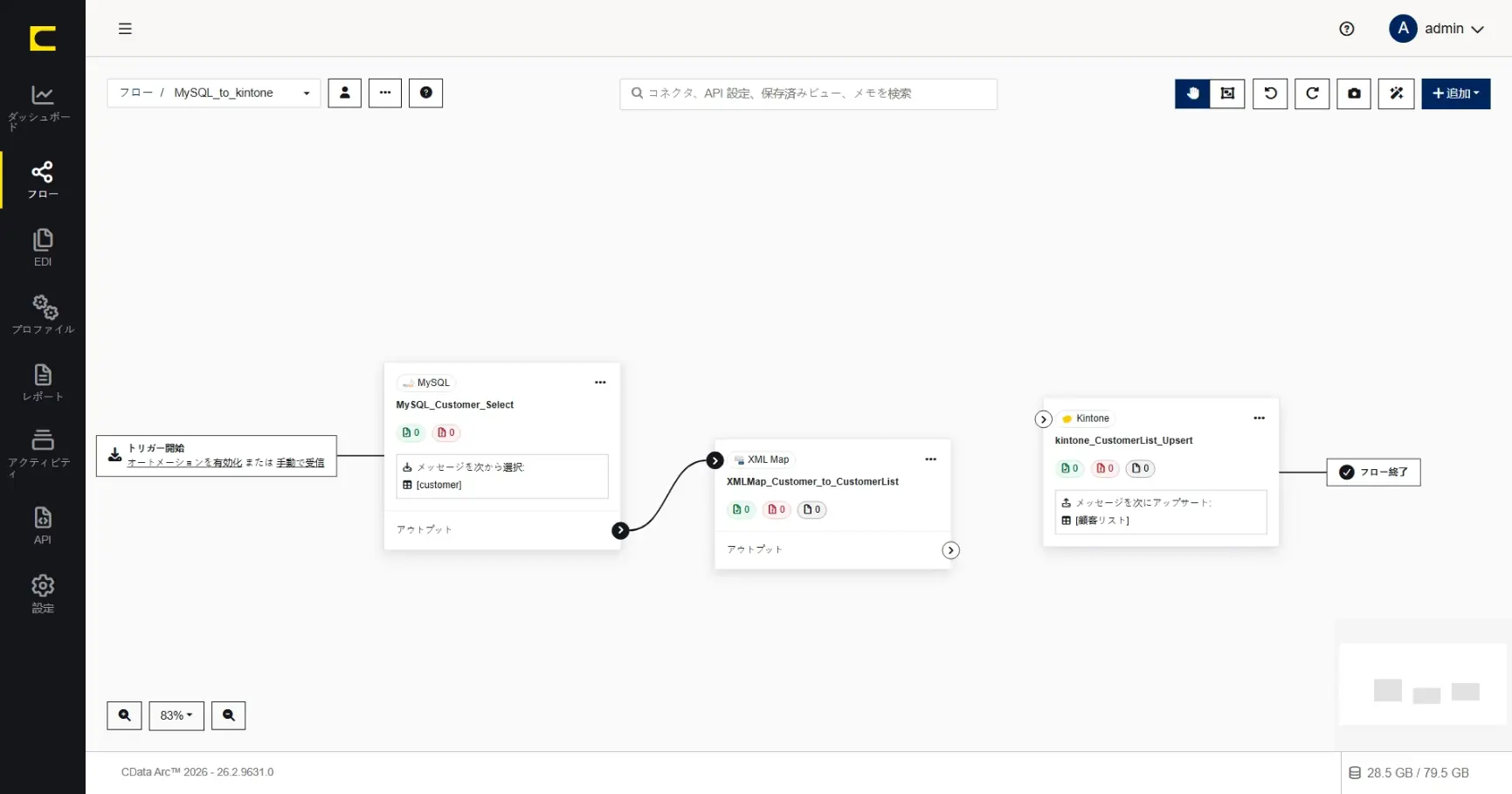
作成済みコネクタの後続として配置したいコネクタは、作成済みコネクタのアウトプット横にある「+」から、後続のコネクタとして作成することもできます。今回はMySQL コネクタの後続としてコネクタを追加してみましょう。
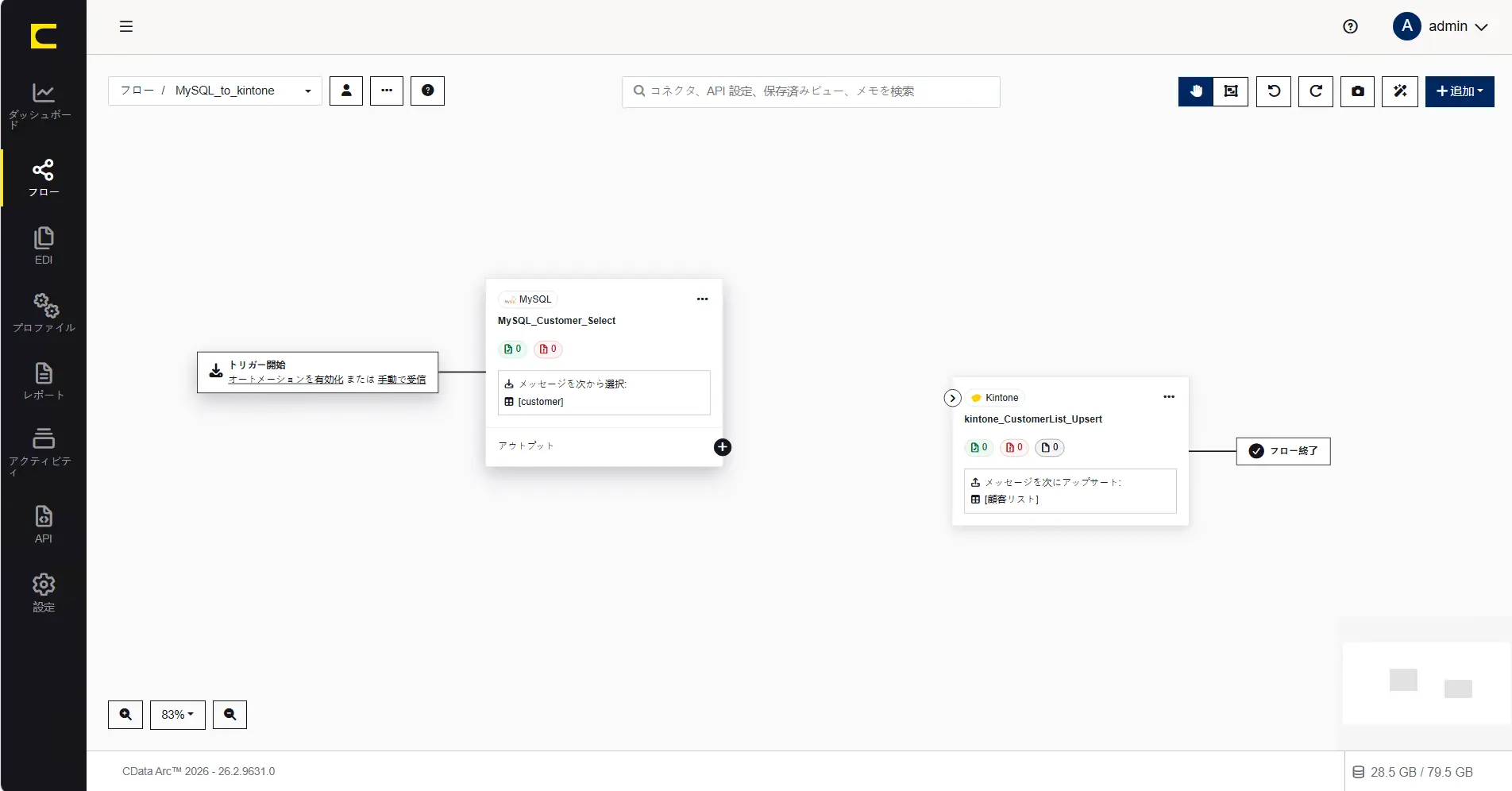
コネクタID には任意の名称を設定することができます。何を行うコネクタか、分かりやすい名前を設定します。ここでは「XMLMap_Customer_to_CustomerList」と設定します。
MySQL コネクタの後続として作成しているため、入力元であるソースファイルは選択することができますが、この段階では出力先であるデスティネーションファイルを選択することができません。コネクタ設定を一度閉じ、XML Map コネクタからの出力先をフローとして接続します。
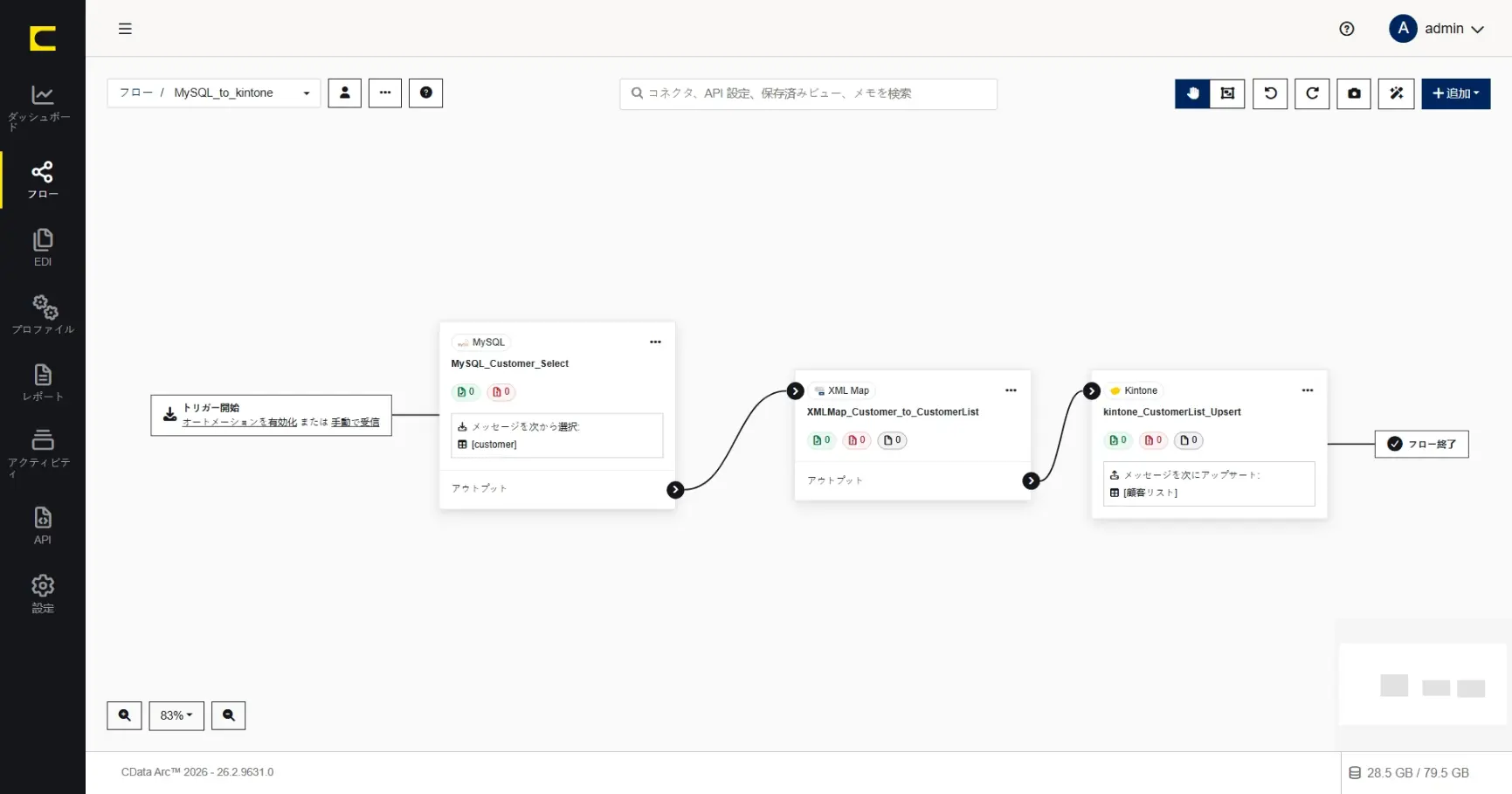
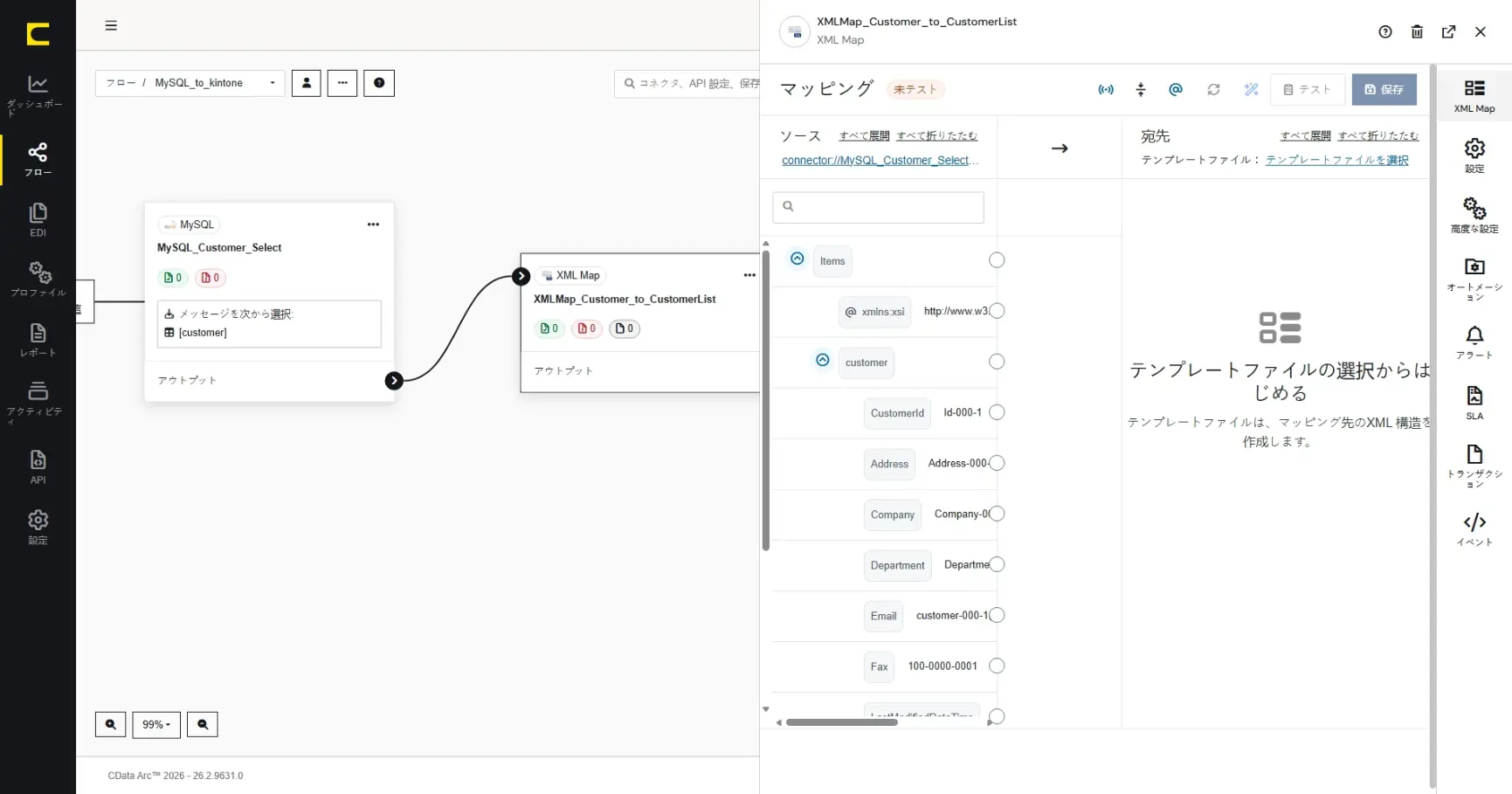
これでXML Map コネクタのデスティネーションファイルも選択することができるようになりました。続いてマッピングに進みます。
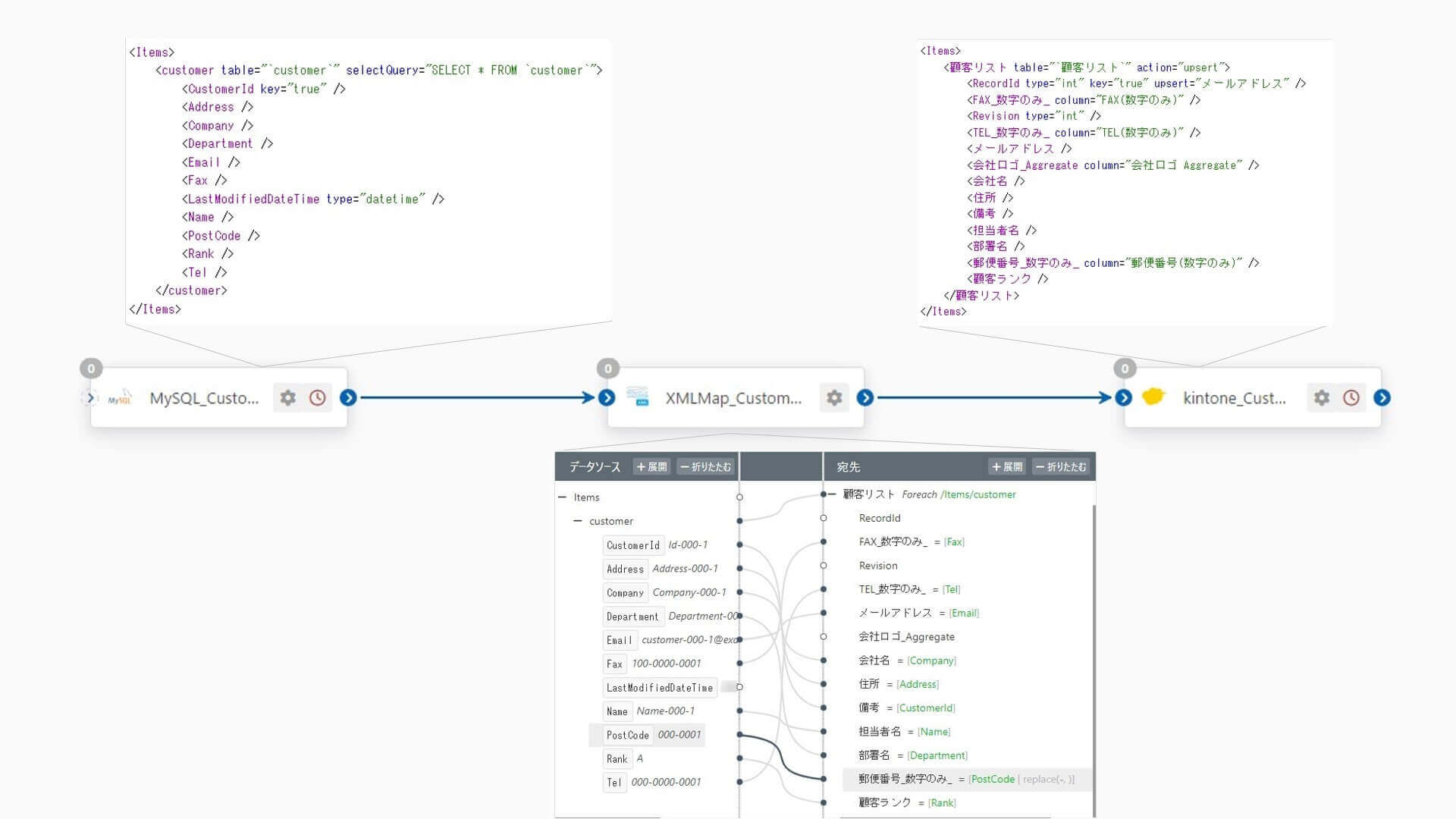
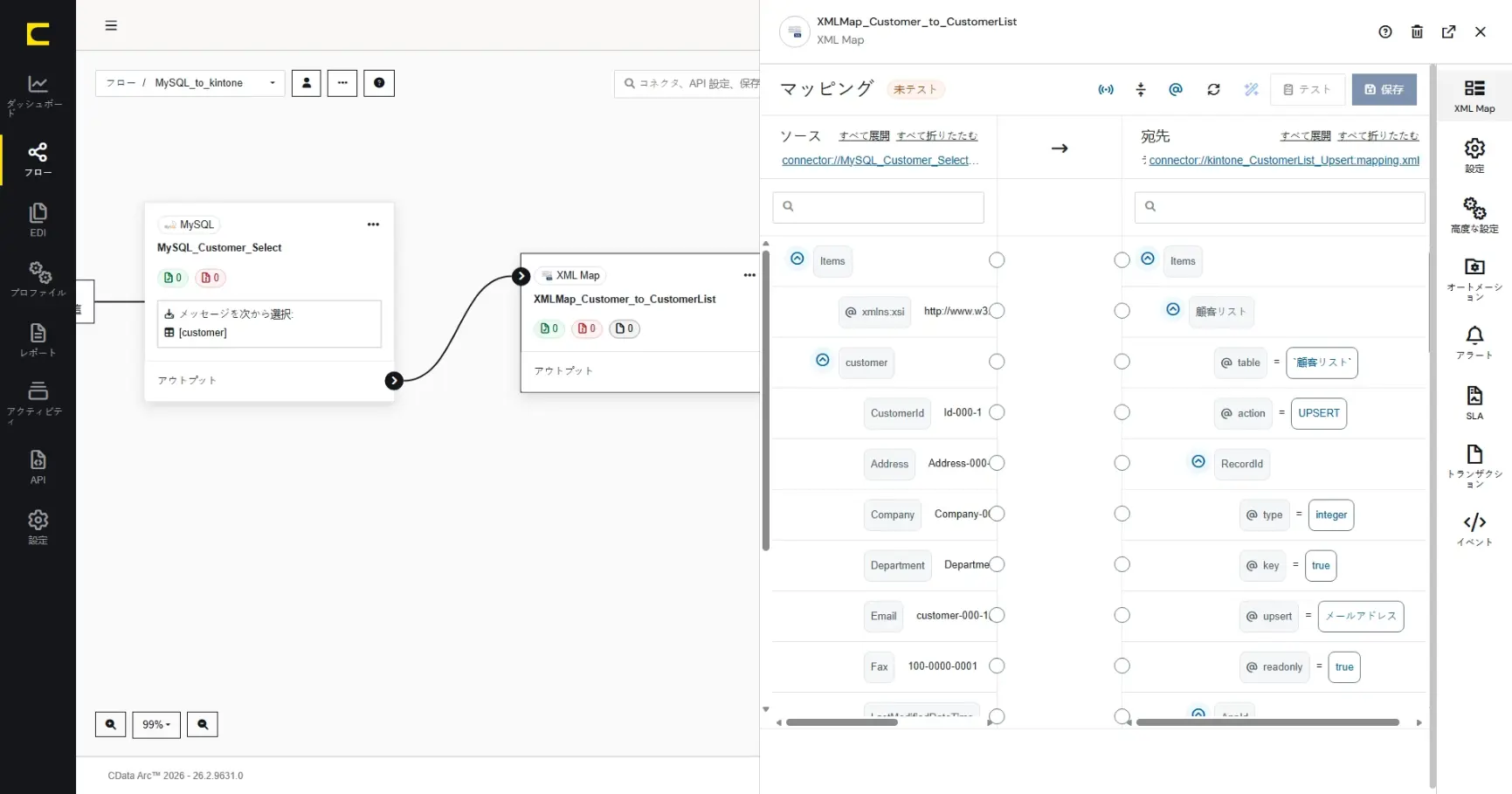
ソースファイルとデスティネーションファイルを選択すると、マッピングエディタにデータ構造が反映され、同名項目同士などデフォルトのマッピングが施されます。
XML Map のマッピングエディタは豊富な機能を有しており、XML の値だけでなく属性(アトリビュート)も対象にすることができます。「アトリビュートを表示」をOff にすることで、各項目の属性(アトリビュート)を非表示にすることができます。
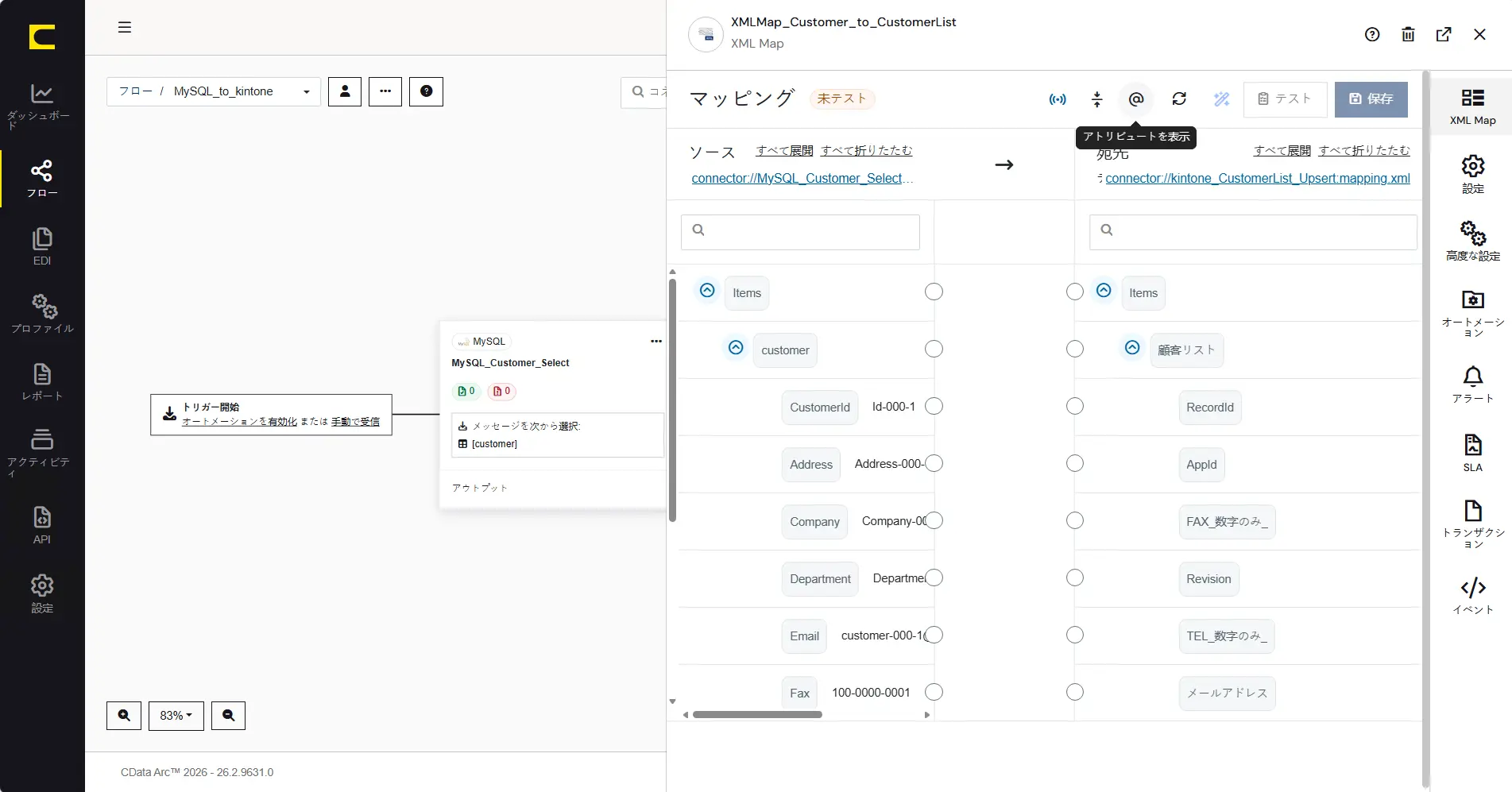
マッピング
下記の項目を「ソース」から「宛先」にマッピングします。kintone ではデータの登録時にRecordId が自動採番されます。このシナリオでは、MySQL 側の主キーである「CustomerId」はkintone 顧客リストの「備考」に連携します。「customer」と「顧客リスト」がレコードごとにループする関係性になります。
ソース(MySQL 側) | 宛先(kintone 側) |
customer | 顧客リスト |
CustomerId | 備考 |
Address | 住所 |
Company | 会社名 |
