翻訳者ノート
こんにちは!コンテンツチームの加藤です。
Claude をヘビーに活用していると、トークン代が想像以上に膨らみます(Uberなどの企業でも、トークン使用料以上に成果が出ていないとして課題になっているようです)。本記事ではClaudeのトークン使用料をSalesforce・Snowflake・ServiceNow をまたぐ実データで検証し、CData Connect AI の使い方しだいでトークンを最大 97.6% 削減できることを実証しました。「どのワークフローに、Connect AIのどの機能を使えば安くなるか」を判断したい方は、ベンチマーク表だけでも見る価値がありと思います。 |
 Connect AI のユニバーサル MCP ツールは、その名のとおり、Claude があらゆる業務データにアクセスできるようにするための機能です。スキーマは不明、クエリも未定義、使用するデータソースもまだ評価段階…そうした探索的な作業でこそ、このツールセットをまるごと使う価値があります。Claude がカタログを巡回し、スキーマを確認し、複数のデータソースを横断して推論することで、誰も事前に指定していなかった答えを導き出してくれます。この柔軟性には、確かな価値があります。
Connect AI のユニバーサル MCP ツールは、その名のとおり、Claude があらゆる業務データにアクセスできるようにするための機能です。スキーマは不明、クエリも未定義、使用するデータソースもまだ評価段階…そうした探索的な作業でこそ、このツールセットをまるごと使う価値があります。Claude がカタログを巡回し、スキーマを確認し、複数のデータソースを横断して推論することで、誰も事前に指定していなかった答えを導き出してくれます。この柔軟性には、確かな価値があります。
ところが、ワークフローが成熟してプロンプトのパターンが安定してくると、その柔軟性は逆にコストとしてのしかかってきます。AI トークンは高価で、マルチエージェント・マルチソースのエンタープライズ環境では、すべての作業に汎用的なフルアクセスが必要なわけではありません。パターンがすでに見えている場面でツールセットをまるごと使えば、価値を生まない探索ステップやツール定義、その結果にまで料金を払うことになります。Claude Sonnet 4.6 の価格は 入力100万トークンあたり3ドル、出力100万トークンあたり15ドル。どのアーキテクチャを選ぶかが、そのまま運用コストを左右します。
