データパイプラインとETLの違いは、対象とする「範囲」にあります。ETLパイプラインは「抽出・変換・ロード」という特定の処理フローを指すのに対し、データパイプラインはその処理を内包しつつ、データの収集から保存・分析・活用までを一貫して担う上位概念です。
この記事では、データパイプラインとETLパイプラインの違いを整理した上で、ELTとの関係、自社に合った方式の選び方、設計の基本ステップ、代表的なツールまでを体系的に解説します。データ基盤の構築や見直しを検討しているIT担当者・データエンジニアの方の判断材料になれば幸いです。
目次
データパイプラインとETLパイプライン:まず違いを整理する
データパイプラインとETLパイプラインの最大の違いは「範囲」です。ETLパイプラインはデータパイプラインの一形態であり、上位・下位の包含関係にあります。ETLはデータパイプラインを構成する処理方式の一つであり、「ETL=データパイプライン」という等号は成り立ちません。
包含関係を整理すると次のようになります。
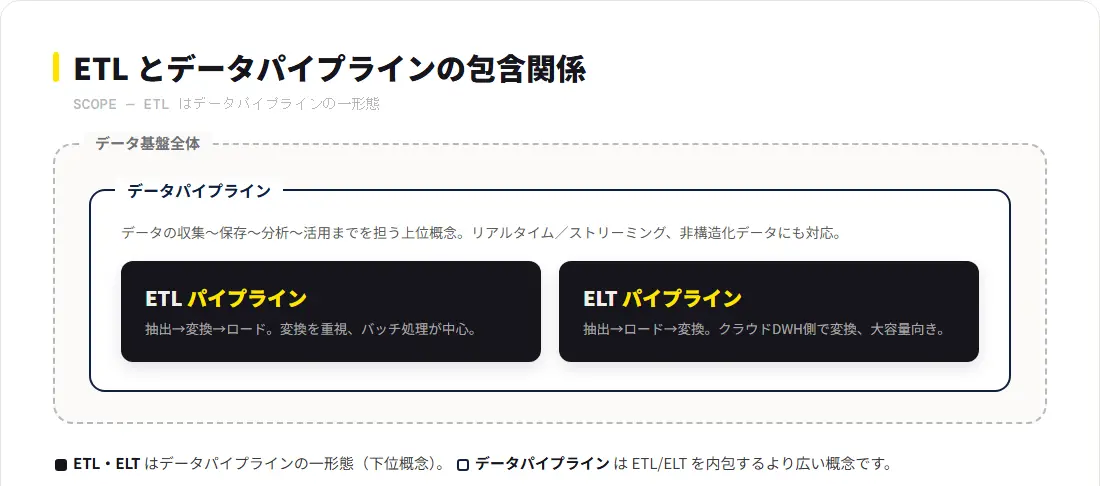
ETLパイプライン ⊂ データパイプライン ⊂ データ基盤全体
この2つが「同じ意味」で使われがちな背景には、データパイプラインを構築する際にETLが最も一般的な処理方式として採用されてきた歴史があります。しかし近年のクラウドDWH普及によってELT(ロード後変換)が台頭し、ストリーミング処理の需要も高まる中で、「データパイプライン」と「ETL」を明確に区別して理解することが重要になっています。
ETLパイプラインとは
ETLパイプラインとは、データを「抽出(Extract)・変換(Transform)・ロード(Load)」する一連の処理フローです。データ品質の向上と複雑な変換処理に強みを持ち、バッチ処理やBIツールへの活用、コンプライアンス要件への対応に適しています。主に次の3ステップで構成されます。
抽出(Extract): データベース、CSVやExcelなどのファイル、Webサービスといった複数のソースから生データを収集します。完全抽出(全件取得)と増分抽出(更新分のみ取得)の2方式があります。
変換(Transform): 抽出したデータにクリーニング・正規化・統合を施し、分析や利用目的に合った形式に整えます。複雑なビジネスロジックの適用もこの段階で行います。
ロード(Load): 変換済みのデータをDWH(データウェアハウス)やDBなどのストレージシステムに格納します。BIツールや各種アプリケーションから活用できる状態に整えます。
ETLの仕組み・メリット・活用シナリオをさらに詳しく知りたい方は、ETLとは?仕組み・メリット・ツール比較・導入事例を徹底解説をあわせてご覧ください。
データパイプラインとは
