こんにちは!コンテンツチームの加藤です。
ETLツールとは、複数のシステムからデータを抽出(Extract)・変換(Transform)・ロード(Load)し、データウェアハウスや分析基盤に統合するソフトウェアです。2026年現在、クラウドネイティブ型からOSS型・エンタープライズ型まで多様な製品が存在し、自社の要件に合ったツールを選ぶことが、データ活用基盤の成否を左右します。
本記事では、代表的なETL・データ統合ツール15製品を種別ごとに比較し、選び方の7基準・用途別の早見表・導入の進め方まで体系的に解説します。「どのETLツールを選べばよいか分からない」「比較軸を整理したい」という方の判断材料としてご活用ください。
目次
ETLツールとは?データ統合における役割
ETLツールとは、異なるシステムやデータソースからデータを抽出(Extract)・変換(Transform)・ロード(Load)する処理を自動化するソフトウェアです。Salesforce・SAP・kintoneなどの業務システム、クラウドデータベース、オンプレミスのDBなど複数のシステムに分散したデータを、データウェアハウスや分析基盤に統合するためのデータパイプラインを構築します。
ETLの仕組みや処理フローを詳しく理解したい方は、ETLとは?仕組みを詳しくをご覧ください。データパイプラインとETLの違いについては、データパイプラインとETLの違いで体系的に解説しています。
ETLツールの選び方|7つの比較基準
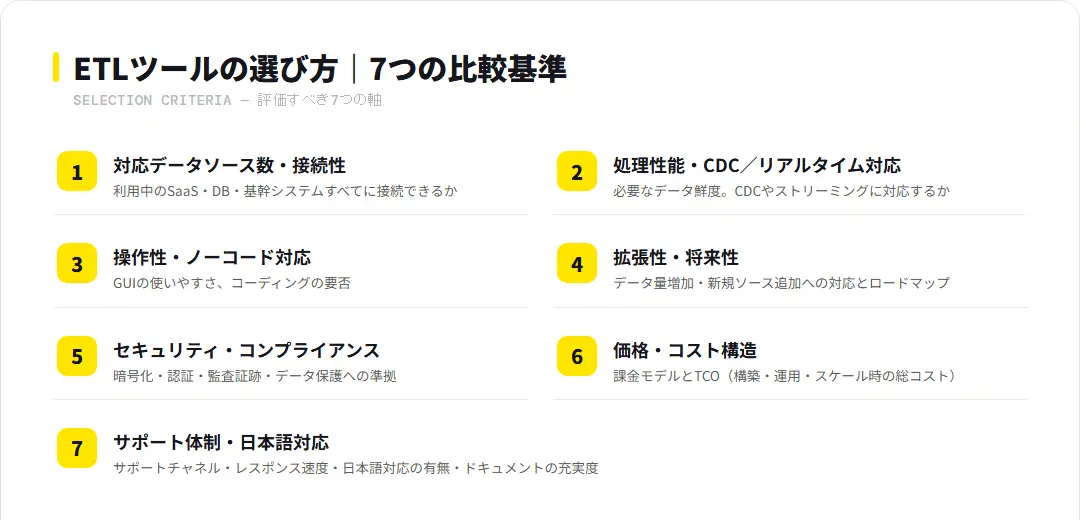
ETLツールを選定する際は、対応データソース数・処理性能・操作性・拡張性・セキュリティ・コスト・サポートの7つの基準を軸に評価することが重要です。以下に各基準のポイントを整理します。
① 対応データソース数・接続性
自社で利用しているSaaS、クラウドDB、オンプレミスの基幹システムすべてに接続できるかを確認します。企業内で複数部門が異なるツールを使っているケースでは、接続できないソースが1つあるだけでカスタム開発が必要になります。利用中のすべてのシステムに対応するコネクタが組み込み済みのツールを優先的に検討してください。特に、今後の追加データソースへの対応方針(ベンダー側で追加するか・自社でカスタム開発できるか)も合わせて確認することが重要です。
② 処理性能・CDCとリアルタイム対応
データをどの頻度・速度で同期する必要があるかは、ツール選定の重要な軸です。日次バッチ処理で十分なケースもあれば、基幹DBの更新をニアリアルタイムで連携したいケースもあります。後者の場合、CDC(変更データキャプチャ)機能に対応しているかが決め手になります。CDCはデータベースの変更ログを差分で連携する方式で、バッチに比べてソースシステムへの負荷を抑えながら準リアルタイムの同期を実現できます。CDC対応の詳細はCDC対応ETLツールの専門記事もご参照ください。
③ 操作性・ノーコード対応
データエンジニアが専任でいるチームでは高いカスタマイズ性が求められますが、IT部門の人員が限られている組織では、コーディングなしでパイプラインを構築・運用できるノーコード・ローコードのインターフェースが重要になります。GUIの分かりやすさ、エラーメッセージの明確さ、設定の容易さを無料トライアルで実際に確認することを推奨します。
④ 拡張性・将来性
データ量の増加や、新たなSaaSツールの追加に対してツールがどう対応できるかを確認します。コネクタの追加コスト・スケールアップ時の料金変動・ベンダーのロードマップなども評価の対象です。クラウドベースのマネージドサービスは、インフラ管理の負荷なくスケールしやすい点でも選ばれています。
⑤ セキュリティ・コンプライアンス
データパイプラインは企業の重要データを扱うため、セキュリティ要件の確認は欠かせません。主な確認事項として、転送中・保存中のデータ暗号化、セキュアDMZアクセスの可否(ファイアウォール内のオンプレDBへの接続)、SSO・MFA対応などの認証機能、データをベンダーのシステムにコピーしない設計(プライバシー保護)、GDPRや個人情報保護法への対応があります。特に金融・製造業では、監査証跡の確保とデータリネージの追跡機能も重要です。