そこで、その差を実際に測ってみました。Salesforce、Snowflake、ServiceNow の実データを対象にベンチマークを行ったところ、トークン使用量は最大 97.6% 削減できることがわかりました。最適化していないパスではクエリあたり 183,541 トークン(0.596 ドル)かかっていたものが、CData Connect AI の機能で最適化すると 4,427 トークン(0.027 ドル)まで下がります。いずれも temperature=0 の条件で 56 回 の独立した実行により検証した数値です。
本記事では、汎用ツールが自律性のスペクトラムのどこに位置するのか、どの Connect AI 機能がアーキテクチャを「決定論的な効率」へと振り向けるのか、その裏付けとなるベンチマーク数値、そして同じアーキテクチャを自社の環境で再現する手順までを順に解説します。
自律性の段階(スペクトラム):ワークフローの位置付けがアーキテクチャを決める
AIエージェントで実行する作業の中には、明確に指示を出す前に探索する必要があるものも多く存在します。スキーマは不明でクエリは未定義、そんな時にはClaudeが複数のデータソースを横断して推論を行い、誰も事前に指定していない答えを見つけ出す必要があります。汎用MCPツールはまさにそうした用途のために構築されており、トークン使用量の増加は十分にコストに見合うものです。
本記事で取り上げる機能が対象とするのは、その対極にあるケースです。確立されたパターン、使うデータソースがあらかじめわかっている状況、スケジュールどおりに繰り返される同じクエリ。こうした場面では、作業の性質にアーキテクチャを合わせることが何より重要になります。自律性の段階については、『自律性のスペクトラムのどこにいても、AIエージェントに必要な条件』で詳しく解説しています。
トークン使用量が企業のコスト要因となる理由
Anthropicのドキュメントによると、トークンとはLLMが読み書きするテキストの最小単位です。Claudeでは1トークンがおよそ3~4文字、英単語にして約4分の3語に相当します。システムプロンプト、ツール定義、クエリ、応答に含まれる文字は、そのすべてが課金対象です。マルチソースのクエリでは、このオーバーヘッドが各レイヤーで積み上がっていきます。
1回の呼び出しでトークンコストを押し上げる要因は、大きく3つあります。
ツール定義のオーバーヘッド。データソースを1つ接続するたびに、そのツールスキーマがリクエストに上乗せされます。Anthropicのエンジニアリングチームの計測では、サーバー5台構成のMCPでは会話が始まる前の時点ですでに約55,000トークンを消費していました。同社の「ツール検索」機能は、ツールの読み込みの大半を後回しにすることで、このフットプリントを最大85%削減しています。
やり取りの積み重ね。ツールを1回呼び出すたびに tool_use ブロックと tool_result ブロックが増えていきます。マルチソースの探索が5ターンも続くと、会話履歴は数万トークン分ふくらみ、しかもその履歴は以降のターンで毎回送り直されます。