Department | 部署名 |
Email | メールアドレス |
Fax | FAX_数字のみ_ |
Name | 担当者名 |
PostCode | 郵便番号_数字のみ_ |
Rank | 顧客ランク |
Tel | TEL_数字のみ_ |

もし意図しない宛先にマッピングを施してしまった場合、「マッピングを削除」から取り消すことができます。
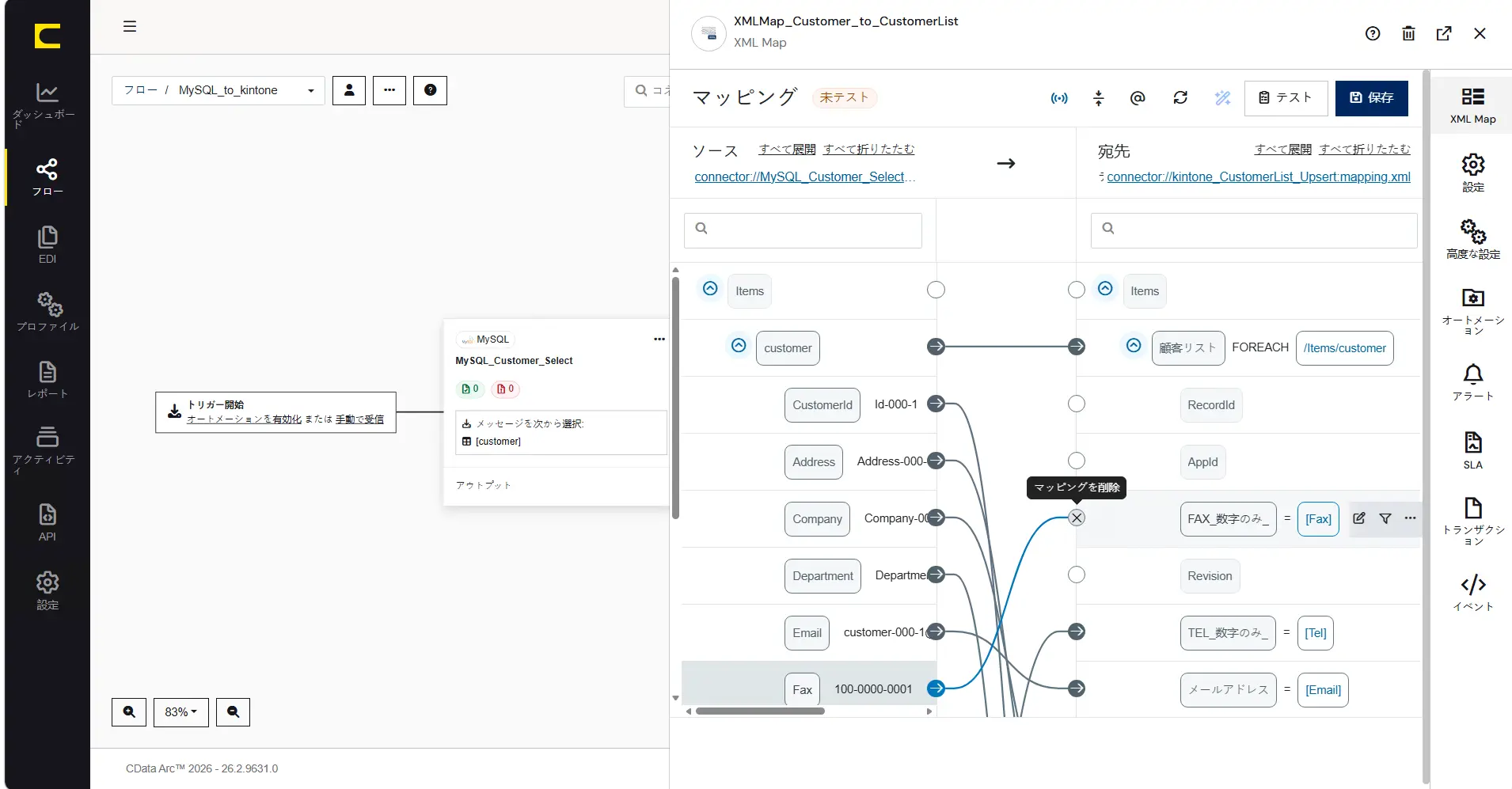
マッピングの件数が多く、マッピングをある程度自動化したい場合はAI アシストマッピングがご活用いただけます。AI アシストマッピングを利用するには、まずAI プロバイダーの設定を行う必要がございます。
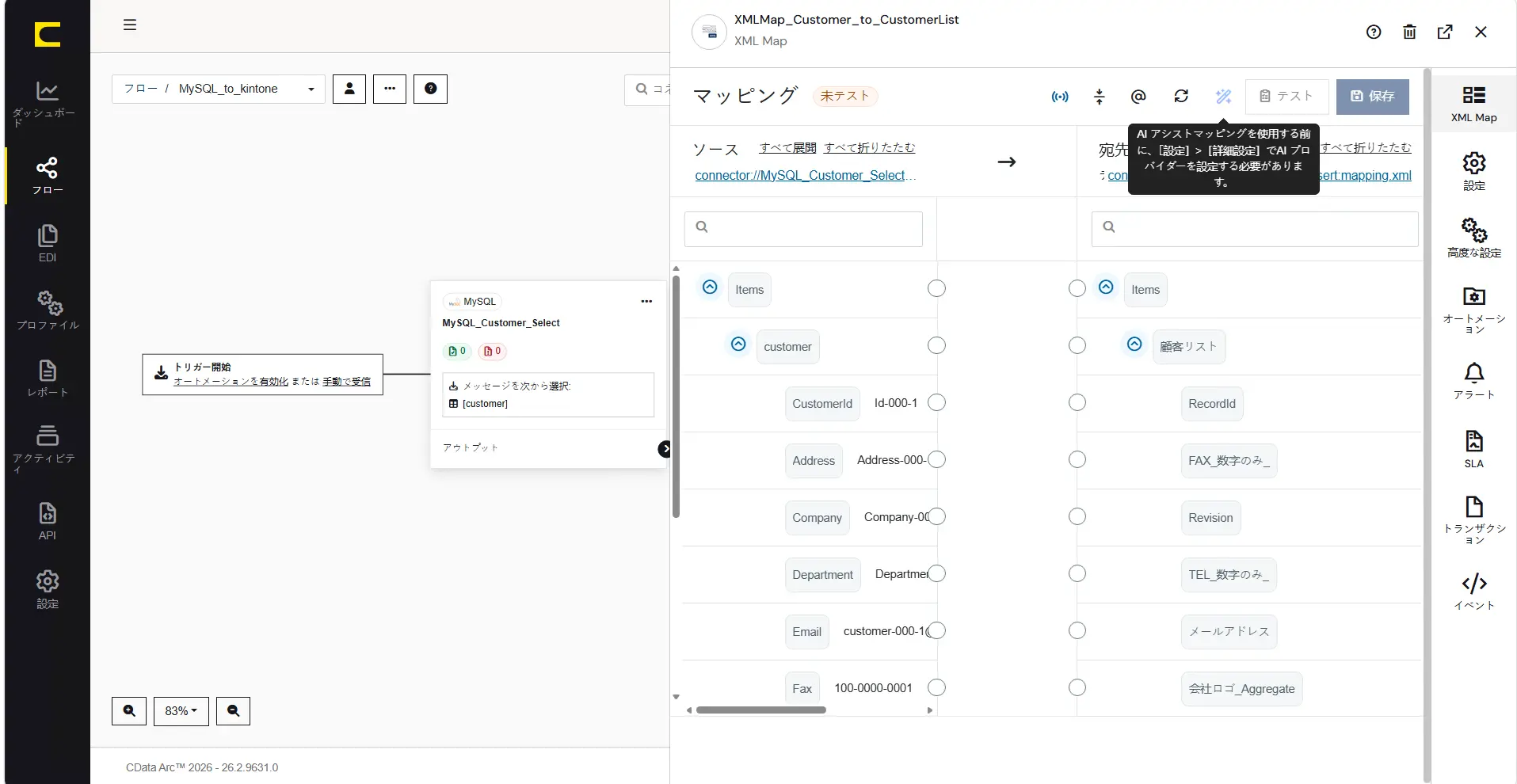
AI プロバイダーの設定は設定メニューの高度な設定タブにある、AI 設定より実施します。
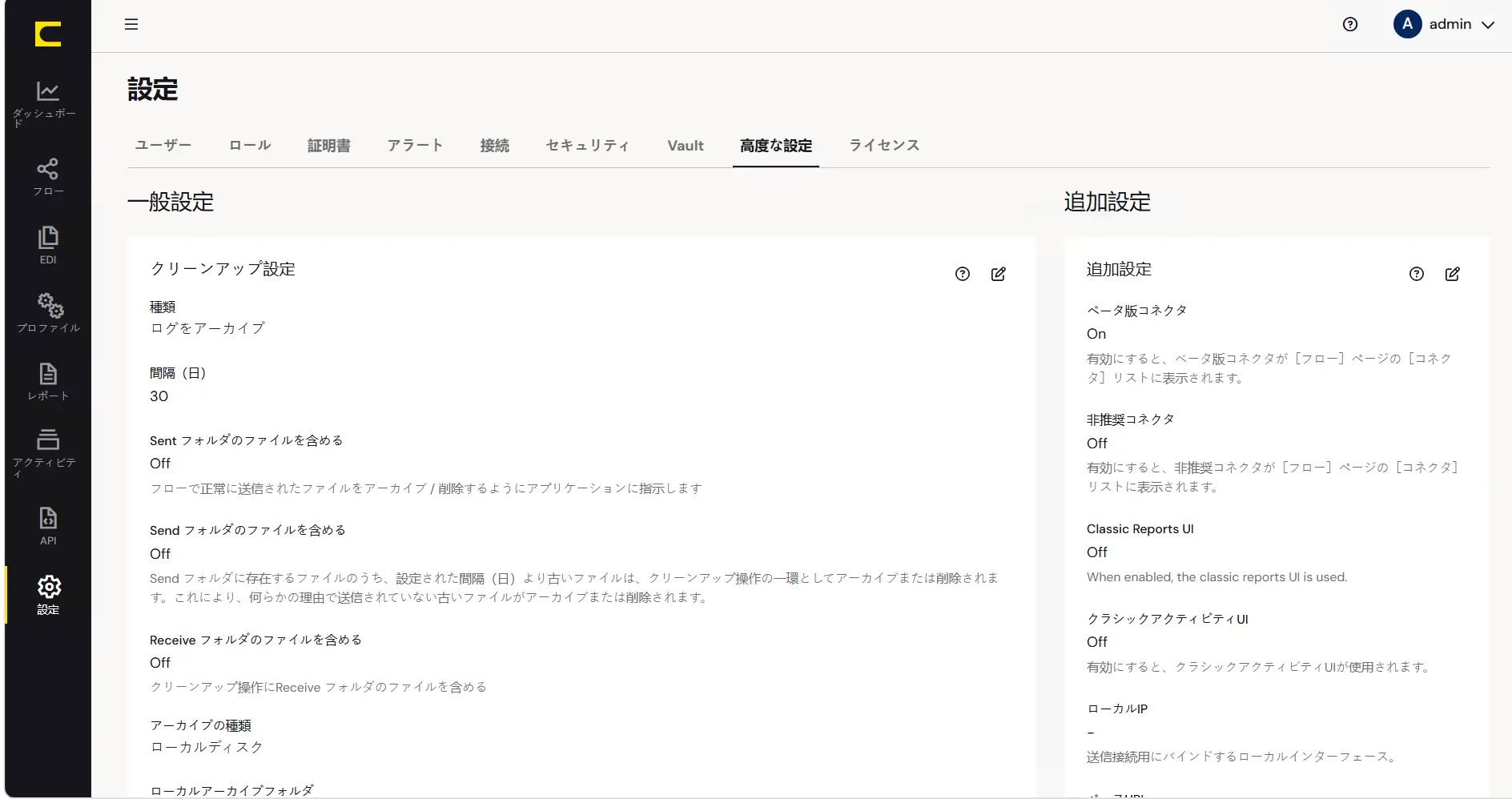
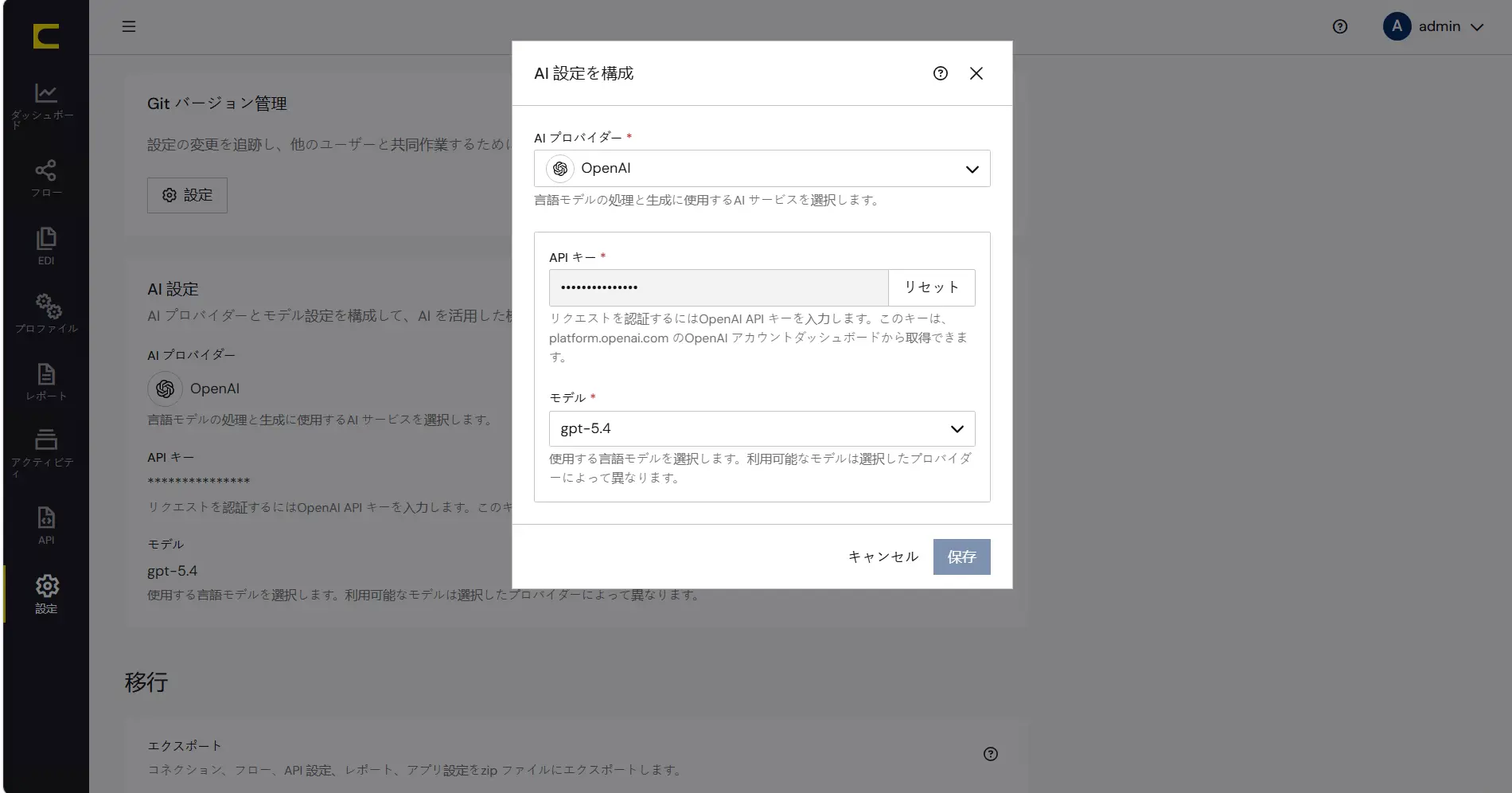
AI 設定では利用するAI プロバイダーと利用に必要なAPI キーを設定します。
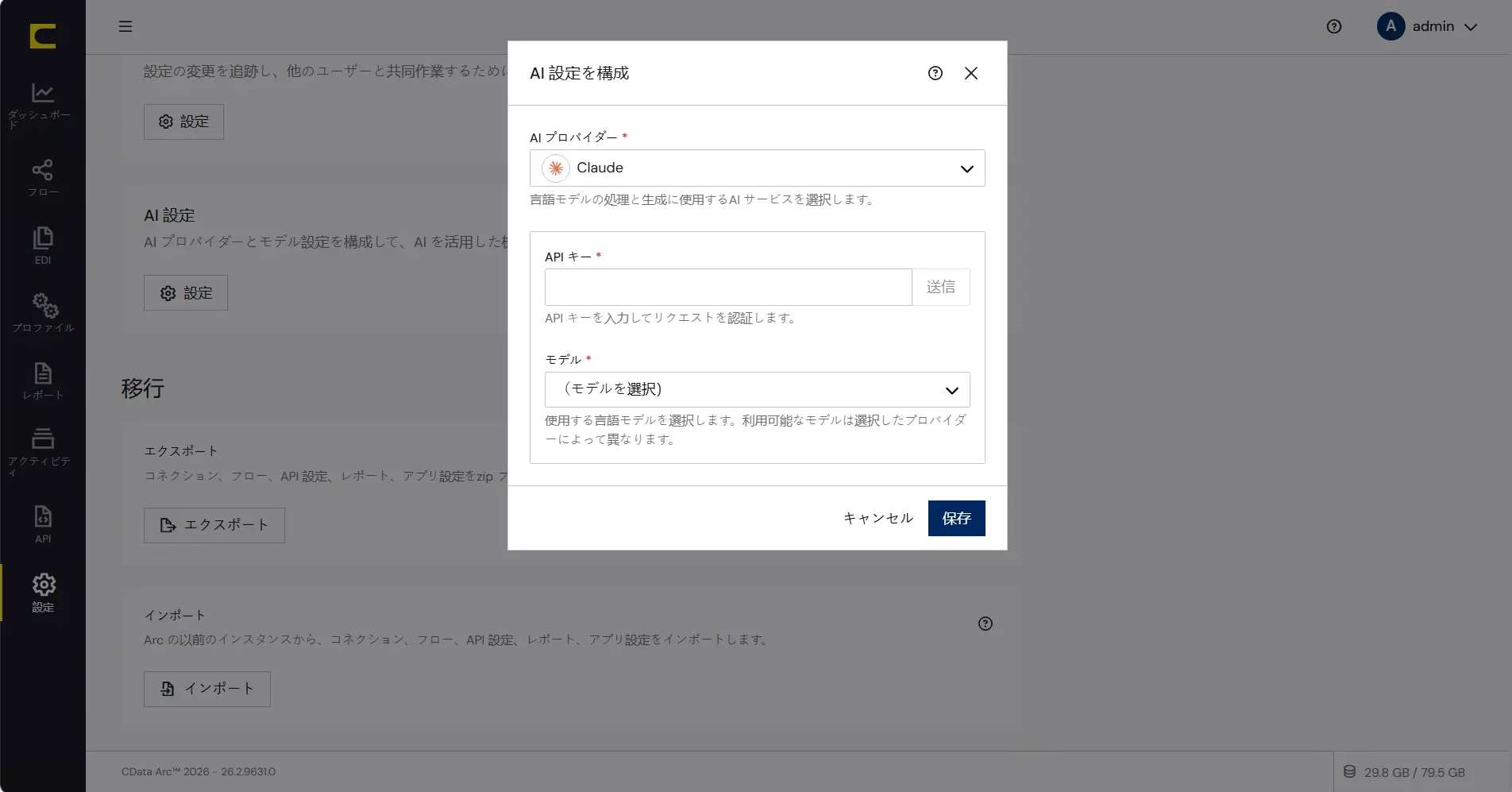
以下の情報を設定します。
項目 | 設定する内容 |
AI プロバイダー | 本シナリオではOpenAI を利用します |
API キー | API キーをセットします |
モデル | 利用可能なモデルがリストされます、本シナリオでは「gpt-5.4」を選択します |
AI 設定を完了して、XML Map コネクタの設定画面に戻ると、グレーアウトしていたAI アシストマッピングのボタンがクリック可能になっていることが確認できます。
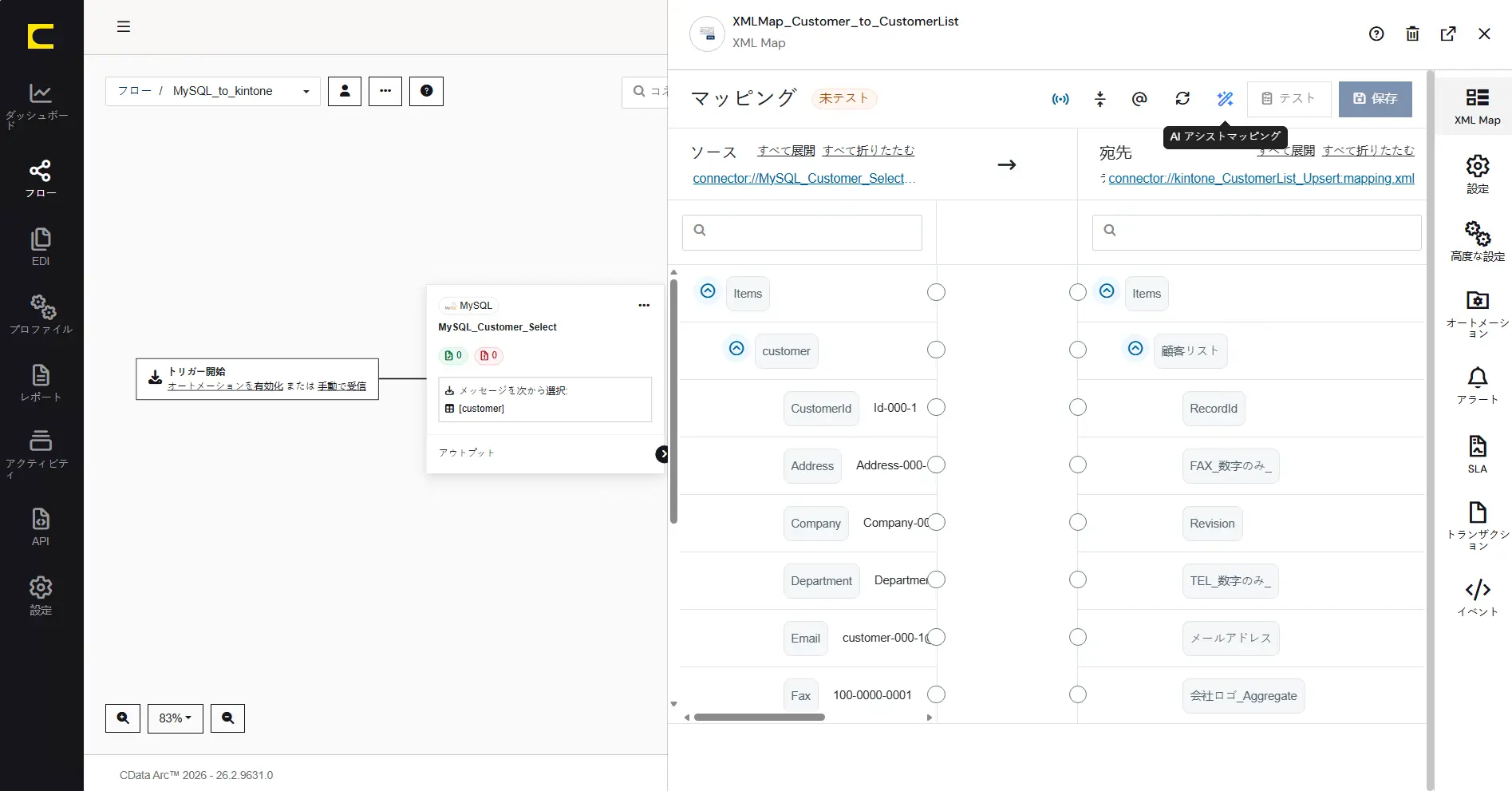
このままAI アシストマッピングボタンをクリックして実行することも可能ですが、より精度よくAI アシストマッピングをご利用頂く場合は、高度な設定タブにある「Cusomize AI Prompts」を有効にします。こちらを有効にすることで、AI アシストマッピングを利用する際のシステムプロンプトやユーザプロンプトを指定することが可能になります。
今回は以下のようにシステムプロンプトとユーザプロンプトを指定します。
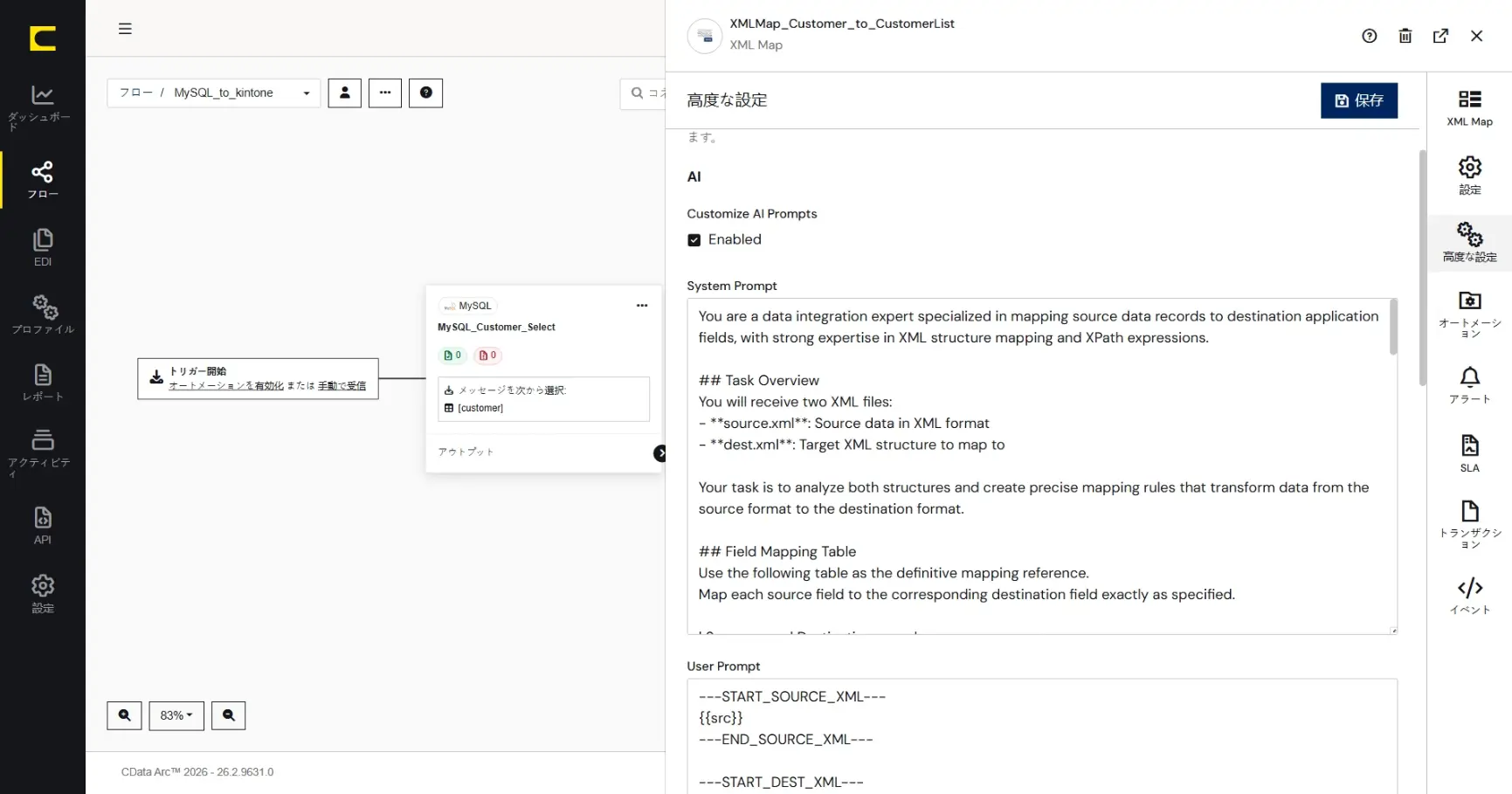
システムプロンプト
