
はじめに
Oracle データベースを基幹に据えて CData Sync の Oracle CDC を運用していると、いくつかの典型的な悩みに直面することがあります。
一つは、主キーのないレガシーテーブルへの対応です。CData Sync の Oracle CDC では、主キーが定義されていないテーブルでもレコード値全体のハッシュ値を主キーの代替として CDC ジョブを構成できましたが、レコードが更新されるたびにハッシュ値も変わるため、同期先には UPDATE が同一行の更新として反映されず、新規レコードが積み上がってしまうという課題がありました。回避策として疑似主キー列をテーブルに追加する方法もありましたが、長年運用されてきたレガシースキーマへの変更はリスクを伴います。
もう一つは NUMBER 型の型不一致です。Oracle の NUMBER 型は精度・スケールを省略して定義でき、可変長の数値型として扱われます。PostgreSQL や Snowflake といった同期先へレプリケートする際、CData Sync は桁あふれの可能性を考慮して、こうした精度未指定の NUMBER 列を意図的に VARCHAR にフォールバックすることでデータを安全に連携していました。その分、本来数値である列が同期先で文字列として表現されてしまい、BI ツールや下流の SQL でキャストが必要になるという課題がありました。さらに、スケール 0 の純粋な整数データであっても同期先では NUMERIC や DECIMAL にマップされ、BI ツール側で整数として扱われないという課題も存在しました。
CData Sync V26.2 では、これらの課題に対する改善が複数リリースされました。本記事では実機検証を交えながら、ROWID 対応・NUMBER 型のデフォルト改善・DowncastNumbers 設定の 3 つを中心に、設定手順と運用上のメリットを解説します。本記事では検証に CData Sync 26.2.9629、同期先に Snowflake を使用しています(改善 3 の DowncastNumbers のみ、整数型の差異がわかりやすい Databricks を同期先にしています)。
CData Sync V26.2 での Oracle CDC 改善ポイント
V26.2 では Oracle CDC まわりで以下の改善が行われています。
ROWID 対応 — ROWID 列をレプリケート可能になり、主キーなしテーブルでは ROWID を主キー代替として利用できるようになりました