データパイプラインとは、データソースからデータを収集し、保存・分析・活用できる目的地まで移動させるプロセスの全体を指します。ETL・ELT処理の全部または一部を含む場合もありますが、それに限定されるものではなく、リアルタイムのストリーミング処理や多様なデータ形式への対応も包含します。
データパイプラインは、データの生成から格納・分析・活用までをつなぐ「データフローの基盤」として機能します。単にデータが移動する経路ではなく、未加工の生データを戦略的な意思決定に使えるインサイトへと変換するための仕組み全体です。
違いを一目で把握できる比較表
ETLパイプライン・ELTパイプライン・データパイプライン(広義)の三者を主要な観点で比較すると以下のようになります。
観点 | ETL パイプライン | ELT パイプライン | データパイプライン(広義) |
|---|
主な目的 | 抽出→変換→ロード(変換を重視) | 抽出→ロード→変換(クラウド側で変換) | データ移動・統合の全体(収集〜活用) |
処理タイミング | 変換してからロード | ロードしてから変換 | ETL/ELT/ストリーミングを包含 |
処理方式 | バッチ処理が中心 | バッチ(クラウドDWH向き) | リアルタイム/ストリーミング+バッチ |
対象データ | 構造化データが中心 | 構造化〜半構造化 | 構造化〜非構造化まで多様 |
変換処理 | 大規模・複雑な変換が得意 | クラウドDWH上でSQLにより変換 | 最小限〜任意(ETL/ELTを包含) |
適した用途 | DWH統合・BI・財務/規制対応データ | BigQuery・Snowflake連携・大容量分析 | 運用分析・リアルタイム・AI/MLへのデータ供給 |
日本での一般的な用途 | 基幹DB→DWHへの定期バッチ連携 | クラウドDWH活用・分析基盤構築 | IoT・EC・AI基盤・マルチソース統合 |
代表ツール例 | Microsoft SSIS、Talend、Informatica | trocco、Fivetran、Matillion(dbt連携) | Apache Kafka、CData Sync(マルチ対応) |
データパイプラインとの関係 | データパイプラインの一形態 | データパイプラインの一形態 | ETL・ELTを含む上位概念 |
※ETLパイプラインとELTパイプラインはいずれもデータパイプラインの下位概念です。「データパイプライン≠ETL」という点を意識した上で、以降の説明をお読みください。
それぞれの特徴と強み:どんな状況に向いているか
ETLパイプラインはデータ品質・複雑な変換・コンプライアンス対応に強みを持ち、データパイプライン(広義)はリアルタイム性・多様なデータ形式への対応・大容量処理に強みを持ちます。どちらが優れているというものではなく、用途と環境によって適切な選択肢は異なります。