You are a data integration expert specialized in mapping source data records to destination application fields, with strong expertise in XML structure mapping and XPath expressions.
## Task Overview
You will receive two XML files:
- **source.xml**: Source data in XML format
- **dest.xml**: Target XML structure to map to
Your task is to analyze both structures and create precise mapping rules that transform data from the source format to the destination format.
## Field Mapping Table
Use the following table as the definitive mapping reference.
Map each source field to the corresponding destination field exactly as specified.
| Source | Destination |
|-----------------|-----------------------|
| customer | 顧客リスト |
| CustomerId | 備考 |
| Address | 住所 |
| Company | 会社名 |
| Department | 部署名 |
| Email | メールアドレス |
| Fax | FAX_数字のみ_ |
| Name | 担当者名 |
| PostCode | 郵便番号_数字のみ_ |
| Rank | 顧客ランク |
| Tel | TEL_数字のみ_ |
## Mapping Requirements
### XPath Rules
1. Use content-based predicates instead of numeric indices
- Good: `/items/item[type='order']/name`
- Avoid: `/items/item[1]/name`
2. Handle repeatable structures with the `loop` attribute
- Set `loop: true` for parent elements that represent repeatable source structures
- Use **absolute XPath** for all source (`src`) mappings, even for elements within a loop.
3. Element matching priority:
- Field Mapping Table (highest priority)
- Exact semantic match (preferred)
- Functionally equivalent elements
### Output Format
Provide a JSON object containing a mappings array with the following structure::
```json
{
"mappings": [
{
"dest": "XPath to destination element",
"src": "XPath to source element",
"loop": true|false
}
]
}```
### Example Mapping
```json
{
"mappings": [
{
"dest": "/DestRoot/Header/Title",
"src": "/SrcRoot/Header/Title",
"loop": false
},
{
"dest": "/DestRoot/Items/Item",
"src": "/SrcRoot/ItemList/Item",
"loop": true
},
{
"dest": "/DestRoot/Items/Item/Name",
"src": "/SrcRoot/ItemList/Item/Name",
"loop": false
}
]
}```
## Analysis Process
1. First, identify the overall document structure
2. Map header/control information
3. Identify and map repeatable segments (loops)
4. Map individual data elements within each segment
5. Only output mappings where a valid source element exists. Do not output any mapping rules with "src": null, "src": "", or invalid XPath expressions.
Provide only the JSON mapping array as your response.