NUMBER 型のデフォルト精度・スケールを接続プロパティで制御 — Oracle 接続に DefaultPrecision と DefaultScale が追加され、精度未指定の NUMBER 列に適用するデフォルト値を指定できるようになりました
DowncastNumbers 設定の追加 — Oracle 接続プロパティで NUMBER 型の整数データを同期先のプリミティブ整数型に変換できるようになりました
MERGE 処理が一時テーブル経由に — Oracle 18c 以降は PRIVATE TEMPORARY TABLE、それ以前は GLOBAL TEMPORARY TABLE を経由するようになり、Oracle 側の書き込み負荷を削減できます
本記事では前者の 3 つを中心に、実機での設定手順を交えて解説し、最後に一時テーブル活用についても触れます。
改善 1 ROWID 対応で主キーなしのレガシースキーマも CDC 可能に
旧来の課題
Oracle CDC では、主キーが定義されていないテーブルでも CDC ジョブ自体は構成・実行できました。CData Sync が各行のレコード値全体からハッシュ値を算出し、それを主キーの代替として変更追跡に利用するためです(このあと紹介する RowHash の挙動)。
ただしこの方式には大きな課題がありました。レコードの値が更新されるとハッシュ値も変わってしまうため、CData Sync からは「既存レコードの更新」ではなく「別レコードの新規追加」として扱われ、同期先には毎回新しいレコードが積み上がっていく、という挙動になっていました。レガシーテーブルで UPDATE が発生するワークロードでは、同期先テーブルに古い行と新しい行が両方残ってしまい、ソースと同期先のレコード状態が一致しなくなるという課題がありました。
回避策として疑似主キー列(たとえば SEQUENCE 採番の連番カラム)を追加する方法もありましたが、既存スキーマへの変更はテスト工数や移行リスクを伴います。
V26.2 での変更
V26.2 では Oracle CDC ジョブで ROWID 列をレプリケート対象として含められるようになりました。ROWID は Oracle が各行に内部的に割り当てる一意識別子であり、主キーが定義されていないテーブルでも、ROWID を主キーの代替として CDC の変更追跡に利用できます。
仕組みとしては、ジョブの追加オプション SyncIdSourceColumn が追加され、以下の値を指定できるようになりました。
値 | 説明 |
|---|
RowHash
| 行全体のハッシュ値を変更追跡キーとして使う(従来の挙動) |
OracleRowId
| Oracle の ROWID 疑似カラムを変更追跡キーとして使う |