⑥ 価格・コスト構造
ETLツールの価格体系はベンダーによって異なります。接続するデータソース数に基づく課金、転送データ量に基づく課金、ユーザー数に基づく課金など、モデルが異なります。初期費用だけでなく、データ量増加時の費用変動・運用コスト・自社エンジニアの工数も含めたTCO(総所有コスト)で比較することが重要です。OSS型は初期費用を抑えられますが、構築・運用のエンジニアコストが発生します。無料トライアルや無償版で実際の環境を検証してからの判断を推奨します。
⑦ サポート体制・日本語対応
導入後に問題が発生した際、迅速に対応してもらえるか確認します。サポートチャネル(メール・電話・チャット)、レスポンス速度、対応言語(日本語サポートの有無)、ドキュメントの充実度は事前に評価しておくべき項目です。特に日本語でのサポートが受けられるかどうかは、国内での運用において安心感に直結します。
ETL・データ統合ツール比較表【2026年版】
代表的なETL・データ統合ツール15製品を種別・主な特徴・向いている用途の観点で比較しました。主観的なスコアや順位は設けず、各ツールの特性を中立な事実ベースで整理しています。
ツール名 | 種別 | 主な特徴 | 向いている用途(Best For) |
|---|
AWS Glue | クラウドネイティブ型 | S3・RedshiftなどAWSエコシステムと密接に連携するフルマネージドETLサービス。サーバーレスで自動スケール | AWS環境を中心としたデータ統合・分析基盤 |
Azure Data Factory | クラウドネイティブ型 | Microsoft Azure向けのスケーラブルなデータ統合ツール。オンプレとクラウドのハイブリッドワークフローをサポート | Microsoft環境・Azure中心のハイブリッドデータ統合 |
Google Cloud Dataflow | クラウドネイティブ型 | Google Cloud向けのリアルタイム処理とバッチ処理を統合したフルマネージドサービス | Google Cloud環境でのリアルタイム+バッチ統合処理 |
Airbyte | OSS型 | カスタマイズ可能なコネクタを持つオープンソースETL。独自コネクタの開発・追加が可能 | 独自の統合ニーズ・コネクタのカスタマイズが必要な環境 |
Apache Airflow | OSS型 | PythonでETL処理をプログラム的に定義するワークフローオーケストレーションツール | コードで柔軟にETLワークフローを制御したいデータエンジニア |
Talend Open Studio | OSS型 | 幅広いカスタマイズ・統合機能を提供するOSS ETL。グラフィカルなジョブ設計が可能 | 自由度の高いETL設計・複雑な変換処理が必要な環境 |
Hadoop | OSS型 | MapReduceで大規模ETLを実行できる分散ストレージ・処理フレームワーク | ペタバイト規模の大容量データのバッチ処理・分散ETL |
Informatica | エンタープライズ型 | 複雑なデータ環境を管理する包括的ETLソリューション。データガバナンス・品質管理機能を備える | 大規模・複雑なデータ環境・高度なデータガバナンスが必要な企業 |
IBM Infosphere DataStage | エンタープライズ型 | メインフレームを含む大規模システム向けのエンタープライズETL。高スループット処理を得意とする | メインフレーム・大規模基幹システムとのデータ統合 |
Oracle Data Integrator | エンタープライズ型 | Oracle DB等向けのエンタープライズグレードETL。ELT方式を採用し、DB側の処理能力を活用 | Oracle環境中心の大規模エンタープライズデータ統合 |
CData Sync | 専用/ノーコード型 | オンプレ・クラウドの250以上の業務システムに対応。コネクタ組込み済み。CDCによるニアリアルタイム同期・ETL/ELT・リバースETLに対応 | 多様な業務システムとのノーコードデータ統合・CDC連携・リバースETL |