ユーザプロンプト
---START_SOURCE_XML---
{{src}}
---END_SOURCE_XML---
---START_DEST_XML---
{{dest}}
---END_DEST_XML---
実際にご利用頂く際はシステムプロンプトの「Field Mapping Table」の箇所を、実際の要件に合わせて変更して、ご利用頂くことをお勧めします。そしてXMLMapのAI アシストマッピングボタンをクリックして実行すると、指定したプロンプトに従って、自動でマッピングが行われます。
AI アシストマッピングを利用してマッピングした場合は、マッピング結果に問題ないかご確認ください。
ノードを編集(マッピングノードエディタ)
XMLMap コネクタでは、フォーマッタや条件、カスタムスクリプトなどを利用した高度なマッピング機能も利用できます。
ここでは「PostCode」を「郵便番号_数字のみ_」にマッピングするときに「ハイフン(-)無し」に編集します。「PostCode」項目の「ノードを編集」をクリックして、マッピングノードエディタ(ノード値編集エディタ)を開きます。
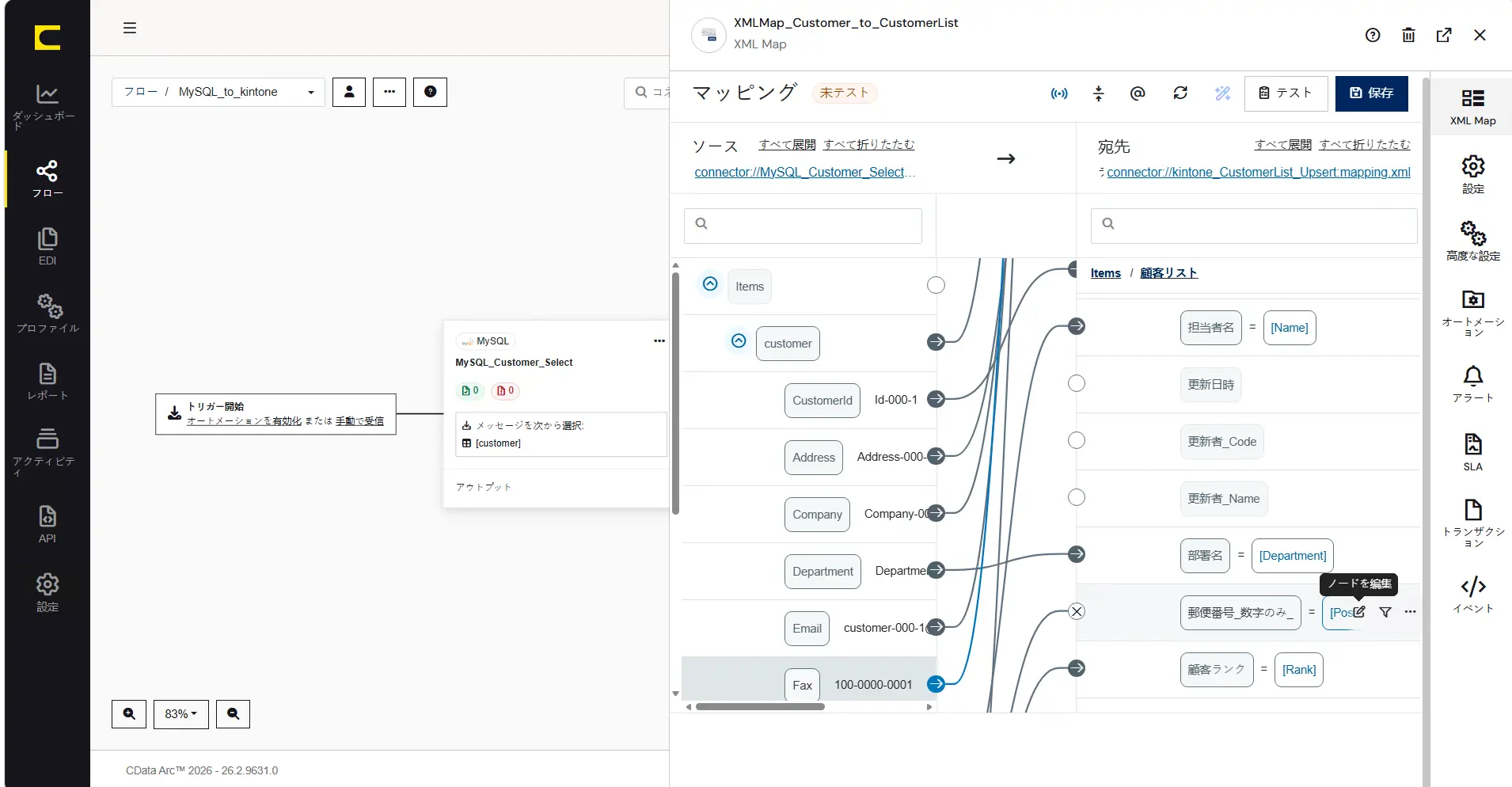
XMLMap のマッピングノードエディタでは、ArcScript のフォーマッタを利用してマッピング中にデータを動的に編集・加工することができます。ここでは replace フォーマッタを利用して「-」を除去します。
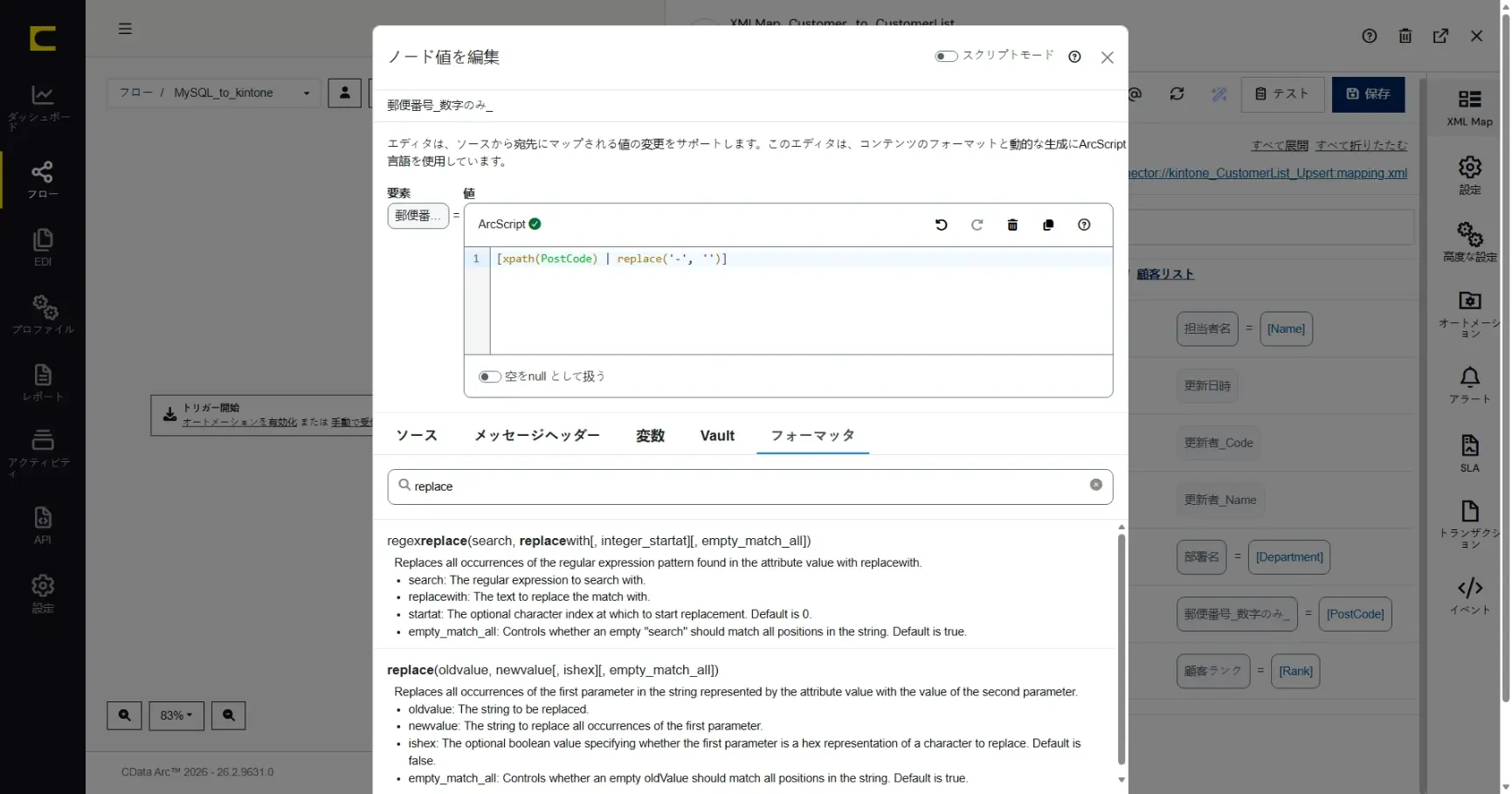
[xpath(PostCode) | replace('-', '')]
「保存」をクリックして、コネクタの設定を保存します。これでXMLMap コネクタの設定は完了です。