ETLパイプラインが向いている状況
ETLパイプラインは、次のような状況で特に力を発揮します。
データ品質と精度が最優先の場合: ETLは変換処理の段階でデータのクリーニング・正規化・エンリッチメントを徹底的に行います。財務報告データや顧客マスタなど、高い精度と一貫性が求められるシナリオに適しています。
複雑な変換ロジックが必要な場合: 複数のデータソースを統合しながらビジネスロジックを適用したり、異なる形式のデータを統一フォーマットに変換したりするような複雑な処理は、ETLの得意領域です。
BIツール・DWHへの安定した定期連携: 基幹DBのデータをDWH(データウェアハウス)に月次・日次でバッチ転送し、BIツールで分析する構成はETLパイプラインが長く使われてきた典型的なユースケースです。
セキュリティ・コンプライアンス要件が厳しい場合: データリネージの維持、データプライバシーの確保、ガバナンスポリシーへの準拠が求められる金融・製造・医療分野での利用に向いています。個人情報保護法やISMSへの対応も、ETLパイプラインの構造化されたアプローチで対処しやすくなります。
ETLパイプラインの弱み: リアルタイムや準リアルタイムの処理は苦手です。また、クラウドDWHとの組み合わせではELTの方が効率的なケースが増えています。変換処理を担うサーバーのスペックや運用コストも考慮が必要です。
データパイプライン(広義)が向いている状況
データの流れをより広い視点で設計するデータパイプラインは、次のような状況に適しています。
リアルタイム・準リアルタイムの処理が必要な場合: ECサイトの在庫をリアルタイムに反映する、工場の製造ラインのセンサーデータを即時監視する、不正取引を瞬時に検知するといったユースケースでは、データパイプラインのストリーミング処理能力が不可欠です。
多様なデータ形式・大容量データを扱う場合: 構造化データに限らず、SNSのテキストデータ、IoTセンサーのログ、画像・音声などの非構造化データを横断的に扱う場合は、ETLより広い対応範囲を持つデータパイプラインが適しています。
複数のシステム・クラウドを横断するデータ統合: SaaSアプリケーション、オンプレミスの基幹系、クラウドDWHなど、異種のシステムが混在する環境でのデータ統合に適しています。
AI・機械学習へのデータ供給: AIモデルの学習や推論に使うデータを継続的に供給するパイプラインでは、多様なソースからのリアルタイムデータ収集が求められます。データパイプラインはこのような用途に対応できる柔軟性を持っています。
データパイプライン(広義)の弱み: 変換ロジックが複雑な場合、ETLに比べて実装コストが高くなることがあります。ストリーミング処理の設計・運用には専門的なスキルが必要なケースもあります。
ETLとELT:モダンデータスタックでの位置づけ