V26.2 で新規作成した Oracle CDC ジョブは、SyncIdSourceColumn が自動的に OracleRowId に設定されます。 つまり、新規ジョブであれば特別な設定をしなくても ROWID ベースの CDC が利用できます。既存ジョブはこれまでどおり RowHash のままで動作するため、アップグレードによる挙動変化はありません。
設定手順(同期先 Snowflake で検証)
事前準備 Oracle CDC を利用するには、Oracle 側で LogMiner や Supplemental Logging などの事前セットアップが必要です。CDC 用のユーザー権限付与や Archive Log の設定など、Oracle 側で必要な準備手順はOracle (Native) ソースのヘルプドキュメントを参照してください。
ここでは主キーなしのレガシーテーブル LEGACY_ORDERS を Snowflake にレプリケートする想定で手順を示します。
検証用 Oracle テーブルは次の DDL で定義しています(主キー無し)。
CREATE TABLE CDATA.LEGACY_ORDERS (
ORDER_ID NUMBER,
CUSTOMER VARCHAR2(100),
AMOUNT NUMBER,
ORDER_DATE DATE
);
Step 1 — CDC ジョブを作成
「Jobs」タブから新しいジョブを作成し、ソース接続に Oracle、同期先接続に Snowflake を指定します。
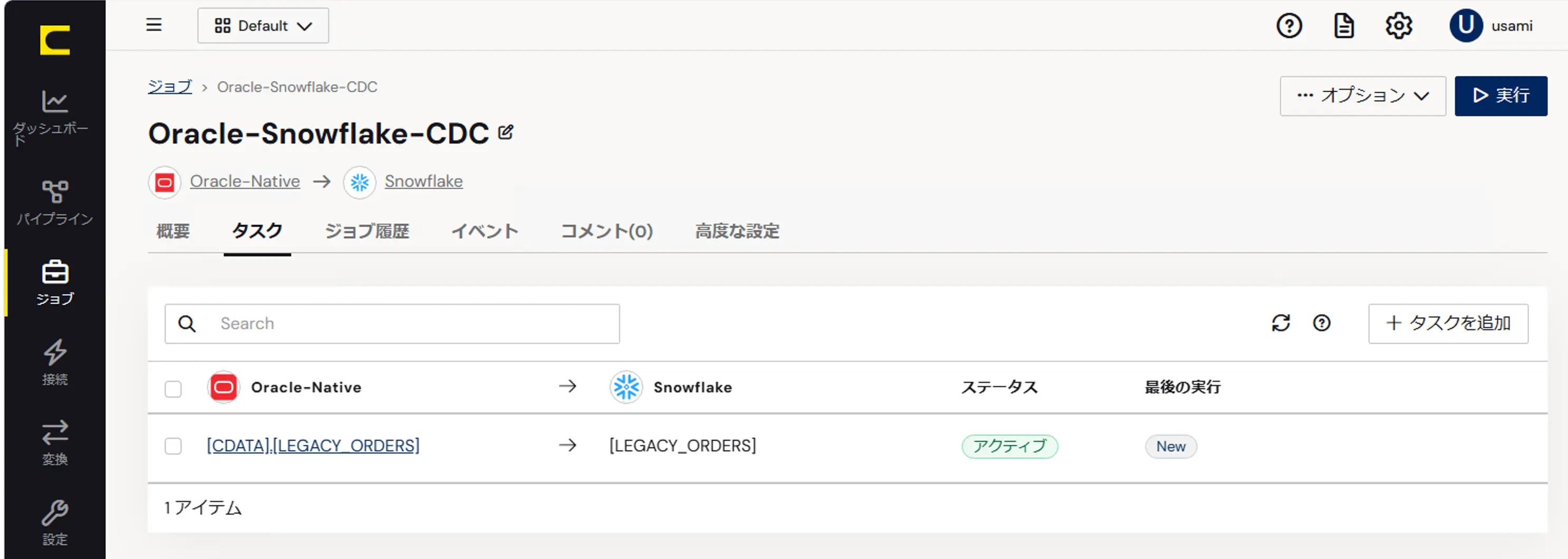
Step 2 — 対象テーブルをタスクに追加
ジョブのタスク一覧に LEGACY_ORDERS を追加します。タスク一覧に Oracle 側のテーブルがそのままマッピングされ、ステータスが「アクティブ」になっていれば準備完了です。
Step 3 — ジョブを実行して結果を確認
ジョブを実行すると、主キーが定義されていない LEGACY_ORDERS であっても Snowflake 側へ正常にテーブルが作成され、データがレプリケートされます。
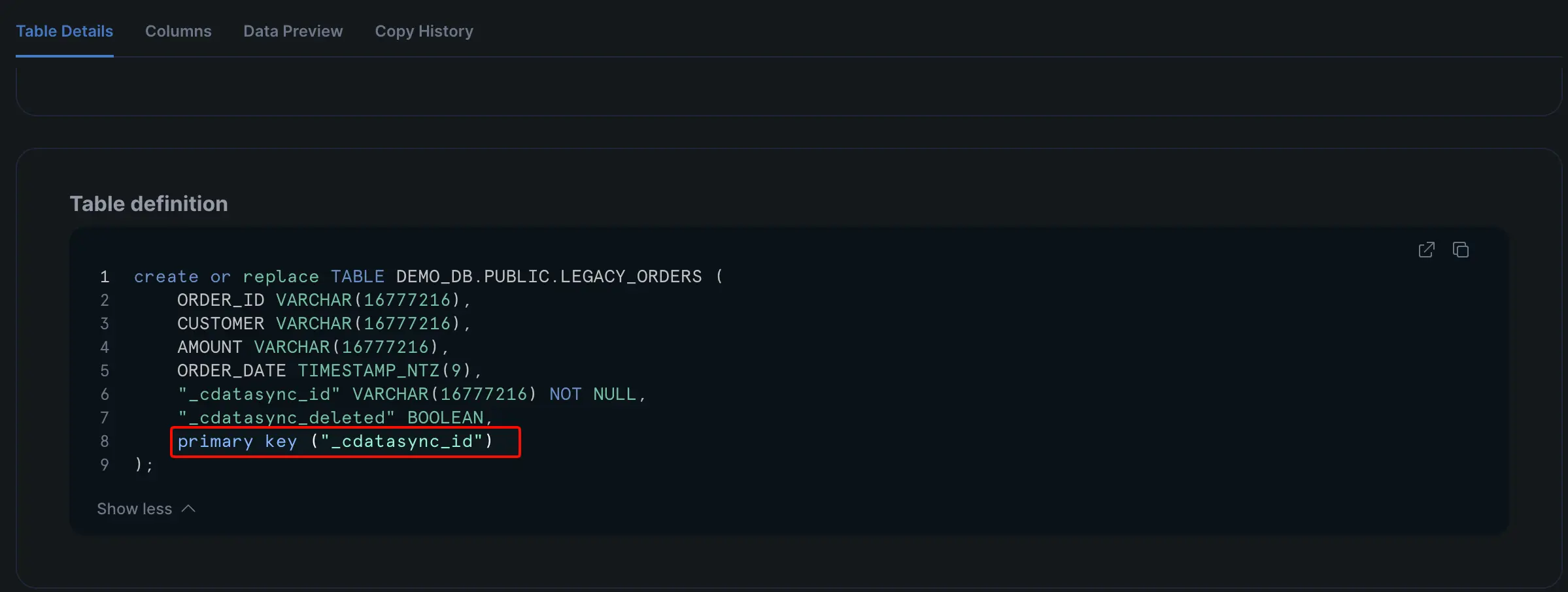
Snowflake 側に生成された LEGACY_ORDERS テーブル定義を見ると、_cdatasync_id カラムが追加され、これが主キーとして設定されていることが確認できます。Oracle 側に主キーが無いテーブルでも、CData Sync 側で ROWID から導出した値で主キーが補完されているのがわかります。