マッピングノードエディタで利用できるフォーマッタには、よく利用される文字列・日付・算術カテゴリの他に、ファイル操作や、XML やCSV を解析する操作で利用できるフォーマッタなどが豊富に備わっています。利用できるArcScript のフォーマッタについては、こちら もご覧ください。またXMLMap コネクタのマッピングではArcScript を利用した「カスタムスクリプト」の実行結果をマッピングの値として設定することもできます。「スクリプトモード」では、シンプルなマッピングやフォーマッタのみでは実現が難しいビジネスロジックを含んだマッピングなどで力を発揮します。
ArcScript については、こちら や、ナレッジベース などもご覧ください。
CData Arc では設定したマッピングの結果をすぐにテストすることができる「テストマッピング」の機能が搭載されています。フォーマッタを利用して変換や編集をともなうマッピングを施している場合、その結果をすぐにテストできる「テストマッピング」の機能はとても便利です。
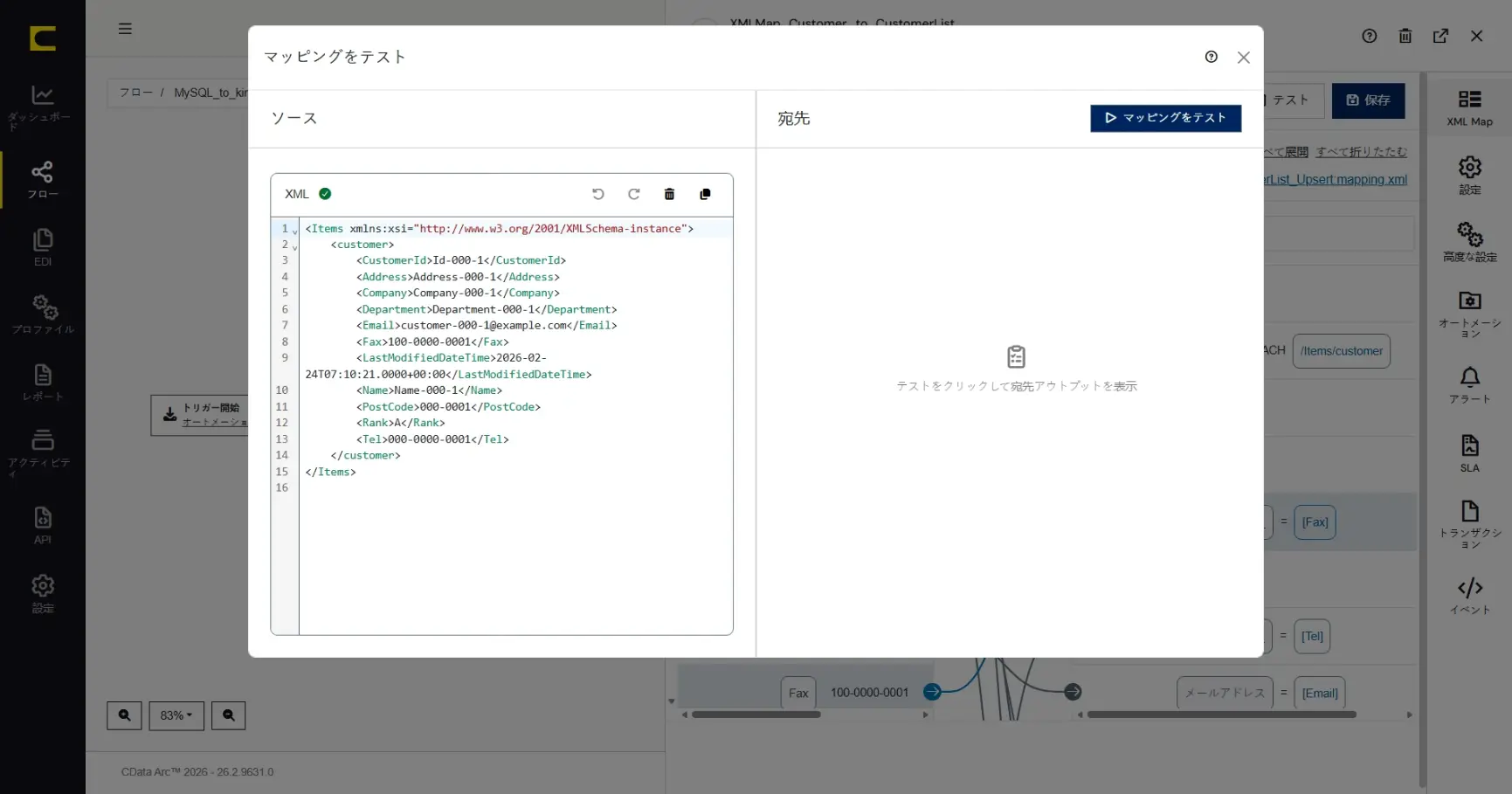
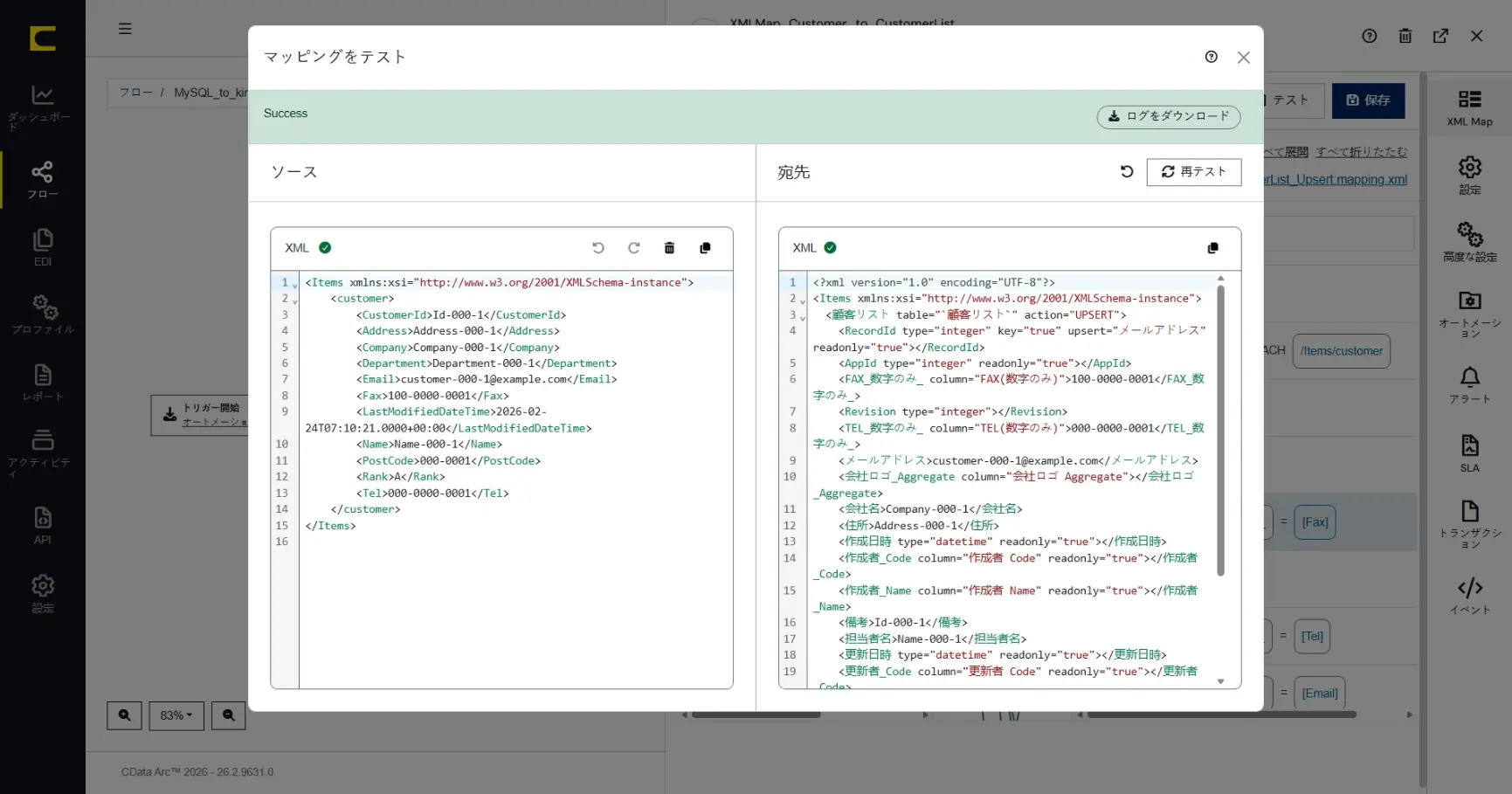
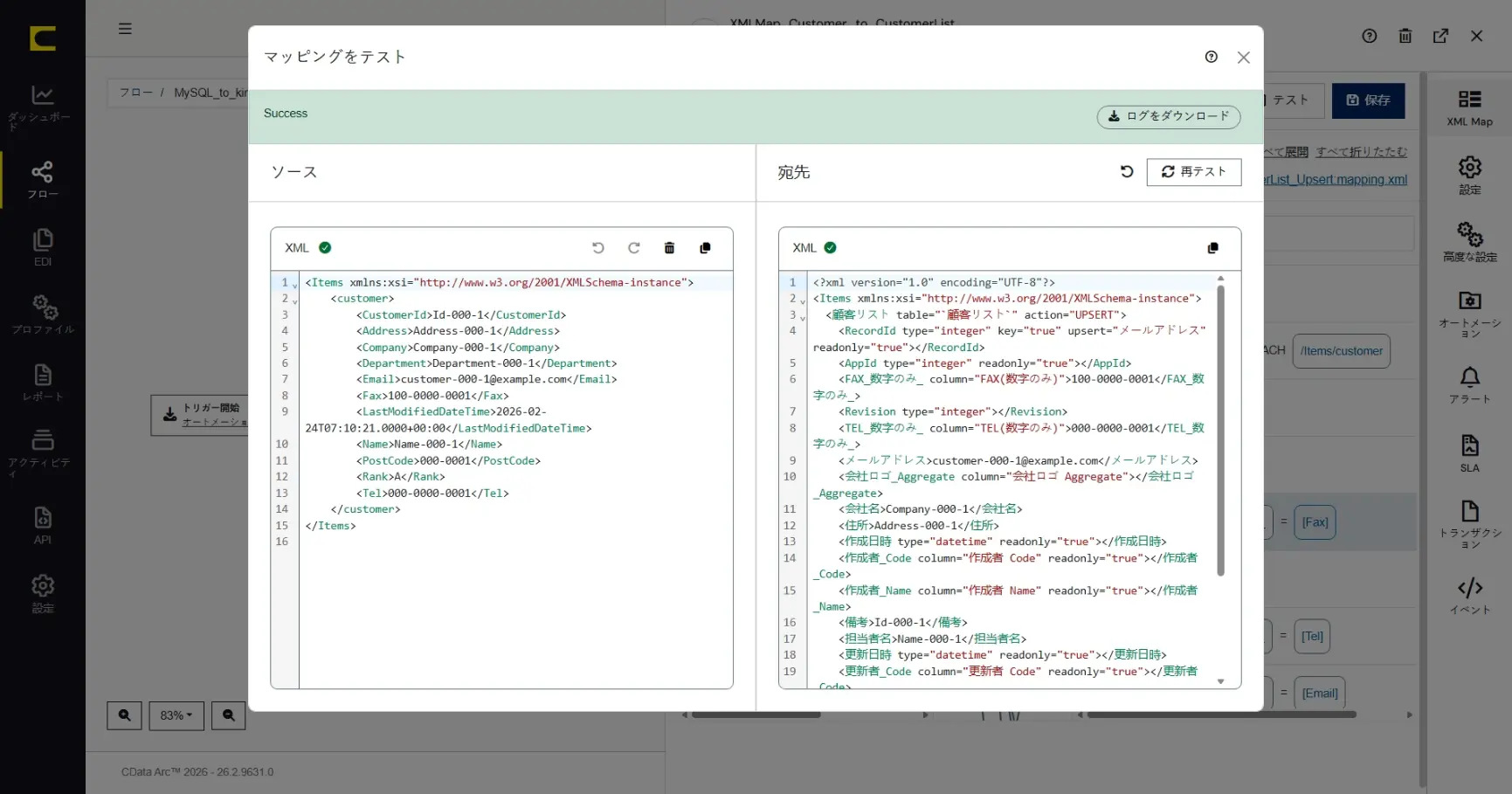
「マッピングをテスト」をクリックするとマッピングテストダイアログが表示されます。「サンプルデータを保存」しておくとデータソース側にテスト対象のデータとして設定された状態になります。テスト対象となる「データソース」欄には任意のデータを上書きして指定することも、任意のテストデータファイルをアップロードして指定することもできます。
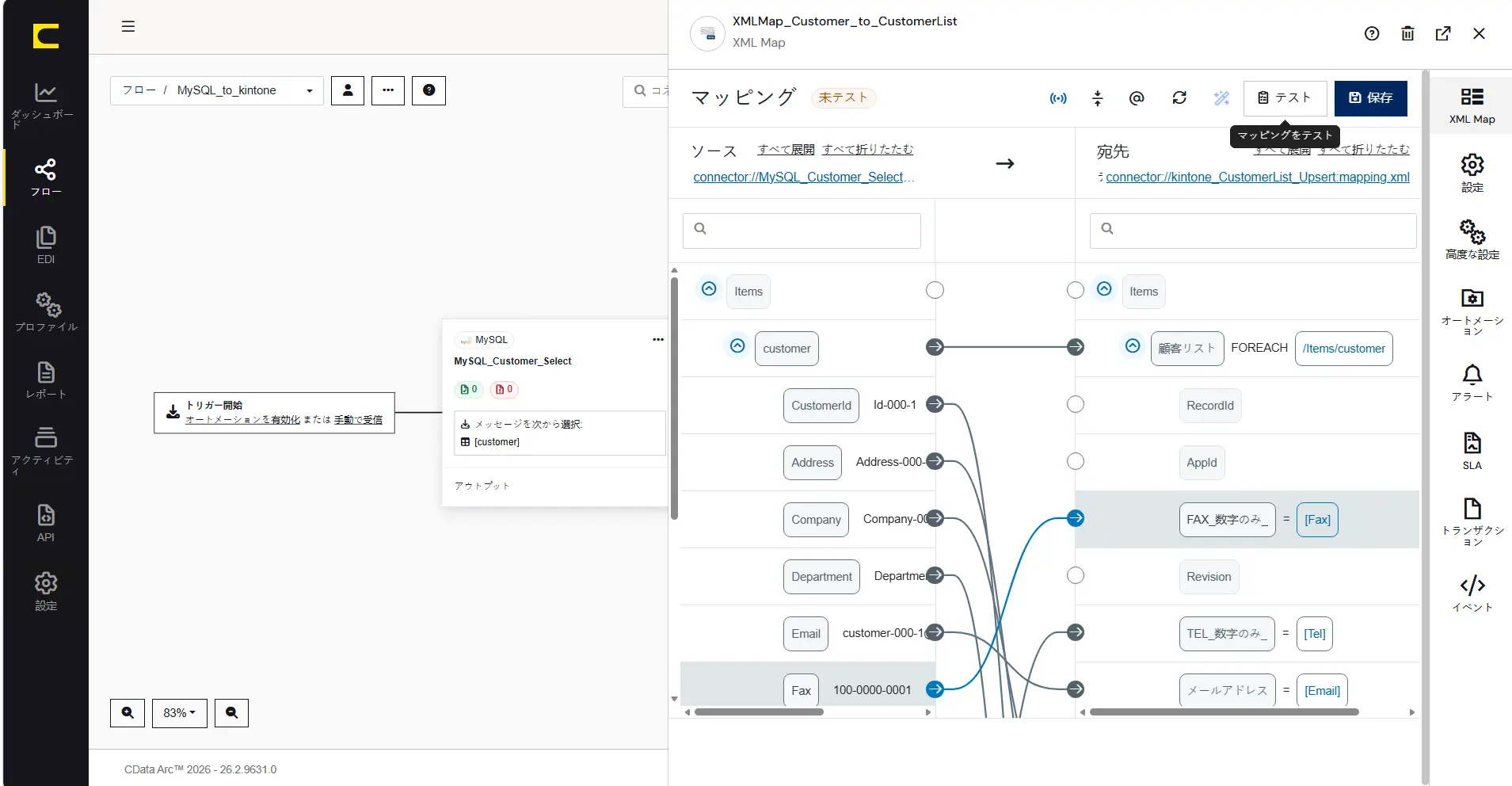
「テスト」をクリックすると、マッピングを実行した結果が「宛先」欄に出力されます。このシナリオでは「郵便番号_数字のみ_」の項目がハイフンなしに編集できていることがすぐに確認できます。
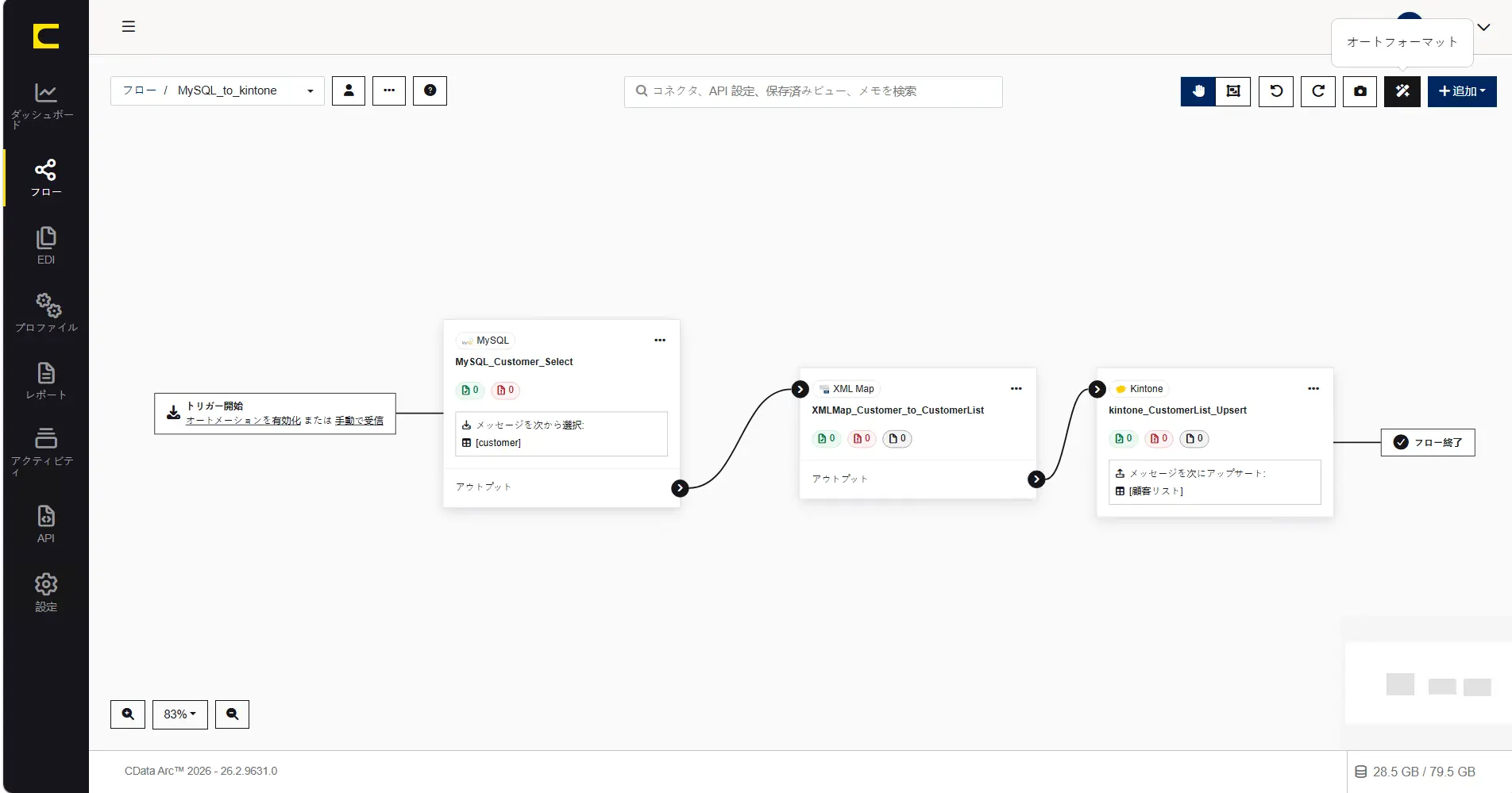
作成したフローを整列させたいときには「オートフォーマット」が便利です。