スキーマの肥大化。標準のSalesforceアカウントツールは70を超えるフィールドを公開しますが、実際のクエリで使うのはそのうちのほんの一部です。使われないフィールドも、呼び出しのたびにトークンを消費し続けます。
規模を拡大したときにコストが比例して膨らむのか、それともほぼ横ばいに収まるのか。その分かれ目を決めるのが、アーキテクチャの選択です。
ベンチマークシナリオ
テストに使ったクエリは、実際の業務で投げられるプロンプトを想定したものです。「未解決のサポートチケットと、それに関連するSalesforceアカウント、そしてエンタープライズ顧客のSnowflake収益データを表示してください。返すのは最大50行まで。」
これは、1回のエージェントターンの中で、ITSM・CRM・データウェアハウスという3つの独立したシステムをまたいで実行されるフェデレーテッドクエリ(横断検索)です。各シナリオでは Anthropic Messages API の POST /v1/messages/count_tokens を呼び出し、トークン数は呼び出しごと・ターンごとに、レスポンスの usage オブジェクトから直接読み取っています。
パラメータ | 値 |
データソース | Salesforce (CRM)、Snowflake (データウェアハウス)、ServiceNow (ITSM) |
接続方法 | CData Connect AI マネージド MCP |
CData MCPツール | getInstructions, getCatalogs, getSchemas, getTables, getColumns, getProcedures, getProcedureParameters, queryData, executeProcedure, execute_insert, execute_update (11種類のユニバーサルツール)
|
モデル | claude-sonnet-4-6
|
価格参考 | $3.00 / MTok入力、$15.00 / MTok出力(Anthropic定価 2026年5月) |
トークン測定 | Anthropic Messages API レスポンスの usage.input_tokens および usage.output_tokens から、1コールあたり・1ターンあたりで取得 |
実行方法 | 実稼働中のMCPに対する実際のマルチターン実行。Claudeが計画を立て、ツールを呼び出し、結果を取り込み、end_turn に至るまでの一連の流れを実行 |