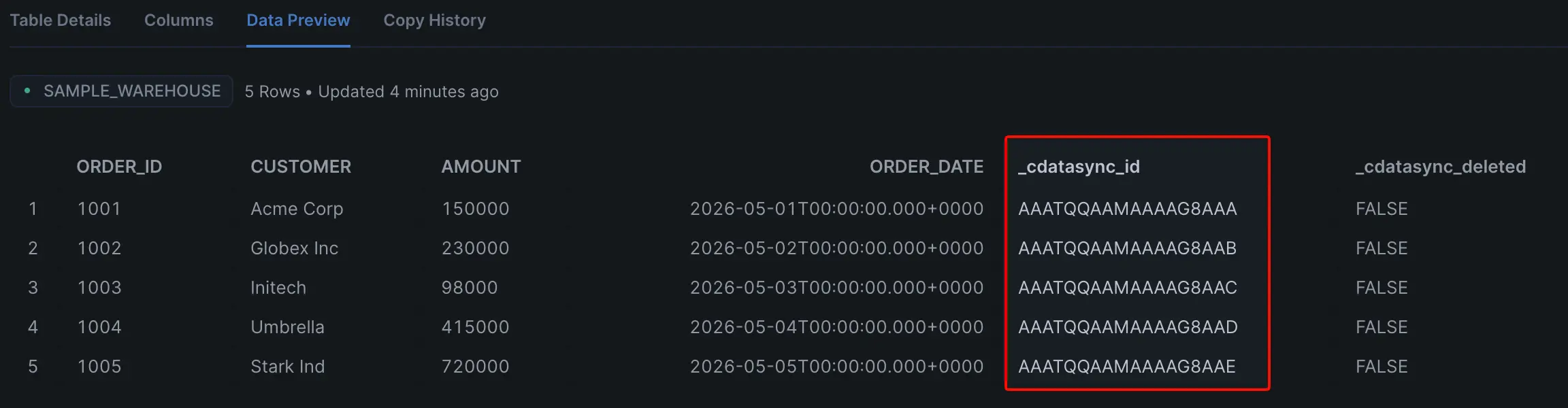
データプレビューを開くと、_cdatasync_id 列に Oracle 側 ROWID をベースとした一意な値(AAATQQAAMAAAAG8AAA など)が各行に格納されていることが確認できます。
運用上のメリット
この改善により、主キーが定義されていないレガシーテーブルに対しても、スキーマを一切変更することなく、UPDATE が正しく追従できる CDC 連携を実現できるようになりました。レコード値のハッシュに依存していた従来の方式では UPDATE のたびに同期先へ重複レコードが積み上がってしまっていましたが、ROWID を主キー代替として使うことで、行単位に一意かつ安定した識別子が確保され、UPDATE は同期先でも同じ行の更新として正しく反映されます。長年運用されてきた Oracle スキーマへの CDC 連携を、移行リスクを最小限に抑えながら導入できる点が主なメリットです。
改善 2 DefaultPrecision・DefaultScale で NUMBER 型の精度・スケールを制御可能に
旧来の課題
Oracle の NUMBER 型は NUMBER(p, s) のように精度(p)とスケール(s)を明示して定義できますが、省略した場合は可変長の数値型として扱われます。精度・スケールを持たない NUMBER 型は Oracle 内部では幅広い数値を格納できる柔軟な型ですが、他のデータベースへレプリケートする際に問題を引き起こしやすい性質があります。
たとえば PostgreSQL では NUMERIC 型の精度・スケールに上限があり、Oracle の可変精度 NUMBER からマッピングされた際に桁あふれを起こすケースがありました。Snowflake や ClickHouse でも同様の問題があり、型マッピングの不整合によるレプリケーションジョブ失敗の報告が寄せられていました。
CData Sync 側でも、同期先が Oracle の NUMBER 上限を表現できる DECIMAL/NUMERIC を持たないケースを考慮し、データを欠損させないために NUMBER 列を VARCHAR にフォールバックして連携する仕様が用意されていました。この挙動はデータ自体は安全に運べる一方で、本来数値である列が同期先で文字列として表現されてしまい、BI ツールの集計や下流の SQL での演算に追加のキャストが必要になるという課題がありました。
V26.2 での変更