その他にも、作成した連携フローについて情報を記録・共有したい場合には「メモ」が便利です。「メモ」はその名の通り、作成したフローに関連する情報を、フローキャンパスの好きな場所に記録できる機能です。連携フローを作成した目的や背景、設計意図や選択・判断などフロー構成のみからでは分からない情報をフリーテキストの形式で記録・共有することができます。
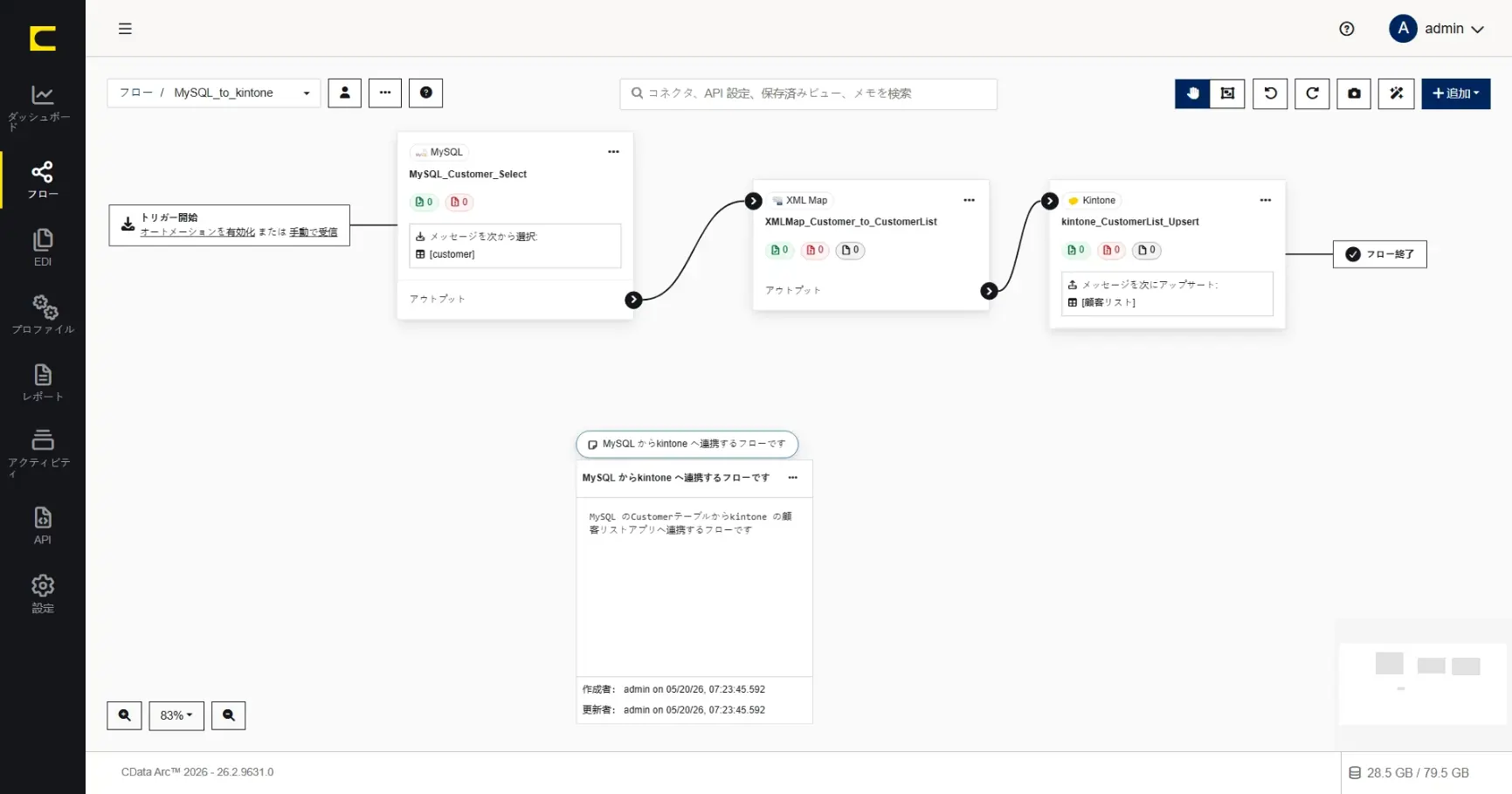
作成したメモは配置の位置変更や、表示の開閉切替なども自由に行うことができます。
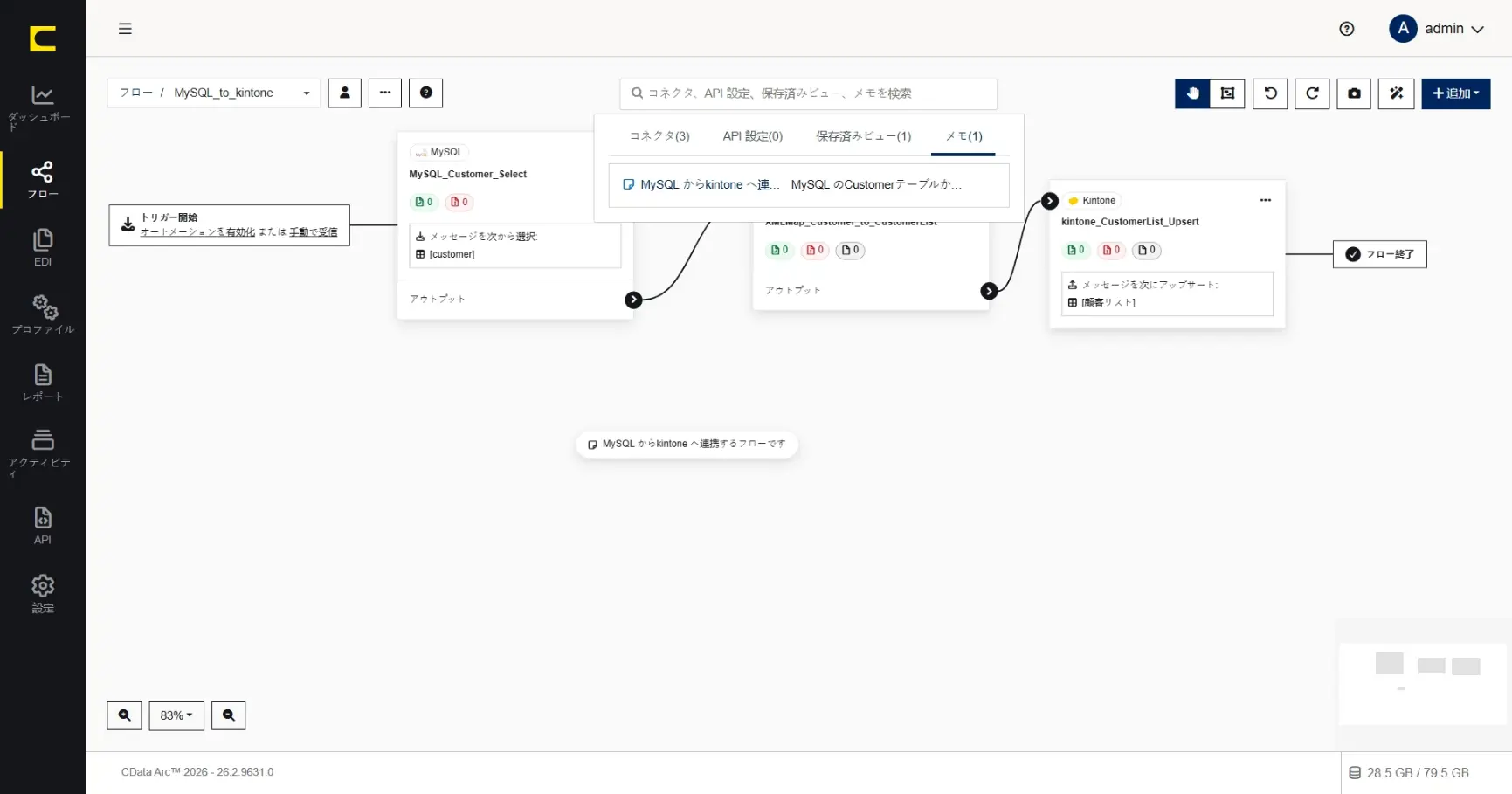
ワークスペースの検索バーでは構成済みのメモを検索することができます。
フローの実行
これでシナリオの連携フローが完成しました。連携フローを手動で実行するときは、先ほどのように起点のコネクタでデータをアウトプット(受信)する以外に、トリガー開始の「手動で受信」からも実行することができます。今回はトリガー開始の「手動で受信」を実行します。
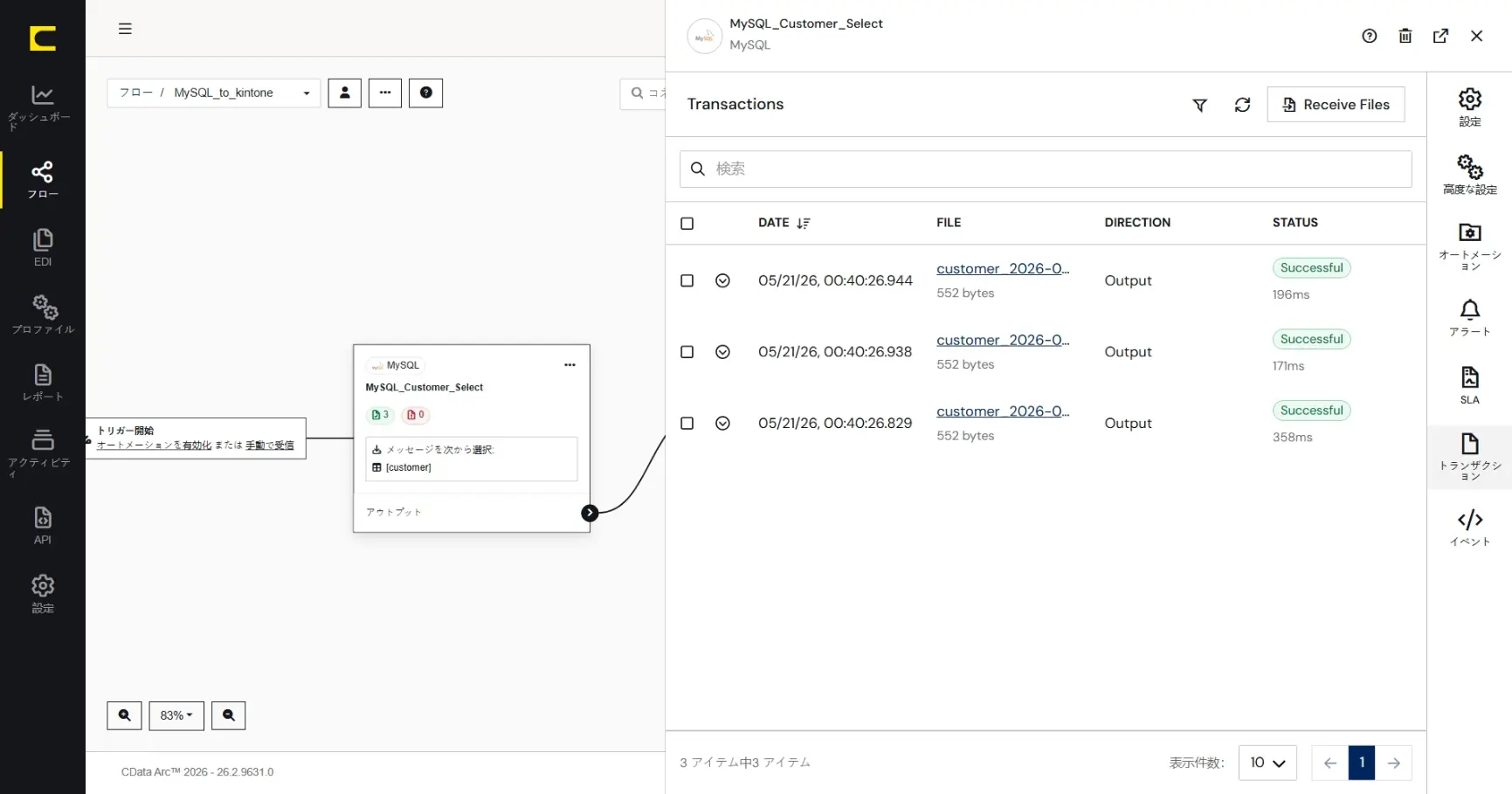
実行結果の確認
MySQL コネクタのトランザクションタブを確認すると受信の成功が確認できます。受信に成功(Success)したメッセージファイルは、オートメーションの機構により、後続のXML Map コネクタに渡されます(インプットされます)。
XMLMap コネクタのトランザクションタブより、MySQL コネクタから渡されたメッセージファイルがマッピングされ、アウトプットされていることが確認できます。
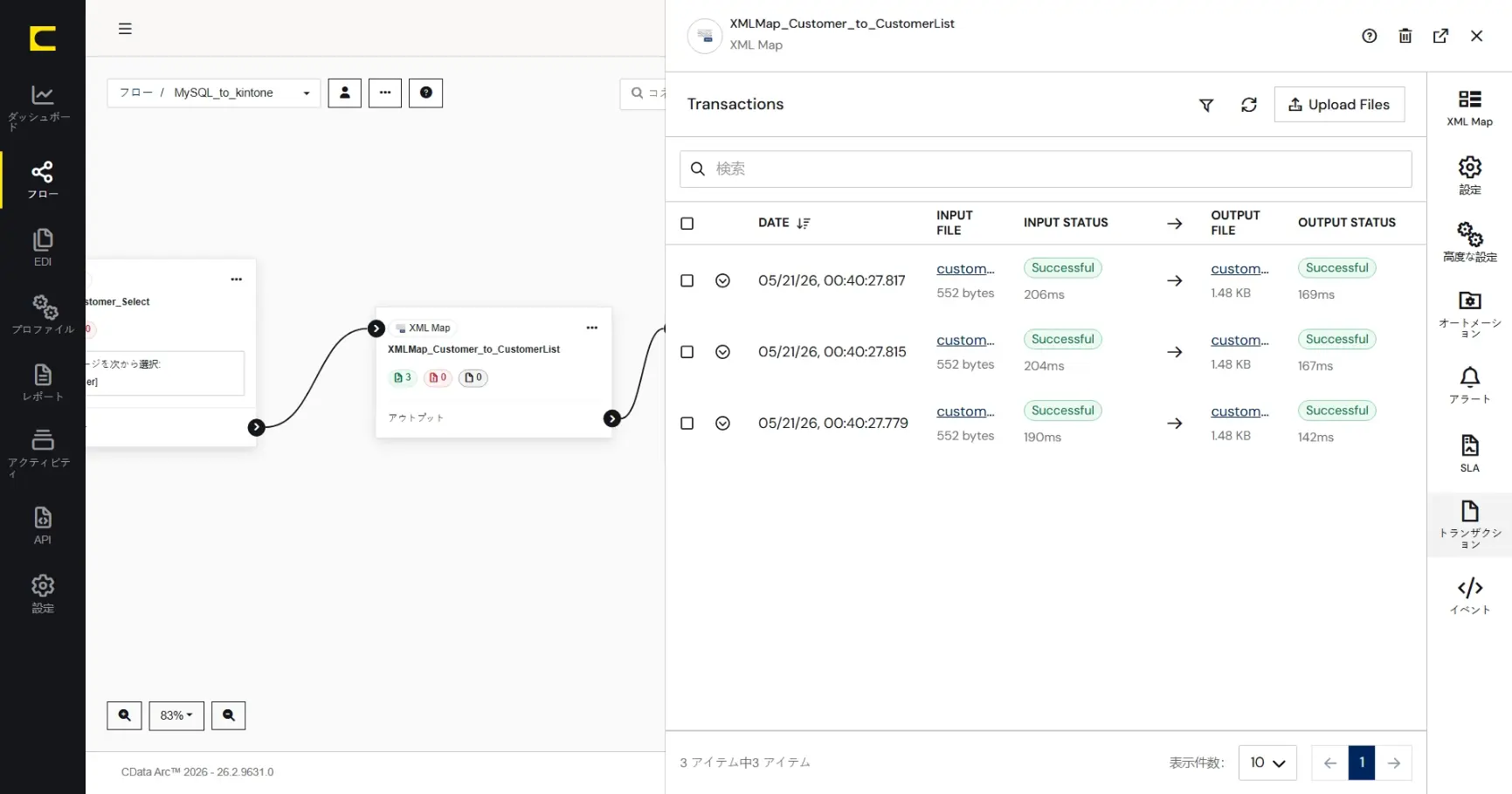
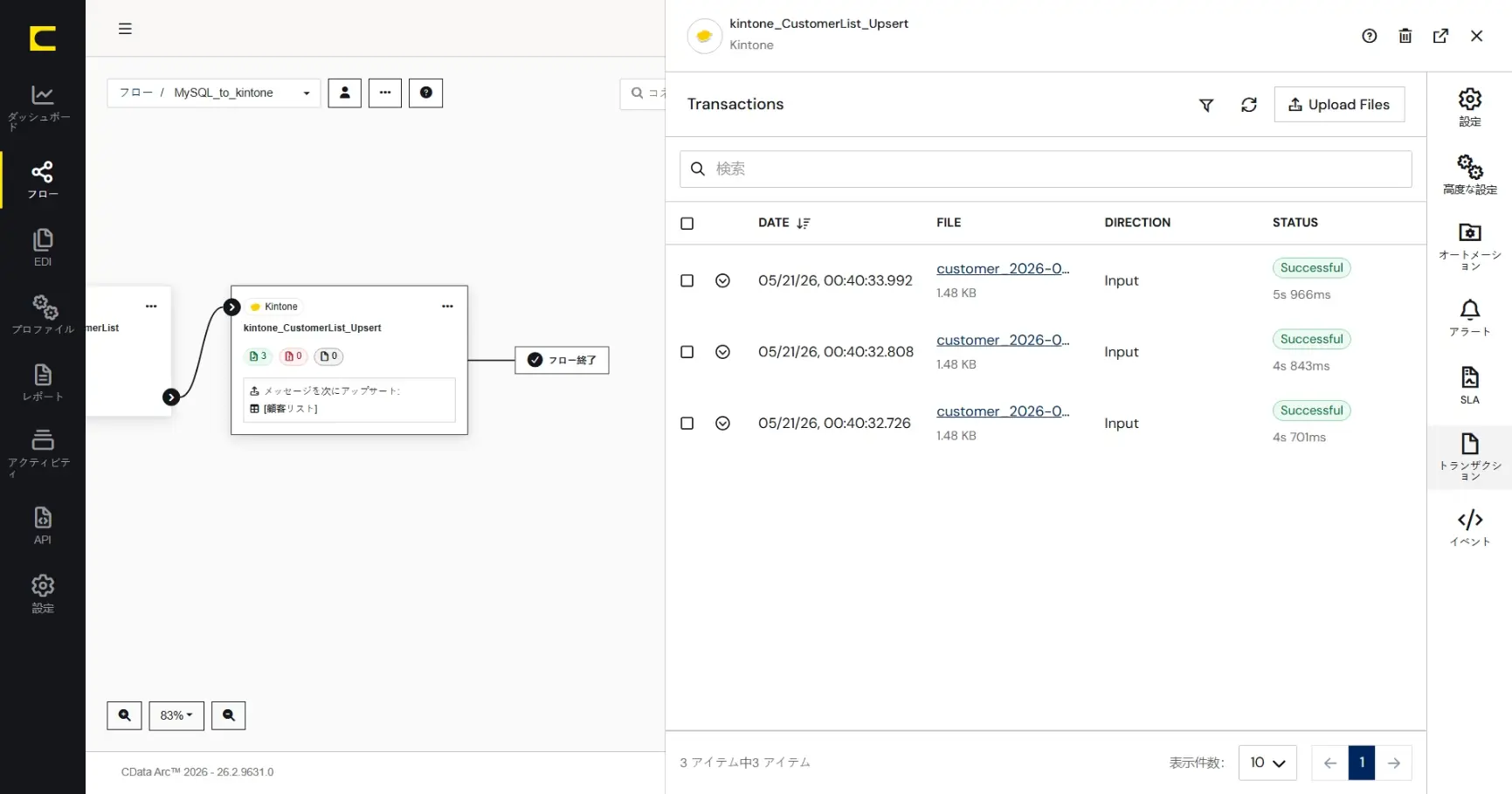
最後のkintone コネクタの「トランザクション」タブで、XMLMap コネクタから渡されたメッセージファイルで指定した処理(Upsert)に成功していることが確認できます。