実行回数 | シナリオごとに temperature=0 で4~16回の独立した実行 |
集計 | 変動の大きいシナリオ(Raw baseline、Derived Views)では中央値、決定論的シナリオでは平均値 |
以下の図は、2つのパスを対比したものです:
ユニバーサルツールパス:Claudeが探索チェーンをひととおり実行するベースラインのルートです。getCatalogs → getInstructions → getSchemas → getTables → getColumns とたどり、queryData を3回個別に呼び出してから、最後に結果をまとめます。完全に探索的なパスで、未知のスキーマに向いており、あえてオープンエンドに設計されています。
最適化パス:Connect AIの機能を使った、たった1回のカスタムツール呼び出しです。探索のオーバーヘッドはありません。ワークフローが安定したあとに選ぶべきアーキテクチャです。
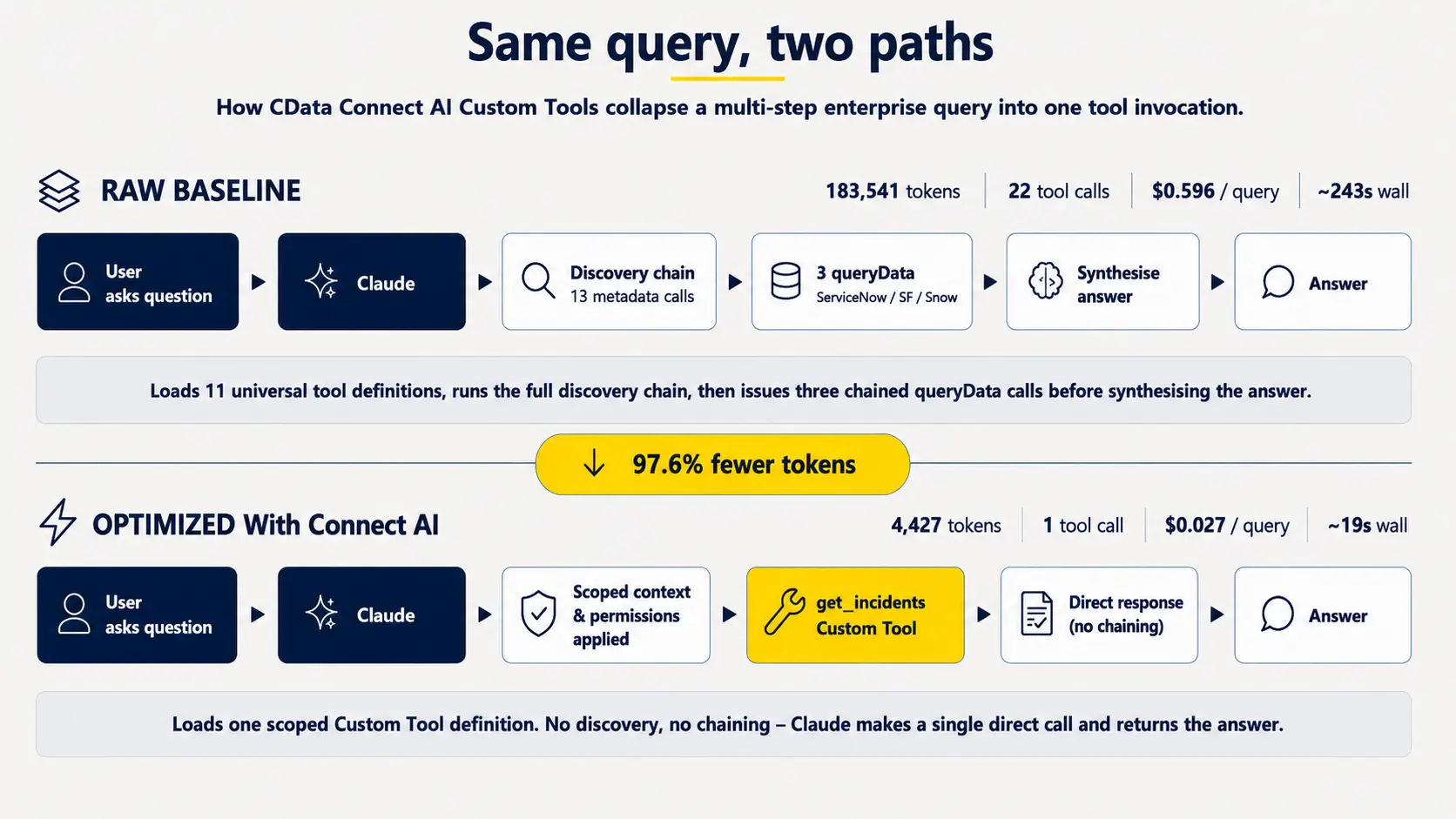
トークンの流れの比較:生のベースラインと最適化パス。
数値:Connect AI を使用した Claude Sonnet 4.6 において、最大 97.6% のトークン削減を実現
各Connect AI機能は、同じ探索的ベースライン(ユニバーサルツールパス)を基準に1つずつ測定しました。ワークフローがスペクトラムの決定論的な側に寄るほど、何ができるようになるかが見えてきます。
ベンチマーク結果の一覧は次のとおりです。
Connect AI機能 | トークン総数 | ツール呼び出し数 | 削減率 | クエリあたりの費用(USD) | 10,000クエリあたり月額 | 10万クエリあたりの月額 |
基本料金 | 183,541 | 22 | N/A | 0.596 | 5,950 | 59,500 |
派生ビュー | 40,983 | 4 | 77.7% | 0.146ドル | 4,495ドル | 44,950ドル |
ワークスペース | ↓ 11,713 | ↓ 3 | ↓ 93.6% | 0.049ドル | 5,469ドル | 54,691ドル |
ジョブ / キャッシュ | 19,778 | 2 | 89.2% | 0.075ドル | 5,205ドル | 52,051ドル |
カスタムツール | ↓ 4,427 | ↓ 1 | ↓ 97.6% | 0.027ドル | 5,691ドル | 56,906ドル |
ツールキット | 16,384 | 3 | 91.1% | 0.063ドル | 5,329ドル | 53,291ドル |
AIスキル | 16,940 | 1 | 90.8% | 0.058ドル | 5,377ドル | 53,768 |