V26.2 では Oracle 接続プロパティに DefaultPrecision と DefaultScale の 2 つが追加されました。Oracle 側で精度・スケールが定義されていない NUMBER 列を CData Sync 内部で扱う際の精度・スケールとして使われる値で、接続単位でユーザーが指定できるようになります。
接続プロパティ | 役割 |
|---|
DefaultPrecision
| 精度が指定されていない NUMBER 列を CData Sync 内部で扱う際のデフォルト精度 |
DefaultScale
| スケールが指定されていない NUMBER 列を CData Sync 内部で扱う際のデフォルトスケール |
注記 DefaultPrecision・DefaultScale は、精度・スケールが定義されていない Oracle 側 NUMBER 列を CData Sync 内部で扱う際のデフォルト値であり、その値がそのまま同期先カラム定義の精度・スケールとして書き込まれるわけではありません。CData Sync は DECIMAL/NUMBER 型を同期する際、同期先ごとに既定の型マッピングルールを持っており、内部で適用された DefaultPrecision・DefaultScale がそのルールを通じて同期先の型へ変換されます。
同期先で扱いやすい精度・スケールに内部値を寄せておくことで、可変精度 NUMBER から派生する型不一致やレプリケーションジョブ失敗を未然に防げます。これまで VARCHAR にフォールバックされていた列も、内部精度を同期先の DECIMAL/NUMERIC 上限内に収まる値へ調整しておくことで数値型として連携できるようになり、BI 側での扱いやすさも改善します。
設定手順(同期先 Snowflake で検証)
検証用に、精度未指定の NUMBER 列を含むテーブル NUMBER_TEST を用意しました。
CREATE TABLE CDATA.NUMBER_TEST (
ID NUMBER(10),
VAL_NO_PREC NUMBER,
VAL_DECIMAL NUMBER(10,2),
LABEL VARCHAR2(50)
);
VAL_NO_PREC 列は精度・スケールの指定がないため、Oracle 内部では可変精度として扱われます。DefaultPrecision と DefaultScale の効果を確認するうえで対象になる列です。
Step 1 — Oracle 接続プロパティで DefaultPrecision・DefaultScale を指定
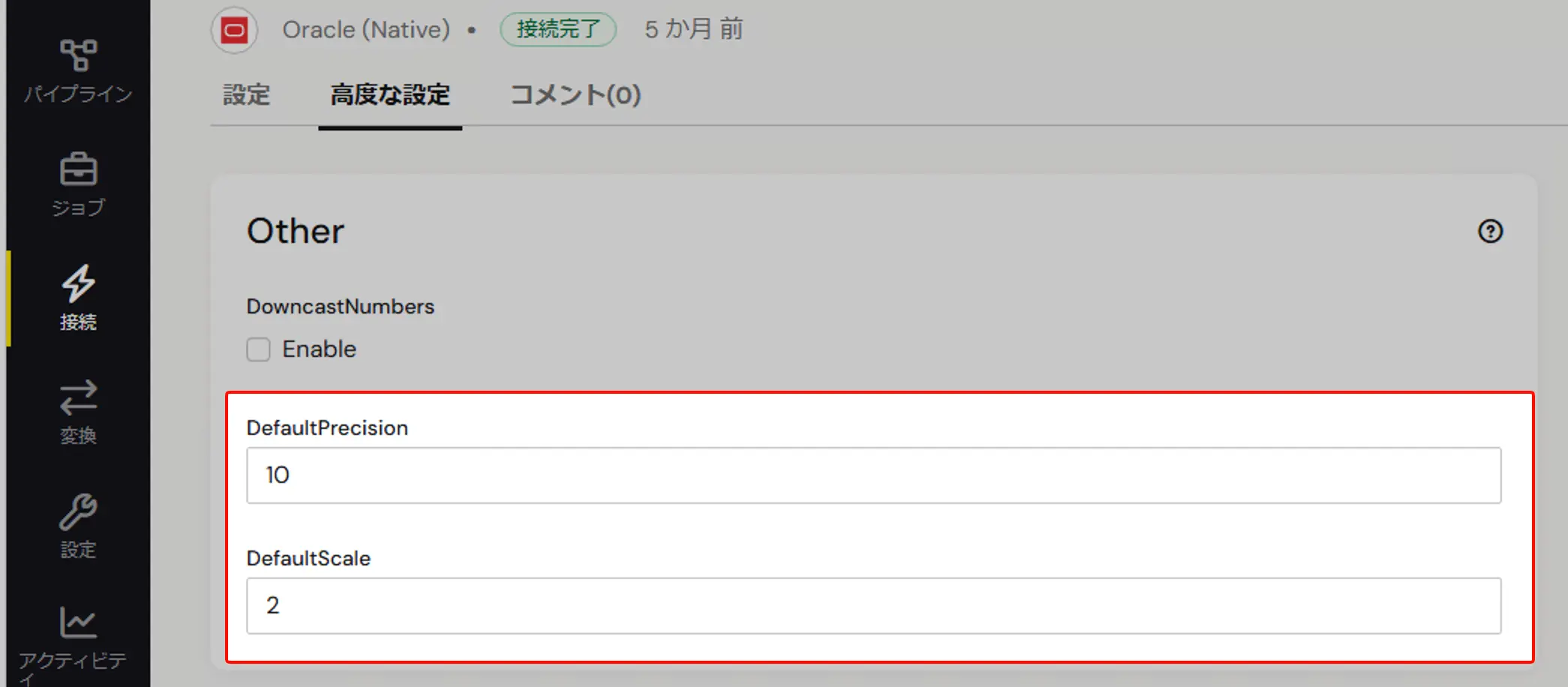