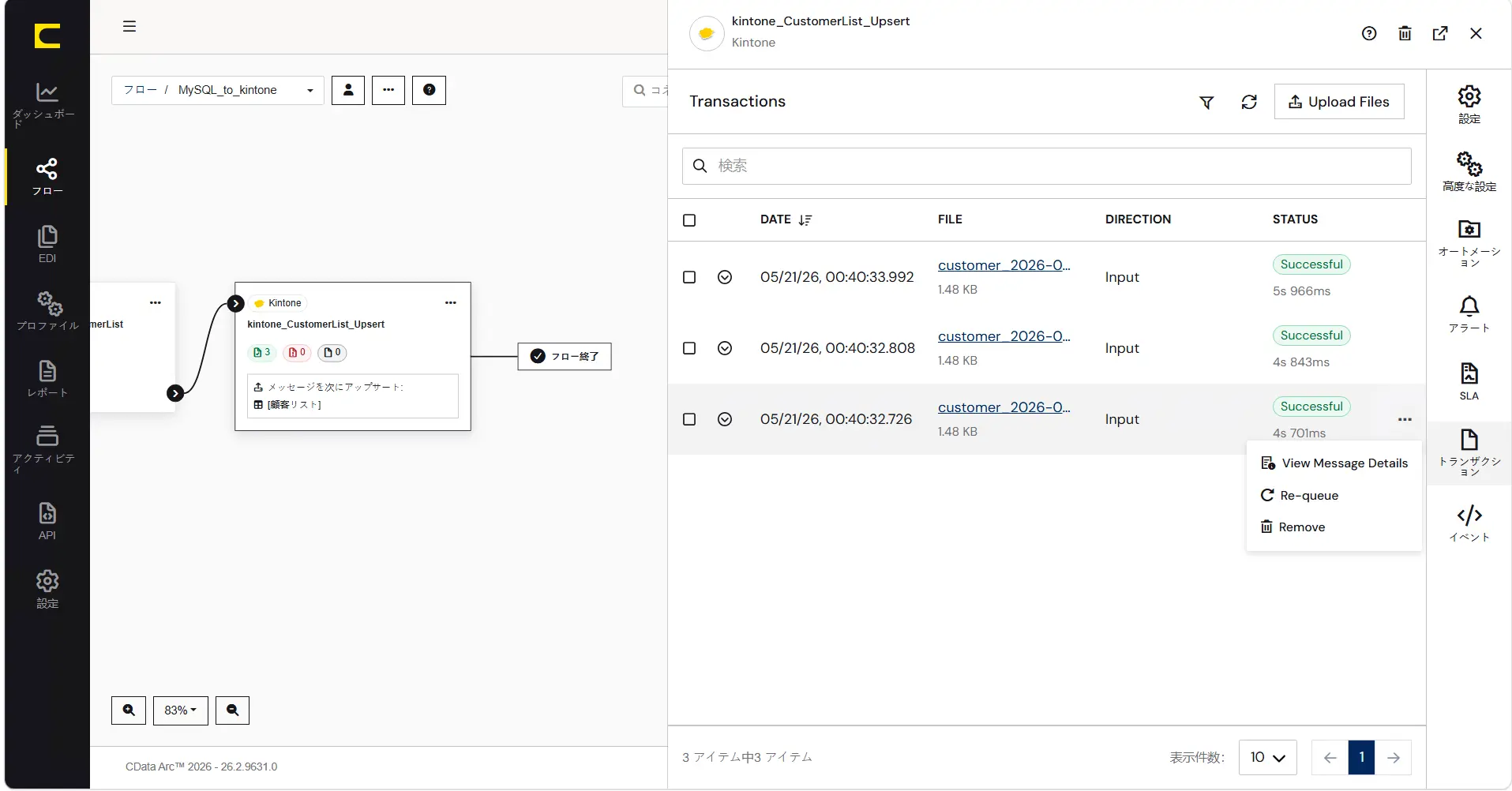
コネクタ実行履歴の右端に表示される「View Message Details」から、ログページ上で「フローの一連の流れ」として確認することもできます。
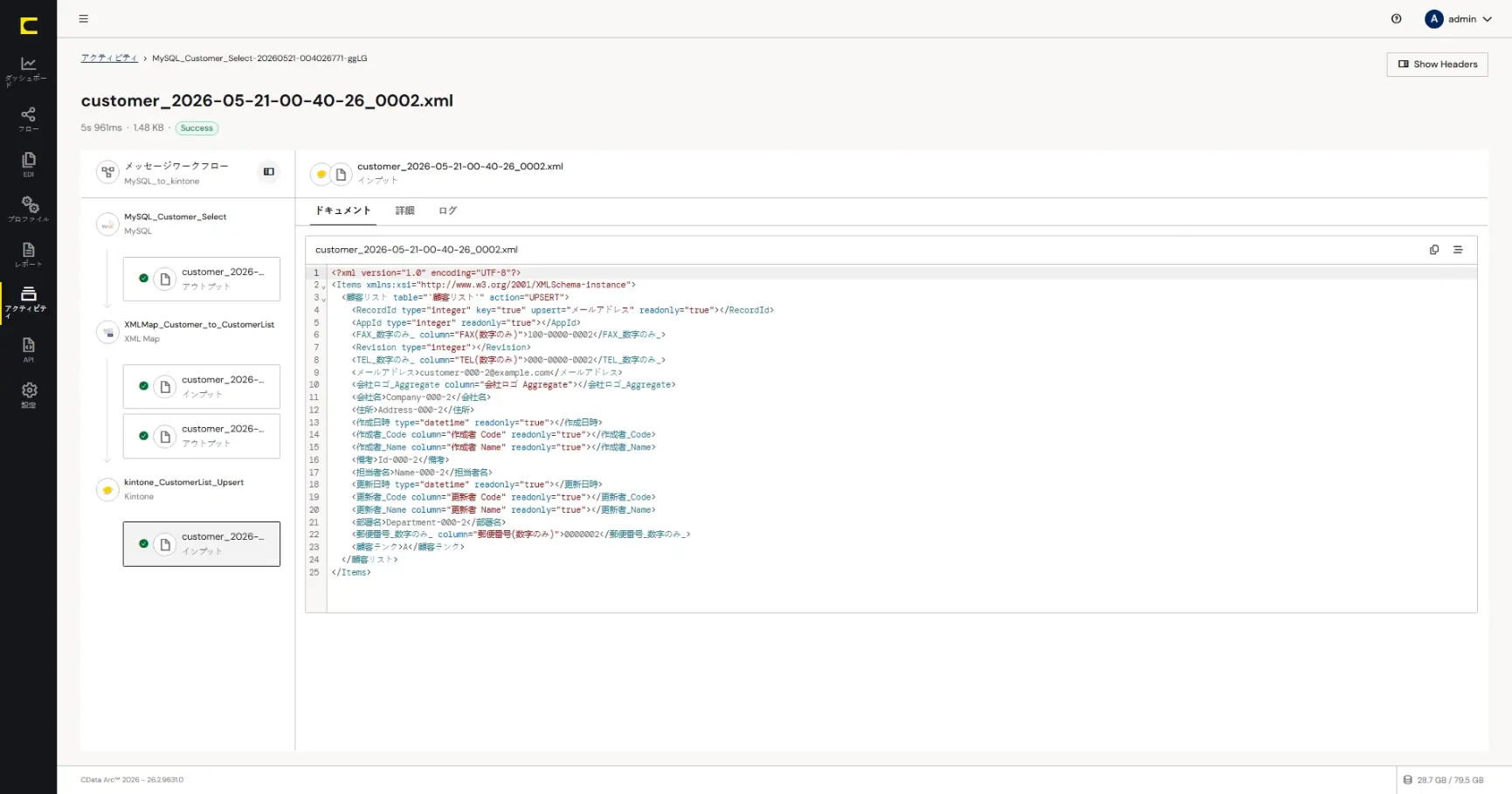
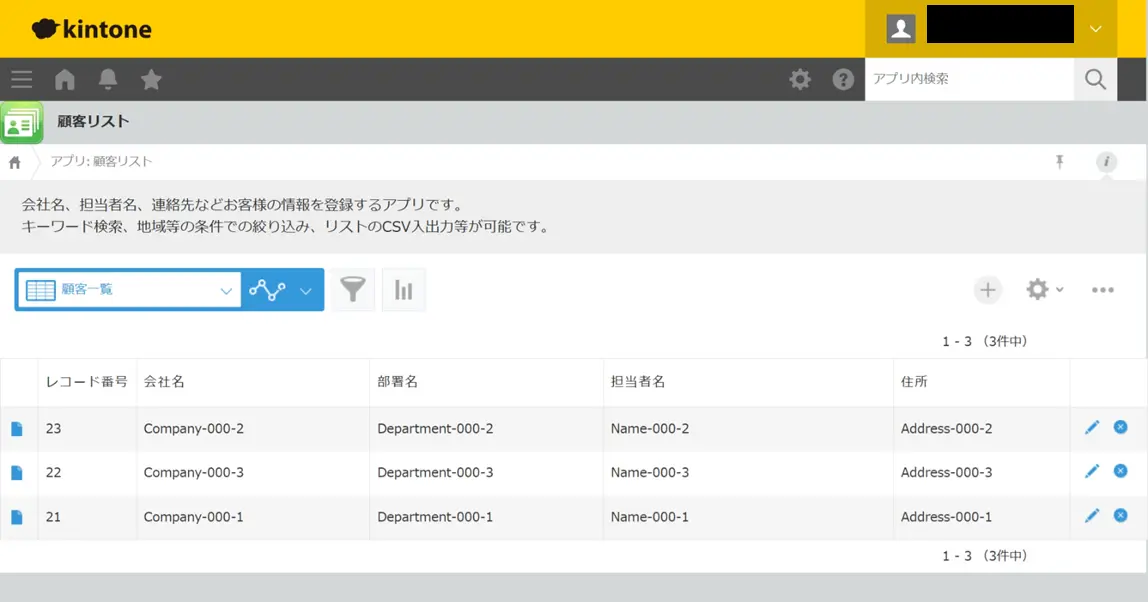
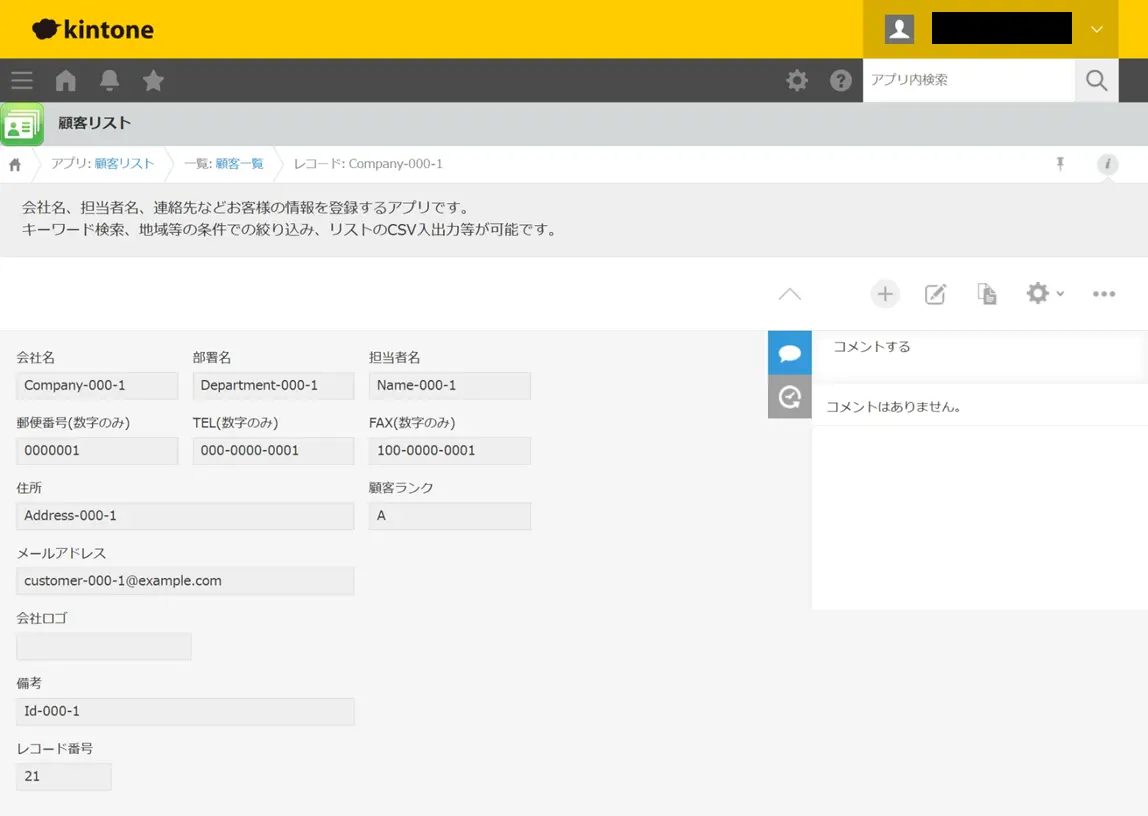
kintone 上での結果確認
kintone の「顧客リスト」アプリの内容を確認してみます。このハンズオンでは同じ顧客リストアプリへ、複数の参加者の方々がそれぞれの顧客情報を登録しているので、自分が連携を実行したデータが登録されているかを確認します。
フローの自動実行
CData Arc にはスケジューリング実行するための機能が標準で搭載されています。開発・テストが完了した連携フローを自動で定期的に実行したいときに便利です。スケジュール実行はフローの起点となるコネクタで「受信オートメーション」を有効にすることで設定します。この設定は「トリガーを開始」の「オートメーションを有効化」からも開く事ができます。
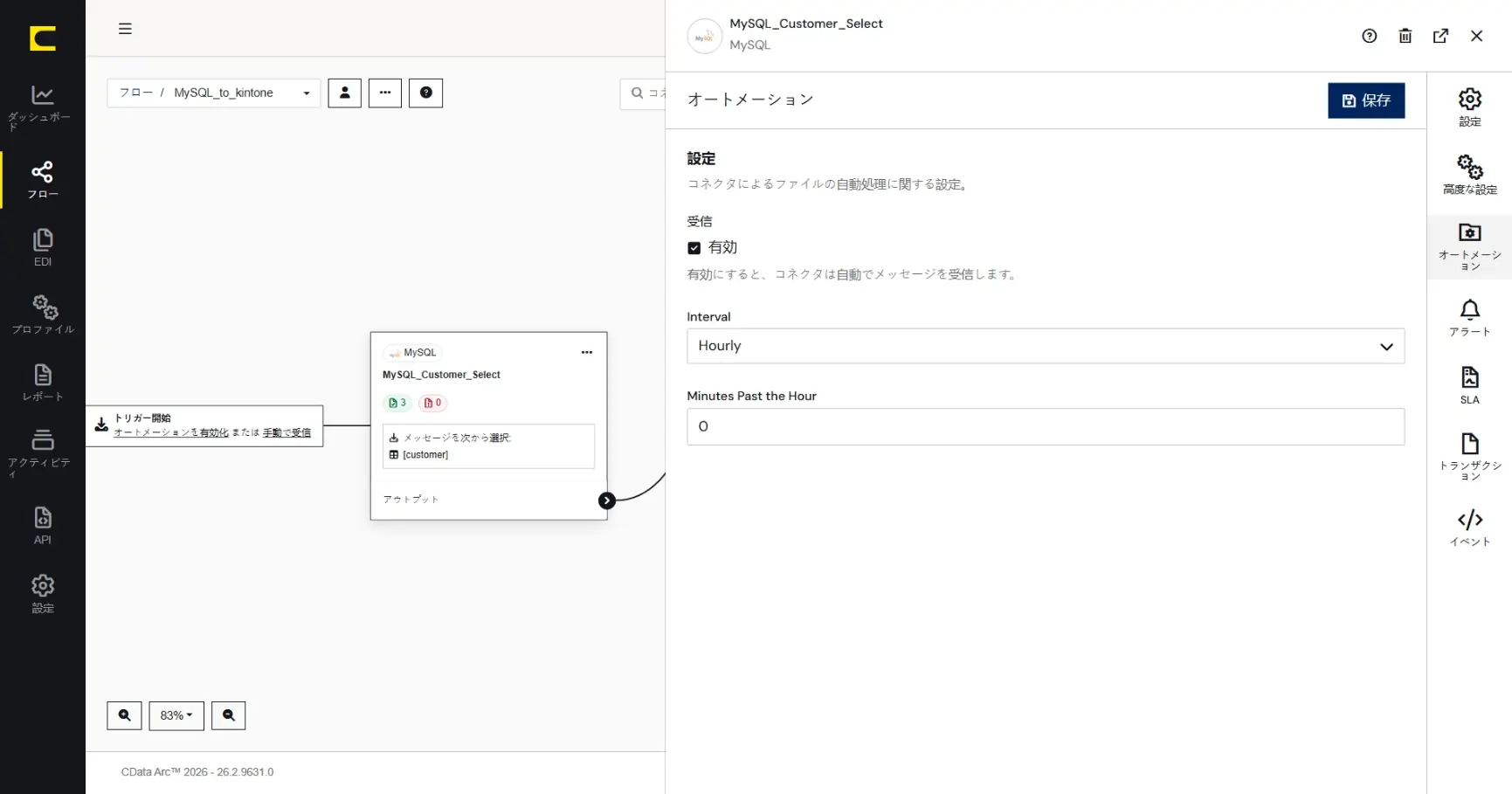
このシナリオのフローを、1時間に1度、毎時0分に自動実行する場合は、MySQL コネクタの「オートメーション」タブで下記のように設定します。
項目 | 設定する内容 |
受信 | 有効 |
受信間隔 | Hourly |
毎時何分 | 0 |
ここまでのまとめ
これで「CData Arc ハンズオンセミナー ~はじめてのCData Arc~」の「シナリオ1-1」が完了しました。
ハンズオンテキスト
シナリオ1-1
この記事では CData Arc™ 2026 - 26.2.9631.0 を利用しています。