Matillion | 専用/ノーコード型 | Snowflake・Redshift・BigQueryに最適化されたクラウドネイティブETL。GUIベースの直感的な操作性 | クラウドDWH(Snowflake・Redshift・BigQuery)を中心とした分析基盤 |
Hevo | 専用/ノーコード型 | 最小限のセットアップでリアルタイム統合を実現するノーコードETL。迅速な稼働開始が可能 | すぐにデータ連携を始めたい・セットアップコストを最小化したい環境 |
Stitch | 専用/ノーコード型 | セットアップが簡単な軽量ETL。シンプルな設計でスタートアップや小規模チームに向く | スタートアップ・スモールビジネスでのシンプルなデータ連携 |
Microsoft SSIS | 専用/ノーコード型 | SQL Server Integration Services。Microsoft環境向けの信頼性の高いETLプラットフォーム | SQL Server・Microsoft環境を中心とした既存ETLパイプラインの構築・運用 |
※情報は2026年6月時点のものです。各ツールの最新情報は公式サイトをご確認ください。
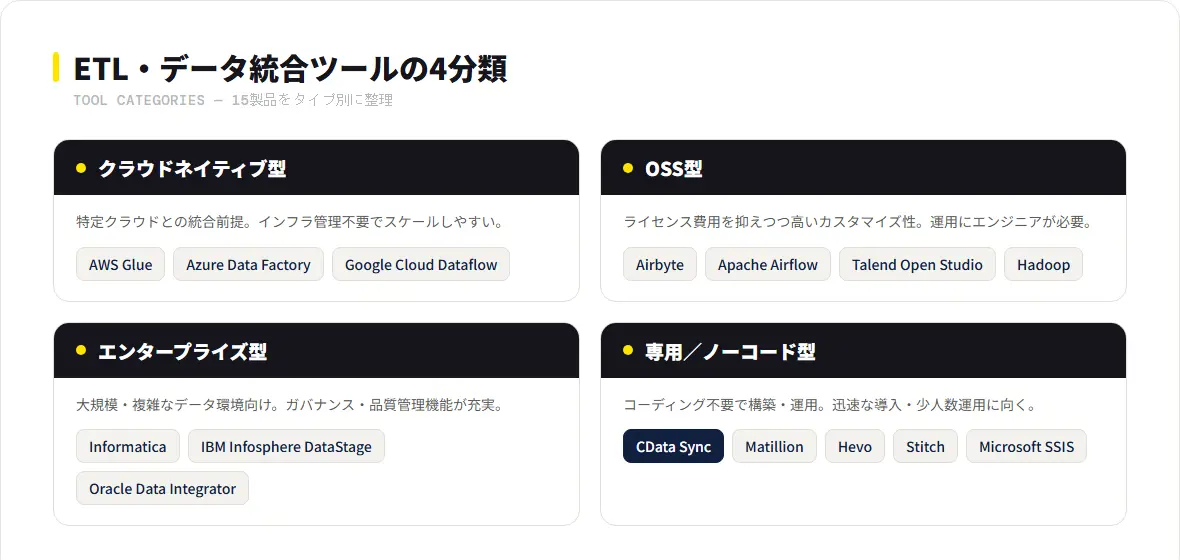
ETL・データ統合ツールは、クラウドネイティブ型・OSS型・エンタープライズ型・専用/ノーコード型の4カテゴリに分類されます。各カテゴリの特性を理解した上で、自社の技術環境・運用体制・予算に合った製品を選定することが重要です。
クラウドネイティブ型
クラウドネイティブ型は、特定のクラウドプラットフォームとの統合を前提に設計されたマネージドETLサービスです。インフラ管理が不要でスケールしやすく、すでに特定のクラウドに基盤を持つ企業に向いています。
AWS Glue
AWS GlueはAmazon Web Servicesが提供するサーバーレスのフルマネージドETLサービスです。S3・Redshift・DynamoDBなどAWSのデータサービスと密接に連携し、データカタログ機能によるスキーマ管理も統合されています。AWSエコシステムを中心にデータ基盤を構築している組織での利用に適しています。
向いている用途: AWS環境を中心としたデータ統合・データレイク・分析基盤の構築
Azure Data Factory
Azure Data FactoryはMicrosoftが提供するクラウドベースのデータ統合サービスです。Azure SQL Database・Azure Synapse Analyticsとの連携はもちろん、オンプレミスのデータソースへの接続もセルフホスト型統合ランタイム経由で対応しており、ハイブリッド環境でのデータ統合を得意とします。
向いている用途: Microsoft Azure環境・オンプレとクラウドが混在するハイブリッドデータ統合
Google Cloud Dataflow
Google Cloud DataflowはGoogle Cloudが提供するフルマネージドのデータ処理サービスです。Apache Beamを基盤とし、バッチ処理とリアルタイムのストリーミング処理を統一的なプログラミングモデルで扱えます。BigQueryとの親和性が高く、Google Cloud上のデータ分析基盤との組み合わせで効果を発揮します。
向いている用途: Google Cloud・BigQueryを中心としたリアルタイム+バッチ統合処理
OSS型
OSS(オープンソースソフトウェア)型は、ライセンスコストを抑えつつ高いカスタマイズ性を確保できる点が特徴です。ただし、構築・運用・メンテナンスにエンジニアリソースが必要になります。
Airbyte
Airbyteはカスタマイズ可能なコネクタを持つオープンソースのELT/ETLツールです。コネクタの自作・改修が可能なため、既製品のコネクタでは対応できない独自システムとの接続ニーズにも応えられます。クラウドホスティング版(Airbyte Cloud)も提供されており、マネージドとセルフホストを選択できます。
向いている用途: 独自コネクタの開発・カスタマイズが必要な環境、OSSを中心としたデータスタック
Apache Airflow