Oracle 接続の編集画面で「高度な設定」タブを開き、「Other」セクションにある DefaultPrecision と DefaultScale に同期先で扱いやすい値(ここでは DefaultPrecision = 10、DefaultScale = 2)を入力して保存します。同期先のデータベースが許容する上限を踏まえて指定してください。
Step 2 — ジョブを実行して結果を確認
ジョブを実行し、Snowflake 側で NUMBER_TEST のカラム型を確認します。VAL_NO_PREC 列は NUMBER(38,2) としてレプリケートされており、DefaultPrecision・DefaultScale で指定した内部精度・スケールを起点に、CData Sync の Snowflake 向けマッピングルール(精度は Snowflake 上限の 38、スケールは DefaultScale の値 2 がそのまま採用)を経由して同期先の型へ変換されていることが確認できます。
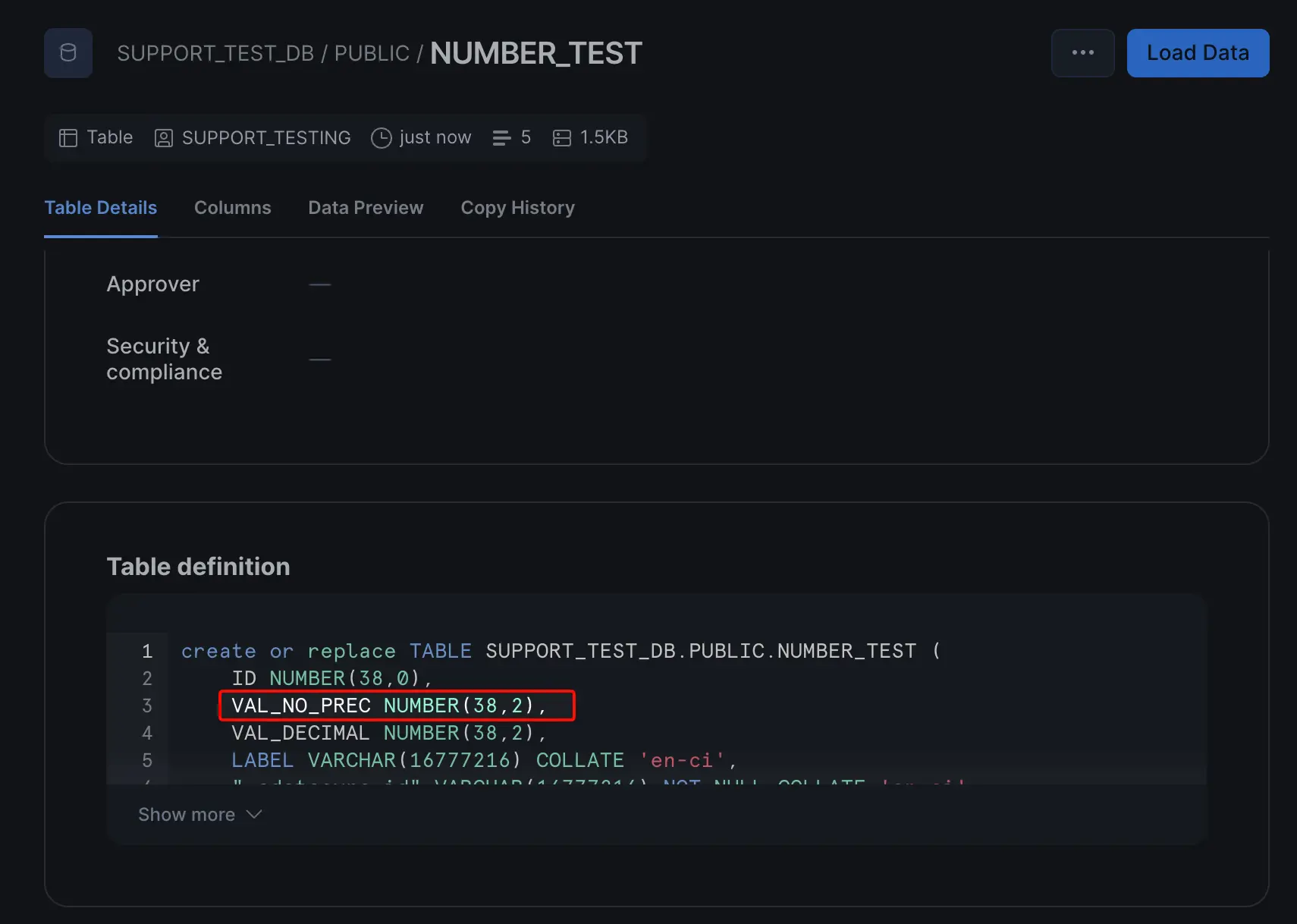
運用上のメリット
最大のメリットは、これまで精度・スケール未指定の NUMBER 列が VARCHAR にフォールバックされていたケースを、そのまま数値型として連携できるようになる点です。DefaultPrecision・DefaultScale で CData Sync 内部での精度・スケールを明示しておくことで、同期先の DECIMAL/NUMERIC 上限を超えるとみなされて VARCHAR に倒れていた列が、数値型としてマッピングされるようになります。BI ツールや下流の SQL で文字列から数値へのキャストが不要になり、可変精度 NUMBER に起因する型不一致エラーやジョブ失敗の抑制も期待できます。
改善 3 DowncastNumbers で NUMBER 型の整数データをプリミティブ整数型に変換
旧来の課題
Oracle で NUMBER(10,0) のようにスケール 0 で定義された列は意味的には整数ですが、同期先へレプリケートする際にはほぼ常に NUMERIC/DECIMAL 系の型にマップされていました。Databricks であれば DECIMAL(10,0)、PostgreSQL であれば NUMERIC(10,0) といった具合です。
データ自体は問題なく格納できる一方で、BI ツールや下流の SQL 処理から見ると「数値だが整数型ではない」状態になり、整数として扱った演算や集計でキャストが頻発したり、列の意味からスキーマ設計者の意図が伝わりにくくなったりするという指摘がありました。
V26.2 での変更