合計(全機能) | ↓ 11,791 | ↓ 3 | 93.6% | 0.049ドル | 5,468 | 54,681ドル |
この結果から言えること
カスタムツールはトークンを97.6%削減します。ツール定義のスコープを絞ることでクエリあたりのコストが下がり、ワークロードが拡大しても支出を予測しやすく保てます。
ワークスペース、ツールキット、AIスキル、キャッシュ、そしてこれらを組み合わせたスタックは、いずれも89~94%削減します。削減効果はほぼ同等なので、ワークフローに合った機能を選べば十分です。
派生ビューの削減率は77.7%です。複数のデータソースにまたがるデータをあらかじめ結合しておくことで、同じクエリを投げるたびにエージェントが結合を組み立てる手間がなくなります。
クエリあたりのコストは0.596ドルから0.027ドルに下がります。月10万クエリなら、トークンコストを月あたり約57,000ドル圧縮できる計算です。
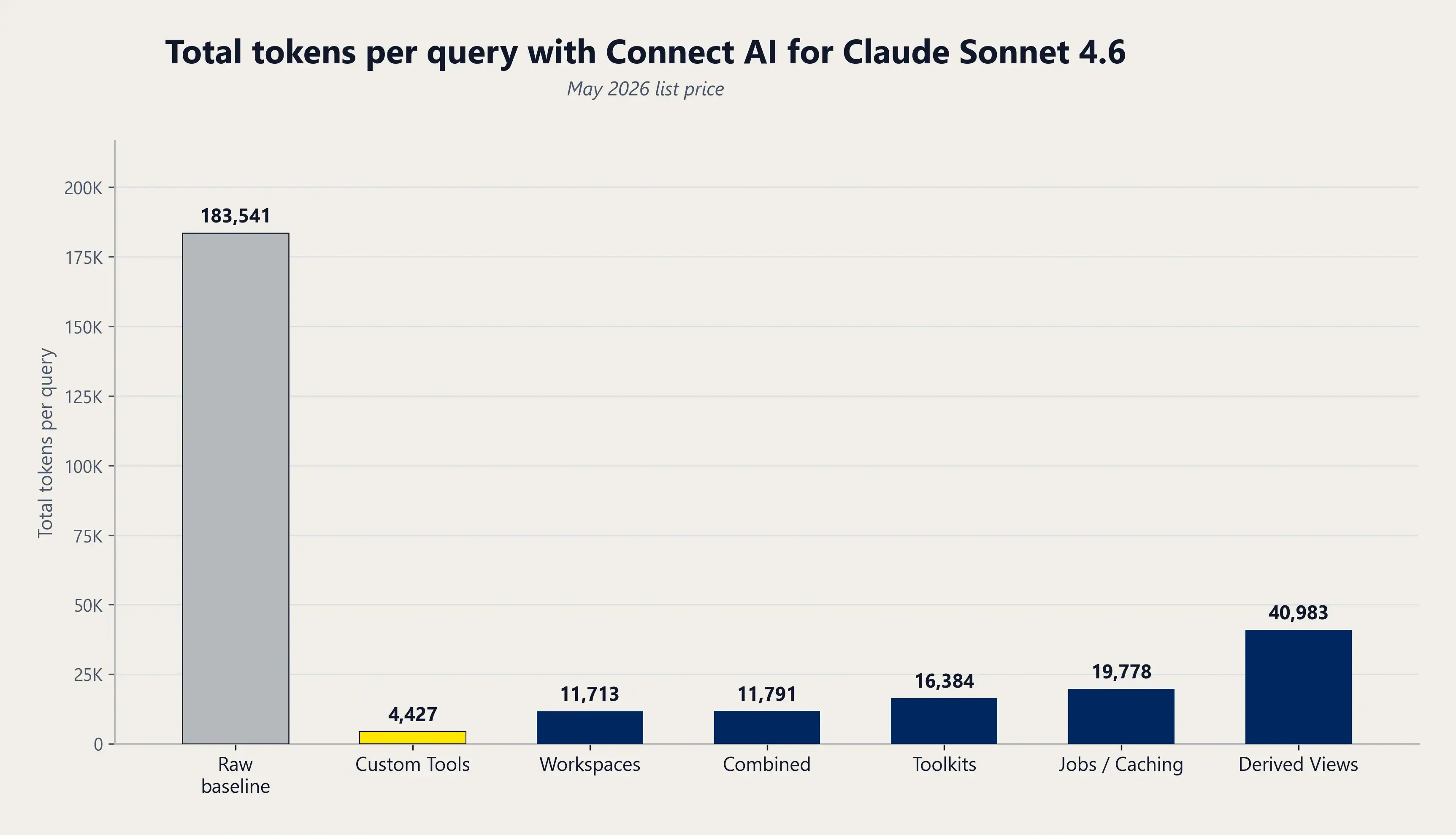
各ベンチマークシナリオのクエリあたりトークン数(入力対出力)。
さらに、次の2つの効果が掛け合わさります。
各Connect AI機能がトークンを削減する仕組み
どの機能も、リクエストがClaudeに届く前に、特定の種類のオーバーヘッドを削り落とします。やり方はそれぞれ違っても、狙いは共通しています。ワークフローが固まって安定したら、Claudeに送るデータを減らし、できるだけ手前で送ることです。いずれも、探索の段階を終え、定義済みの再現可能なパターンで動いているワークフローのために設計されています。

Connect AI機能によるトークン削減効果(降順)。
派生ビュー:マルチソースデータの事前結合
派生ビューは、CREATE DERIVED VIEW という SQL 文で定義する、再利用可能な仮想テーブルです。複数のデータソースにまたがる結合・フィルタリング・変換をひとまとめに隠すため、AI からは最終的な結果だけが見えます。ベンチマークで使ったビュー BM_Incident_Account_Revenue では、ServiceNow のインシデント、Salesforce のアカウント、Snowflake の商談収益をあらかじめ結合しています。
測定結果:40,983トークン(16回実行の中央値)、77.7%削減。3つのデータソースのスキーマが1つにまとまり、複数回の呼び出しを束ねるオーケストレーションが不要になります。クエリあたりの実処理時間は242.8秒から約50秒へ短縮されました。
ワークスペース:Claudeが参照するデータカタログの範囲を定義