ELTは、BigQueryやSnowflakeといったクラウドDWHの普及とともに広まった処理方式です。生データをまずDWHに格納してから、DWH上の高いコンピューティング能力を使って変換します。ETLがオンプレミス環境や変換処理が複雑な場合に向くのに対し、ELTはクラウドDWHを活用した大容量データ処理に向いています。
ETLとELTの最大の違いは変換処理のタイミングです。ETLは「変換してからロード」、ELTは「ロードしてから変換」です。クラウドDWHが持つ強力な処理能力を活かせるELTは、データエンジニアリングの現場で「モダンデータスタック」の中心的な手法として注目を集めています。
データパイプラインはETLもELTも包含する概念です。自社の環境にETLが向くかELTが向くかを判断する上では、クラウドDWHへの移行状況、データ量、変換の複雑さが主な軸になります。
CDC(変更データキャプチャ):バッチとリアルタイムの中間解
「毎晩のバッチ処理では鮮度が足りないが、本格的なストリーミング基盤を構築するほどではない」という場面で有力な選択肢がCDC(Change Data Capture:変更データキャプチャ)です。
CDCは、データベースの変更ログ(トランザクションログ)を監視し、INSERT・UPDATE・DELETEといった変更が発生した時点でその差分だけをリアルタイムに連携する方式です。データベース全体をスキャンするフルバッチと比べて、転送データ量が少なく、ソースシステムへの負荷を抑えながら準リアルタイムの同期を実現できます。Oracle、SQL Server、PostgreSQL、SAP などのデータベースはCDCに対応しており、これらをソースにしたデータ連携で活用できます。
ETLとELTの詳細な比較・使い分けについては、ETLとELTの違いとは?自社にピッタリな手法はどっち?をご覧ください。
選び方:判断フローと自己診断チェックリスト
データパイプラインとETLの選定における基本軸は、①変換の複雑さ、②リアルタイム性の要否、③データ量とスケール要件、④既存インフラ(クラウド/オンプレ)の4点です。以下の判断フローとチェックリストを使って、自社の状況を整理してみてください。
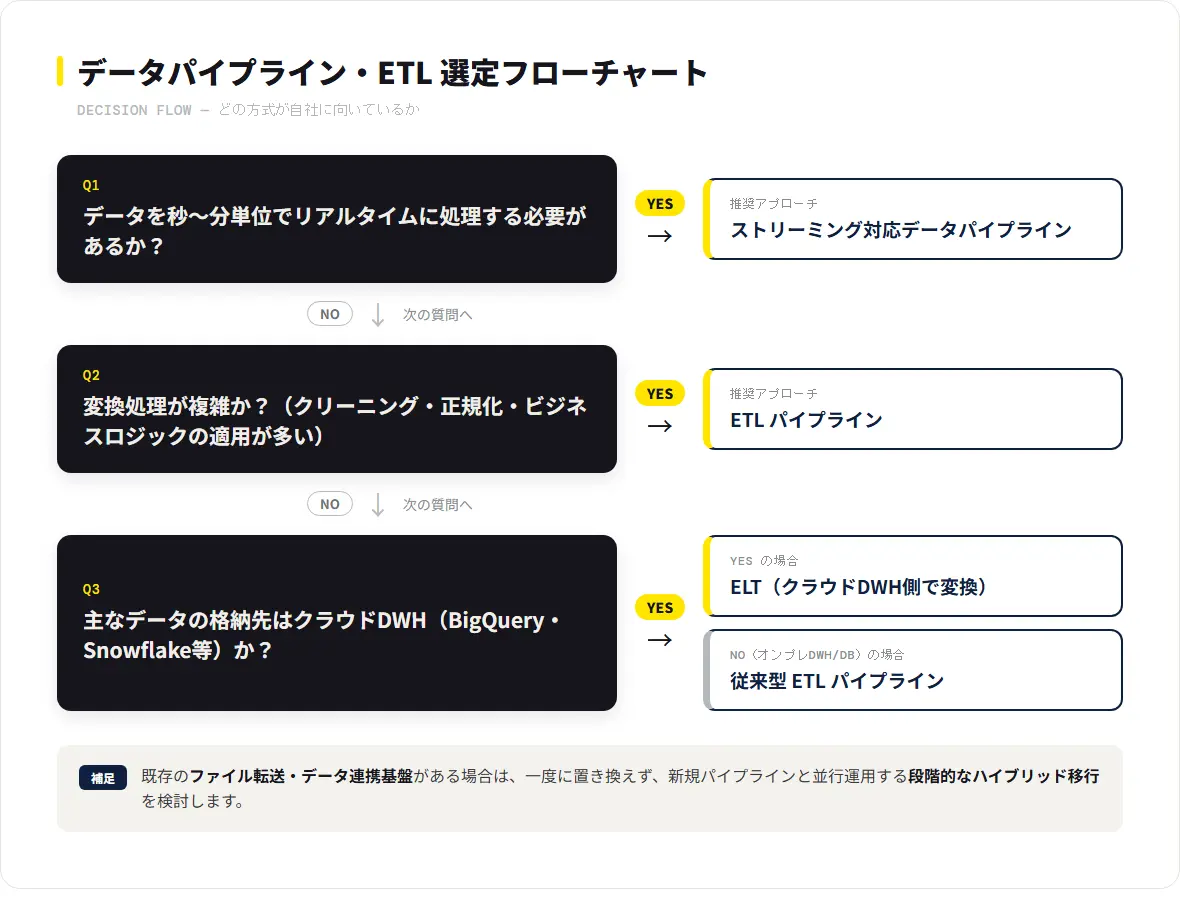
意思決定フロー
次の4つの問いに順番に答えることで、推奨アプローチが絞り込まれます。
Q1. データを秒〜分単位でリアルタイムに処理する必要がありますか?
Q2. 変換処理が複雑ですか?(データクリーニング・正規化・ビジネスロジックの適用が多い)
Q3. データの主な格納先はクラウドDWH(BigQuery・Snowflake・Redshiftなど)ですか?
Q4. 社内にすでにファイル転送基盤や既存のデータ連携システムがありますか?