V26.2 では Oracle 接続プロパティに DowncastNumbers が追加されました。このプロパティを有効にすると、NUMBER 型のうち整数として扱える列(スケールが 0 の列)が同期先のプリミティブな整数型に変換されてレプリケートされるようになります。
設定手順(同期先 Databricks で検証)
検証用に、スケール 0 の NUMBER 列のみを持つテーブル DOWNCAST_TEST を用意しました。
CREATE TABLE CDATA.DOWNCAST_TEST (
ID NUMBER(10),
INT_COL NUMBER(10,0),
LABEL VARCHAR2(50)
);
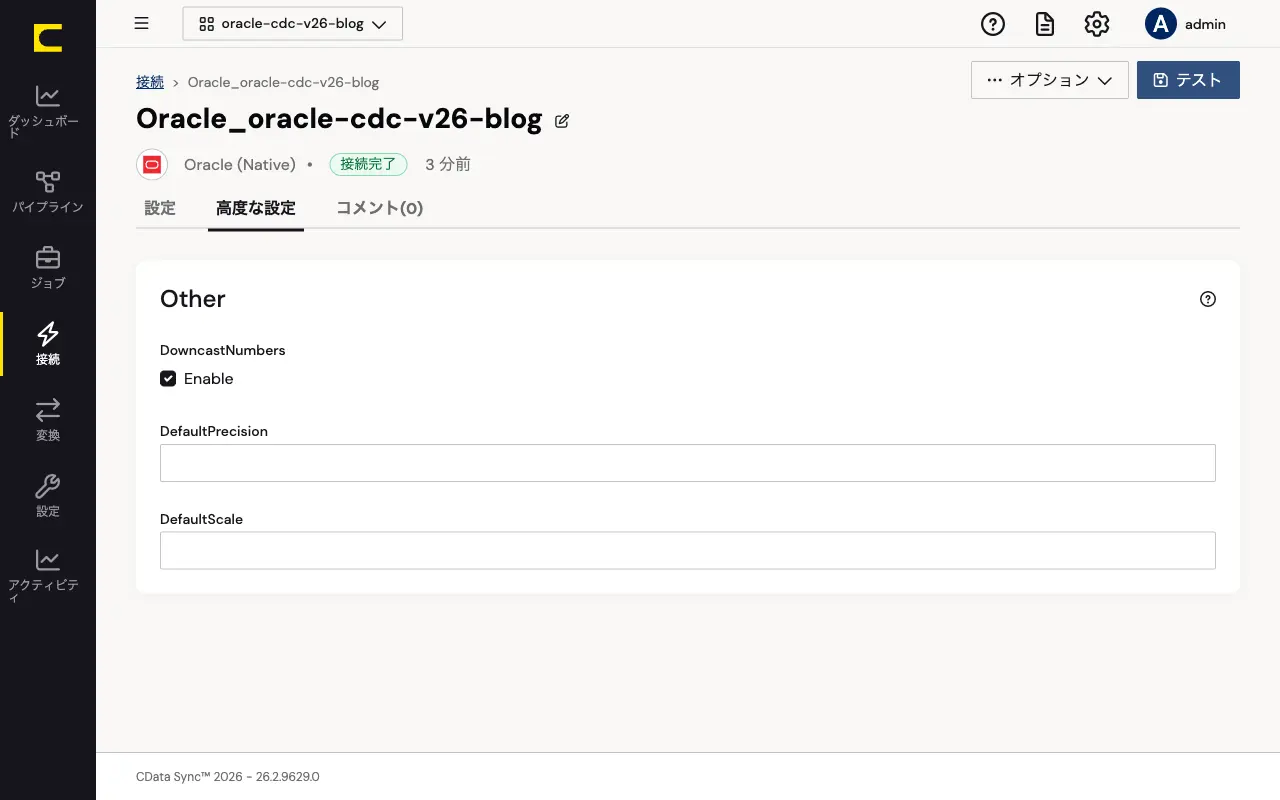
Step 1 — Oracle 接続プロパティで DowncastNumbers を有効化
Oracle 接続の編集画面で「高度な設定」タブを開き、「Other」セクションにある DowncastNumbers の Enable チェックボックスをオンにして保存します。
Step 2 — ジョブを実行して Databricks 側のカラム型を確認
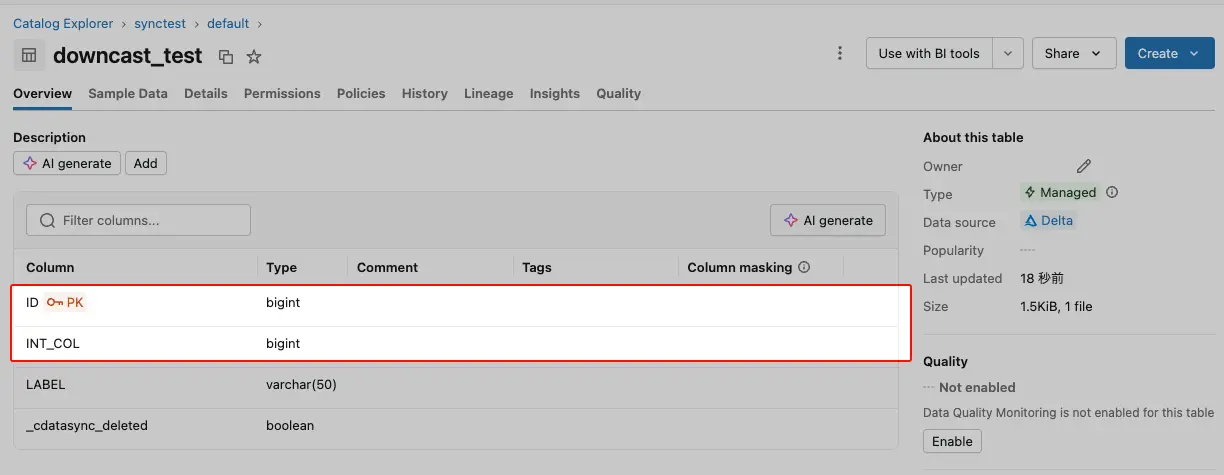
検証のため用意した DOWNCAST_TEST テーブルのタスクを追加しジョブを実行すると、Oracle 側で NUMBER(10,0) として定義されていた整数列が、Databricks 側では DECIMAL ではなくプリミティブな整数型としてレプリケートされます。
カラム名 | Oracle 側 | Databricks 側(DowncastNumbers = OFF) | Databricks 側(DowncastNumbers = ON) |
|---|
ID | NUMBER(10) | DECIMAL(38,0) | BIGINT |
INT_COL | NUMBER(10,0) | DECIMAL(38,0) | BIGINT |
LABEL | VARCHAR2(50) | VARCHAR(50) | VARCHAR(50) |
OFF 時は DECIMAL(38,0) としてレプリケートされていた整数列が、ON では BIGINT にマップされるようになり、Databricks 側のスキーマ表現が Oracle 側の意味(純粋な整数列)と一致します。PostgreSQL や Redshift、BigQuery など、プリミティブな整数型を持つ同期先でも同様の効果が得られます。
運用上のメリット