ワークスペースは、Connect AI 内のデータカタログとして働きます。テーブル・ビュー・派生ビューを名前付きのグループにまとめ、専用のエンドポイント(REST、MCP、OData、OpenAPI)を発行します。その結果、各 AI エージェントから見えるのは、ワークスペースの所有者が公開したアセットだけです。今回のベンチマーク用ワークスペースでは、関連する3つのカスタムツールだけを公開し、ほかは一切見せていません。
測定結果:11,713トークン(6回実行の平均、変動幅0.1%)、93.6%削減。ツールの一覧を絞ると、Claudeが無関係なデータソースを探りにいくのを防げるため、コスト削減だけでなくガバナンスの面でも効果があります。
ジョブとキャッシュ:結果の事前取得と再利用
Connect AIジョブを使うと、管理者が対象のテーブルを選び、マネージドのPostgreSQLストアへ定期的にキャッシュしておけます。いったんキャッシュすれば、クエリは元のライブのデータソースではなくローカルのコピーを参照するので、Claudeは探索やライブ取得の往復を省いて、すばやく応答を返せます。
測定結果:19,778トークン(4回実行の平均、ばらつき0.0%)、89.2%削減。1時間ごと・1日ごとの更新で間に合うような、高頻度で繰り返すクエリに向いています。
カスタムツール:Claudeが必要とするスキーマのみを公開
カスタムSQLツールは、ツールキットの中で管理者が定義する、パラメータ化されたSQLテンプレートです。ワークフローに必要なフィールド・フィルター・パラメータだけに絞り込んだクエリを、AIが直接呼び出せる名前付きツールとして公開します。今回のカスタムツールでは、標準では73カラムあるSalesforceアカウントのスキーマを、6カラムだけに絞った定義に置き換えました。
測定結果:4,427トークン(6回実行の平均、ばらつき0.8%)、97.6%削減。今回のベンチマークで、単一機能としては最も効果の大きい最適化でした。クエリあたりの実時間は19秒。ツールを1回呼び出すだけで、整った形のデータと回答が返ってきます。
ツールキット:ワークフローごとの厳選ツールバンドル
ツールキットは、カスタムツールと接続ツールを、専用のMCPエンドポイントを持つ名前付きのコンテナにまとめたものです。ワークスペースがデータカタログ単位でスコープを決めるのに対し、ツールキットはワークフロー単位でスコープを決めます。営業向け、財務向け、サポート向けといった具合です。
測定結果:16,384トークン(6回実行の平均、ばらつき0.0%)、91.1%削減。このツールキットは、3つのデータソース接続と3つのカスタムツールを、合わせて16のツールとして束ねています。Claudeは、汎用のディスカバリーツールよりも、名前のついたカスタムツールを一貫して選びます。