Apache AirflowはPythonでETLパイプラインをプログラム的に定義・スケジューリング・監視するワークフローオーケストレーションツールです。DAG(有向非巡回グラフ)によってパイプラインの依存関係を管理し、複雑なワークフローの実装に対応します。データエンジニアリングチームが主導するデータ基盤構築での採用実績が豊富です。
向いている用途: Pythonによる柔軟なワークフロー定義・複雑な依存関係を持つETLパイプラインの構築
Talend Open Studio
Talend Open StudioはグラフィカルなUIでETLジョブを設計できるオープンソースのETLツールです。幅広いデータソースへのコネクタと豊富なデータ変換コンポーネントを備えており、複雑な変換処理を視覚的に構築できます。エンタープライズ版のTalend Data Fabricも提供されており、要件に応じて移行が可能です。
向いている用途: 高いカスタマイズ性が必要な複雑なETL設計・グラフィカルなジョブ開発
Hadoop
HadoopはMapReduceを基盤とした分散処理フレームワークで、大規模データのバッチETL処理を実行できます。HDFSによる分散ストレージとMapReduceによる並列処理によりペタバイト規模のデータを扱えますが、セットアップと運用には専門的な知識が必要です。現在はSparkとの組み合わせやクラウドマネージドサービス上での利用が一般的になっています。
向いている用途: ペタバイト規模の大容量データバッチ処理・分散ETL環境
エンタープライズ型
エンタープライズ型は大規模・複雑なデータ環境に対応した包括的なETLプラットフォームです。データガバナンス・品質管理・メタデータ管理などの高度な機能を備えますが、導入コストと運用難易度は高めです。
Informatica
Informaticaはデータ統合・データ品質・データガバナンスを包括的に管理するエンタープライズETLプラットフォームです。複雑なデータ環境の管理、コンプライアンス対応、大規模なデータウェアハウスへの統合に強みを持ちます。大手金融機関や製造業での導入実績が豊富です。
向いている用途: 大規模・複雑なデータ環境・高度なデータガバナンスとコンプライアンスが求められるエンタープライズ
IBM Infosphere DataStage
IBM Infosphere DataStageはメインフレームを含む大規模システムとのデータ統合に特化したエンタープライズETLツールです。高スループットの並列処理能力を持ち、金融・保険・通信など大量のトランザクションデータを扱う業種での利用が多い製品です。
向いている用途: メインフレーム・大規模基幹システムとのデータ統合・高スループット処理
Oracle Data Integrator
Oracle Data Integrator(ODI)はOracle DB等向けのエンタープライズグレードETLツールです。ELT(ロード後変換)方式を採用し、ターゲットデータベース側の処理能力を活用した効率的なデータ統合を実現します。Oracle環境を中心とした大規模データ統合に向いています。
向いている用途: Oracle環境中心の大規模エンタープライズデータ統合・ELT方式の活用
専用/ノーコード型
専用/ノーコード型は、コーディングなしでデータパイプラインを構築・運用できる点が最大の特徴です。IT部門の専任エンジニアが限られている組織や、迅速な導入を求める場合に向いています。
CData Sync
CData Syncは、オンプレミスとクラウドの業務システム250以上に対応したノーコードETL/ELTツールです。Salesforce・kintone・SAP・Oracle・NetSuiteなど主要な業務システムのコネクタが組み込み済みで、GUIの操作だけでデータパイプラインを構築できます。
ETLだけでなく、ELT(ロード後変換)とリバースETL(データウェアハウスから業務システムへの逆方向連携)にも対応しており、モダンデータスタックでの柔軟な活用が可能です。CDC(変更データキャプチャ)によるニアリアルタイム同期をサポートし、Oracle・SQL Server・PostgreSQL・SAPなどの基幹DBの更新差分をデータウェアハウスにリアルタイムに連携できます。オンプレミスへの自社ホスティングとクラウドサービスの両方に対応しており、セキュアなDMZアクセスやGDPRコンプライアンスにも準拠しています。日本語サポートが充実しており、国内企業への導入実績も豊富です。