ユースケース別 推奨アプローチ早見表
ユースケース | 推奨アプローチ | 選択の理由・ポイント |
|---|
基幹DB(SAP/Oracle等)からDWHへの月次・日次バッチ連携 | ETLパイプライン | 複雑な変換処理・バッチで十分・コンプライアンス要件への対応が必要 |
SaaS(CRM・MA・会計)のデータをBIツールで分析 | ELT またはノーコードETLツール | SaaS API連携・準リアルタイム対応・ノーコード運用が現実的 |
製造ラインのIoTセンサーデータをリアルタイム監視 | ストリーミング対応データパイプライン | 秒単位のリアルタイム処理が必須。ストリーミング基盤が必要 |
社内システムのデータをクラウドDWH(BigQuery・Snowflake等)に集約 | ELT(クラウドDWH側で変換) | クラウド側のコンピューティングを活用するのが効率的 |
既存のファイル転送・連携基盤をモダンなデータパイプラインへ段階移行 | ハイブリッド移行(既存基盤+新規パイプラインの並行運用) | 既存資産を活かしながら段階的に移行することでリスクを最小化 |
AI・機械学習モデルへのマルチソースデータ供給 | 汎用データパイプライン | 非構造化・大容量・多様なソースへの対応が必要 |
少人数IT部門での小規模なデータ活用基盤の構築 | ノーコードSaaS型ETL/ELTツール | 専任エンジニアなしでも運用可能。初期コストと学習コストを抑えられる |
製造業・通信業での具体的なETLパイプライン活用事例については、ETLパイプラインとは?仕組みと製造業・通信業での活用事例をご覧ください。
データパイプラインの設計:基本ステップと実装パターン
データパイプラインの設計は、①データソースの洗い出し、②処理方式の選択(バッチ/CDC/ストリーミング)、③変換・ロジックの定義、④監視・エラーハンドリングの設計、⑤ツール選定の5ステップが基本です。特に日本企業では基幹系DBと各種SaaS、ファイルベースのデータが混在するケースが多く、この混在環境を前提とした設計が重要です。
データパイプライン設計の5ステップ
ステップ1: データソースとデータの種類を洗い出す
まず、どのシステムからどのようなデータを取得するかを明確にします。一般的な日本企業では、ERPや会計システムといった基幹DB、SalesforceやkintoneなどのSaaS、定期的にファイルで受け取る外部データ(CSVやExcel)が混在するケースが多くあります。ソースごとに接続方式(API・DB直接接続・ファイル転送・CDC)が異なるため、この段階での洗い出しが後続の設計に大きく影響します。
ステップ2: 処理方式を選択する(バッチ/CDC/ストリーミング)
データの鮮度要件と処理の目的によって、適切な処理方式を選択します。
バッチ処理: 定時(日次・月次)での大量データ転送に向く。処理コストが予測しやすく、運用が安定している
CDC(変更データキャプチャ): DBの更新ログを差分で連携。バッチほど遅延せず、フルストリーミングほど複雑でない中間解として有効
ストリーミング処理: センサーデータや取引ログなど、秒単位でのリアルタイム処理が必要な場合に採用
ステップ3: 変換・ロジックを定義する
データをそのまま転送するのか、変換・加工してから格納するのかを決めます。主な変換処理には、重複データの排除、データ型の統一、マスタデータとの突合(顧客コードの名寄せなど)、集計・サマリの生成があります。変換ロジックはソースシステムの仕様変更の影響を受けやすいため、変更に強い設計(ロジックのドキュメント化・テストの自動化)を意識することが重要です。
ステップ4: 監視とエラーハンドリングを設計する
データパイプラインは一度構築すれば終わりではなく、日常的な運用・監視が必要です。設計段階で考慮すべきポイントとして、パイプラインの処理状況の可視化(成功・失敗・遅延の検知)、失敗時の自動リトライとアラート通知、処理ログの保存と監査証跡の確保、データ品質チェック(異常値・欠損値の検出)があります。特に金融・製造・医療など規制要件が厳しい業界では、監査証跡とデータリネージの追跡が求められます。