DowncastNumbers を有効にすることで、Oracle 側で意味的に整数として定義されていた列が、同期先でも整数型として表現されるようになります。BI ツールから整数列として認識される、ETL 後の SQL で不要なキャストが減る、スキーマの意図が下流に伝わりやすくなる、といった効果が期待できます。
その他の改善 MERGE 処理が一時テーブル経由に
CDC ジョブや差分連携ジョブのように、ソース側で発生した差分を同期先 Oracle に反映するケースでは、内部的に MERGE 処理(主キーで突き合わせて UPDATE/INSERT を行う処理)が頻繁に発生します。こうした差分連携が中心のジョブについても、Oracle インフラ側の負荷を下げる改善が V26.2 で行われています。
V26.2 では、MERGE 処理の中間テーブルとして一時テーブルを活用するようになりました。Oracle 18c 以降では PRIVATE TEMPORARY TABLE、それ以前では GLOBAL TEMPORARY TABLE を使用します。一時テーブルは Oracle の REDO ログに書き込まれないため、差分反映のたびに発生していた書き込み増幅を大幅に削減できます。DBA 視点では UNDO セグメントや REDO ログの肥大化が抑えられ、高頻度で差分が流れてくる Oracle CDC や差分連携ジョブでの Oracle 側リソース消費を改善します。
この変更はユーザー側の設定変更を必要とせず、V26.2 へのアップグレードにより自動的に有効になります。
まとめ
CData Sync V26.2 では Oracle CDC まわりの改善が複数リリースされました。主キーなしのレガシーテーブルも ROWID を活用して CDC 連携が可能になり、DefaultPrecision・DefaultScale で NUMBER 型の精度・スケールを制御できるようになったことで同期先での型不一致も減少します。さらに DowncastNumbers の追加により、NUMBER 型の整数データを同期先のプリミティブ整数型としてレプリケートできるようになりました。MERGE 処理が一時テーブル経由になったことによる Oracle 側の書き込み負荷削減も、インフラを管理する立場からはうれしい改善です。
既存の Oracle CDC ジョブをそのまま動かしていても、アップグレードにより自動的に恩恵を受けられる改善も多く含まれます。ぜひ CData Sync V26.2 をお試しいただき、Oracle CDC 連携の安定運用にお役立てください。CData Sync の 30 日間無償トライアルはこちらからダウンロードいただけます。
また、使っていて気になった点やご不明な点があれば、お気軽にテクニカルサポートまでお問い合わせください。