向いている用途: 多様な業務システムとのノーコードデータ統合・CDCによる基幹DB連携・リバースETL・オンプレ/クラウド混在環境
Matillion
MatillionはSnowflake・Redshift・BigQueryなどのクラウドデータウェアハウスに最適化されたクラウドネイティブETL/ELTツールです。GUIベースの直感的なインターフェースで、データエンジニアとアナリスト双方が利用しやすい設計です。クラウドDWH中心の分析基盤の構築・運用に向いています。
向いている用途: クラウドDWH(Snowflake・Redshift・BigQuery)を中心とした分析基盤・dbt連携
Hevo
Hevoは最小限のセットアップでリアルタイムデータ統合を実現するノーコードETLプラットフォームです。データソースを選択するだけで接続が完了し、変換処理もGUIで設定できます。迅速にデータ連携を開始したい場合や、ETL専任エンジニアを置かずに運用したい組織に向いています。
向いている用途: 最小セットアップでのリアルタイムデータ統合・少人数チームでの運用
Stitch
Stitchはシンプルで軽量なクラウドETLサービスです。主要なSaaSやデータベースとの接続が数クリックで完了し、データウェアハウスへのデータ転送を素早く開始できます。大規模な変換処理よりもデータの収集と転送を優先する用途に向いており、スタートアップや小規模チームでの採用が多い製品です。
向いている用途: スタートアップ・スモールビジネスでのシンプルなデータ収集・転送
Microsoft SSIS(SQL Server Integration Services)
Microsoft SSISはSQL Serverに付属するデータ統合・ETLプラットフォームです。Visual Studioベースの開発環境でパイプラインを設計し、SQL ServerやAzureのデータサービスとシームレスに連携します。Microsoft環境で既にSQL Serverを運用している組織が、追加コストを抑えてETL基盤を構築する際の選択肢として利用されています。
向いている用途: SQL Server・Microsoft環境を中心とした既存ETLパイプライン・オンプレ運用
用途・目的別のおすすめ早見表
ETLツールは「何をしたいか」によって最適な選択肢が変わります。以下の早見表で自社の主な用途を確認し、詳細は各専門記事をご覧ください。
用途・目的 | おすすめのアプローチ・ツール例 | 詳細 |
|---|
リアルタイム・準リアルタイム連携が必要 | CDC対応ツール(CData Sync・Google Cloud Dataflow)、ストリーミング対応基盤 | リアルタイムETLツール比較 |
Salesforceのデータを分析基盤に連携したい | Salesforceコネクタ対応ツール(CData Sync・Matillion・Stitch) | Salesforce向けETLツール |
Oracle・SQL ServerなどのCDC(変更データキャプチャ)を活用したい | CDC対応ツール(CData Sync・Debezium・AWS DMS) | CDC対応ETLツール |
dbtと組み合わせたモダンデータスタックを構築したい | dbt連携対応ツール(CData Sync・Matillion・Airbyte) | dbt対応ETL・データ統合基盤 |
無料・低コストでETLを始めたい | OSS型(Airbyte・Apache Airflow・Talend Open Studio) | 本記事「OSS型」セクション参照 |
AWS環境に閉じたデータ統合を構築したい | AWS Glue | 本記事「クラウドネイティブ型」セクション参照 |
Microsoft・Azure環境でのデータ統合 | Azure Data Factory・Microsoft SSIS | 本記事「クラウドネイティブ型」「専用型」セクション参照 |