ステップ5: ツールを選定する
ステップ1〜4で明確になった要件をもとに、ツールを選定します。主な選定基準は、必要なデータソースとのコネクタが揃っているか、ノーコードで運用可能か・コーディングが必要か、オンプレミス対応かクラウドネイティブか、CDCやリアルタイム処理への対応、コストモデル(接続数課金・データ量課金・フラット課金)です。
オンプレ・クラウドハイブリッド環境での設計ポイント
多くの日本企業では、オンプレミスの基幹システムとクラウドのSaaSが混在しており、既存のファイル転送・連携基盤が社内インフラの一部として定着しているケースも少なくありません。このような環境でデータパイプラインを新規構築・刷新する際は、次の点に注意が必要です。
既存の連携基盤との共存設計: 既存システムをすべて一度に置き換えるのではなく、新旧の仕組みを並行運用しながら段階的に移行する計画が現実的です。特に業務停止リスクの高いシステムは移行優先度を下げ、PoC(概念実証)から始めることを推奨します。
ネットワーク・セキュリティ要件: インターネット非接続のオンプレミスDBに接続するケースでは、セルフホスト型のエージェントやVPN経由での接続が必要になります。エンドポイントの暗号化、認証・認可の管理(SSO・MFA対応)も事前に確認が必要です。
データガバナンスの整合: 複数のシステムにわたるデータ統合では、データのオーナーシップ定義とアクセス権管理を統一する必要があります。部門ごとにデータの定義や形式が異なる「データサイロ」の解消と合わせて設計することで、長期的な運用コストを下げられます。
ETL・データパイプラインツールは、クラウドネイティブ型、OSS型、エンタープライズ型、専用型など多様なカテゴリに分かれており、要件に応じた選択が重要です。クラウド環境との親和性、コネクタ数、ノーコード対応、CDC対応、オンプレとクラウドの混在環境へのサポートが主な選定軸になります。
代表的なツールとその機能・価格・コネクタ数などの詳細な比較については、ETL・データパイプラインツールの詳細比較ガイドをご覧ください。
ファイル転送とデータパイプライン:概念の整理
「データパイプライン」と「ファイル転送」は混同されることがありますが、対象とする範囲が異なります。ファイル転送はシステム間でファイル(CSVや固定長テキストなど)を送受信する仕組みです。データの移動手段の一つとして長く使われてきており、バッチ処理と組み合わせた定時連携の基盤として機能しています。
一方、データパイプラインはファイル転送を処理の一部として含み得るより広い概念です。APIによるリアルタイム連携、DBの直接接続、CDCによる差分連携など、多様な手段を組み合わせてデータの収集から活用までを統合的に管理します。
既存のファイル転送基盤を持つ組織がデータパイプラインへの移行を検討する場合、「既存のファイル転送を即時に廃止してすべてパイプライン化する」のではなく、既存の仕組みをパイプラインの一部として継続しながら、新しいデータソースやユースケースから段階的に適用範囲を広げていくアプローチが現実的です。
まとめ:自社に合ったデータパイプラインの選定と構築へ
この記事では、データパイプラインとETLパイプラインの違いを起点に、ELTとの関係・選定の考え方・設計の基本ステップ・代表的なツールまでを体系的に解説しました。
改めて要点を整理します。ETLパイプラインは変換・バッチ・コンプライアンス要件に向き、データパイプライン(広義)はリアルタイム・大容量・多様なデータ形式に対応します。クラウドDWHを活用する場合はELTも有力な選択肢です。また、既存の連携基盤がある場合は段階的なハイブリッド移行が現実的です。
CData Syncは、250以上のオンプレ・クラウドの業務システムに対してノーコードでデータパイプラインを構築できるETL/ELTツールです。CDCによるニアリアルタイム同期や、dbt Core/Cloudとの連携によるELTワークフローにも対応しており、オンプレとクラウドが混在する日本企業の環境に適したデータ統合基盤を提供します。まずは実際の環境でお試しいただけるCData Syncの無料トライアルをご活用ください。