メインフレームを含む大規模基幹系のデータ統合 | IBM Infosphere DataStage・Informatica | 本記事「エンタープライズ型」セクション参照 |
ノーコードで多様な業務システムと連携したい | CData Sync・Hevo・Stitch | 本記事「専用/ノーコード型」セクション参照 |
ETLツール導入の進め方・注意点

ETLツールの導入はPoC(概念実証)から始め、段階的に適用範囲を広げていくアプローチが現実的です。以下に一般的な導入の流れと主な注意点を整理します。
導入の進め方:3つのフェーズ
フェーズ1: 要件整理とPoC(1〜2ヶ月)
まず、どのシステムのデータをどこに、どの頻度で連携するかを明確にします。接続が必要なデータソースのリストアップ、必要なデータ鮮度(日次バッチで十分か・リアルタイムが必要か)、変換処理の複雑さ、セキュリティ・コンプライアンス要件を洗い出します。その後、候補ツールの無料トライアルで実際のデータ・環境を使って検証します。自社の環境・データで動作することを確認することが、PoC最大の目的です。
フェーズ2: パイロット運用(2〜3ヶ月)
PoCで検証したツールを使い、優先度の高い1〜2本のパイプラインで本格運用を開始します。この段階で、エラーハンドリング・監視・アラート通知の設計と、運用体制の確立を行います。既存の連携基盤がある場合は、並行運用期間を設けて移行リスクを最小化します。
フェーズ3: 段階的な展開(3ヶ月以降)
パイロットで得た知見をもとに、対象データソースとパイプラインの範囲を段階的に拡大します。新しいデータソースへの接続追加や、バッチからCDC/リアルタイムへの処理方式の変更なども、このフェーズで計画的に進めます。
導入時の主な注意点
既存基盤との共存設計: ファイル転送ベースの連携や既存スクリプトをすべて一度に置き換えようとすると、移行リスクが高まります。業務への影響が大きいシステムほど、段階的な移行と並行運用期間の設定を推奨します。
ネットワーク・セキュリティ要件の事前確認: クラウドのETLツールからオンプレミスのDBへの接続には、セルフホスト型エージェントやVPN設定が必要になるケースがあります。セキュリティポリシーとの整合性を事前に確認します。
データ変換ロジックのドキュメント化: パイプラインの変換処理は、ソースシステムの仕様変更の影響を受けやすいため、ロジックの明文化とテストの仕組みを最初から設計に組み込むことが運用コスト削減につながります。
TCO(総所有コスト)での評価: ツールのライセンス費用だけでなく、構築工数・運用人件費・スケールアップ時のコスト変動を含めた総コストで比較することが重要です。特にOSS型は初期コストが低い一方、運用に必要なエンジニアコストを見落としやすい点に注意が必要です。
ETLとELTのどちらの方式が自社に適しているかについては、ETLとELTの違いも参考にしてください。
まとめ:自社に合ったETLツールを選ぶために
本記事では、ETL・データ統合ツール15製品をクラウドネイティブ型・OSS型・エンタープライズ型・専用/ノーコード型の4カテゴリに分類して比較し、選び方の7基準・用途別早見表・導入の進め方を解説しました。
ツール選定のポイントを改めて整理すると、対応データソース数と接続性の確認、CDC/リアルタイム対応の要否、ノーコード運用の可否、セキュリティ要件への対応、総所有コストでの評価が重要な軸です。
多様な業務システムとのノーコードデータ統合を検討されている場合は、250以上のオンプレ・クラウドの業務システムに対応し、CDCによるニアリアルタイム同期・ETL/ELT・リバースETLをノーコードで実現できるCData Syncをご検討ください。無料トライアルで実際の環境・データを使った検証が可能です。
最終更新日:2026年6月10日
CData Syncを実際のデータで試してみませんか?
250以上のオンプレ・クラウドデータソースに対応。ETL / ELT・リバースETL・CDCリアルタイム同期をノーコードで実現します。他ツールとの比較検討にも活用できる30日間の無料トライアルをご用意しています。