AIスキル:事前パッケージ化されたタスクパターン
AIスキルは、必要なツール、システムへの指示、想定するレスポンス形式をひとまとめにし、1回呼び出すだけで動くワークフローとしてパッケージ化します。Connect AIでは、スコープを定めたツールキットと、SQLやレスポンス形式をあらかじめ指定した制約の強いシステムプロンプトを組み合わせて実現しています。
測定結果:16,940トークン(6回実行の平均、ばらつき0.2%)、90.8%削減。これは、Claudeが計画に費やすトークンをなくせたことが効いています。ワークフローがあらかじめ決まっているため、出力トークンはベースラインより80%以上少なくなります。
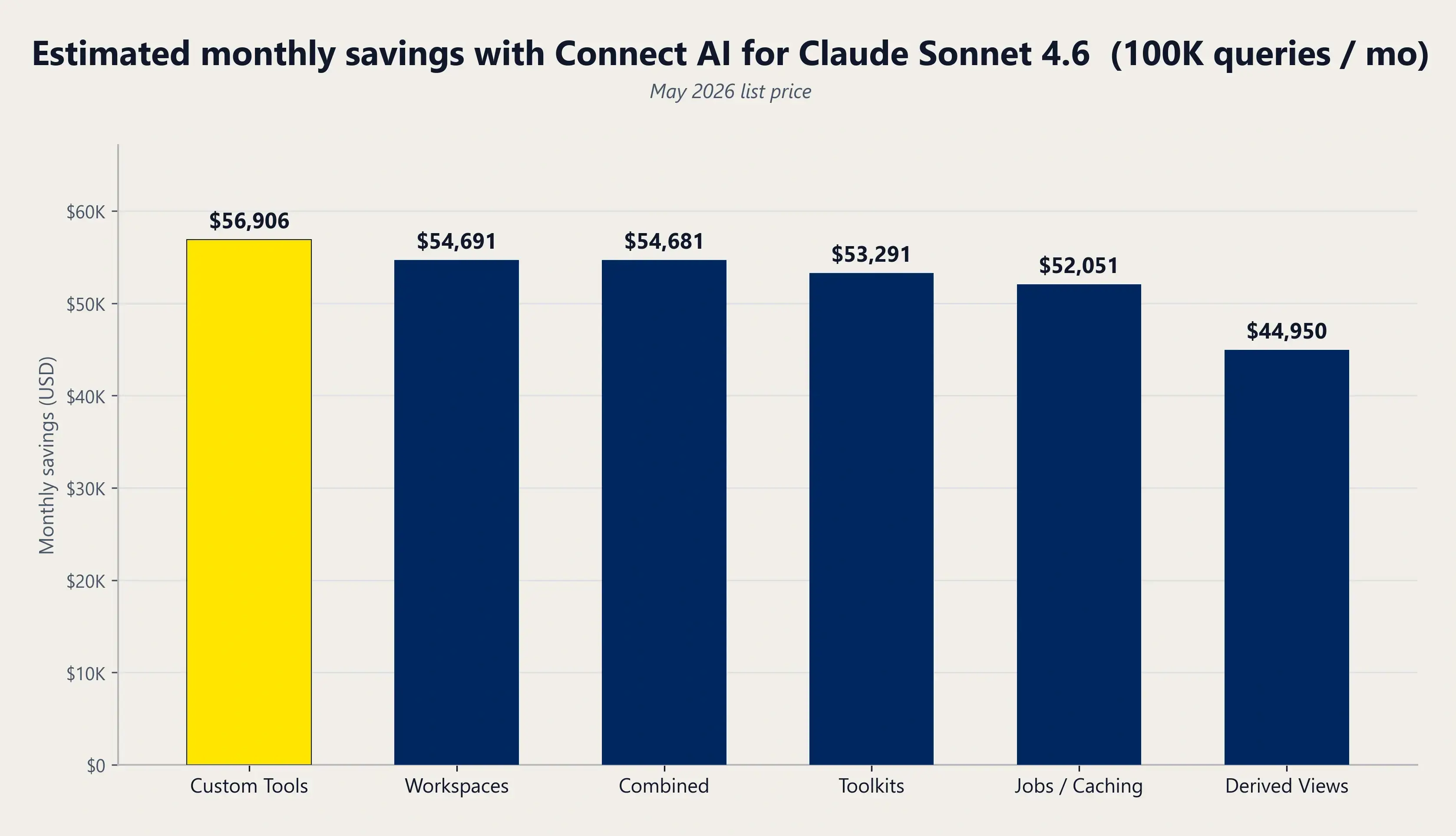
クエリ量の各階層における、機能ごとの月間推定削減額(米ドル)。
CDataからの提案:このアーキテクチャを自社のAIワークフローに取り入れる
どこから手をつけるべきかは、ワークフローが自律性のスペクトラムのどこにあるかで変わります。まだ探索段階で、データソースを見極めたり、クエリを試作したり、その場限りの分析をしている段階なら、ユニバーサルツールパスが向いています。Claudeに発見・推論・試行錯誤を任せましょう。このときのトークンのオーバーヘッドは、本物の柔軟性を得るための対価です。
ワークフローが繰り返し使えるパターンとして固まってきたら、次の機能が、探索段階から本番運用へ移るいちばんの近道になります。
1. まずはワークスペースから。データカタログの範囲を、各Claudeセッションが本当に必要とするものだけに絞ります。300個のツールではなく、3個だけを公開するイメージです。
2. よく使うコネクタにはカスタムツールを。スキーマを、そのワークフローが実際に読むフィールドだけに絞り込みます。Salesforceアカウントの例なら、ツール定義をおよそ80%小さくできます。
3. 何度も使う複数データソースの結合は、派生ビューにまとめます。毎回Claudeに3回の呼び出しを段取りさせる代わりに、サーバー側で結合を済ませておきます。
4. リアルタイムでなくてよいデータは、ジョブでスケジュール化します。1時間ごとの更新で間に合うクエリは、すべてキャッシュに載せておきましょう。
5. 成熟したワークフローは、AIスキルとしてパッケージ化します。動きが安定したらワークフローをそのまま定義に落とし込み、Claudeが呼び出しのたびに計画を立て直さなくても、最適化されたパスをたどれるようにします。
6. 最後に、これらをワークフロー単位でツールキットにまとめます。営業・財務・サポートがそれぞれ専用のセットを持ち、対応するClaudeセッションに紐づけられます。
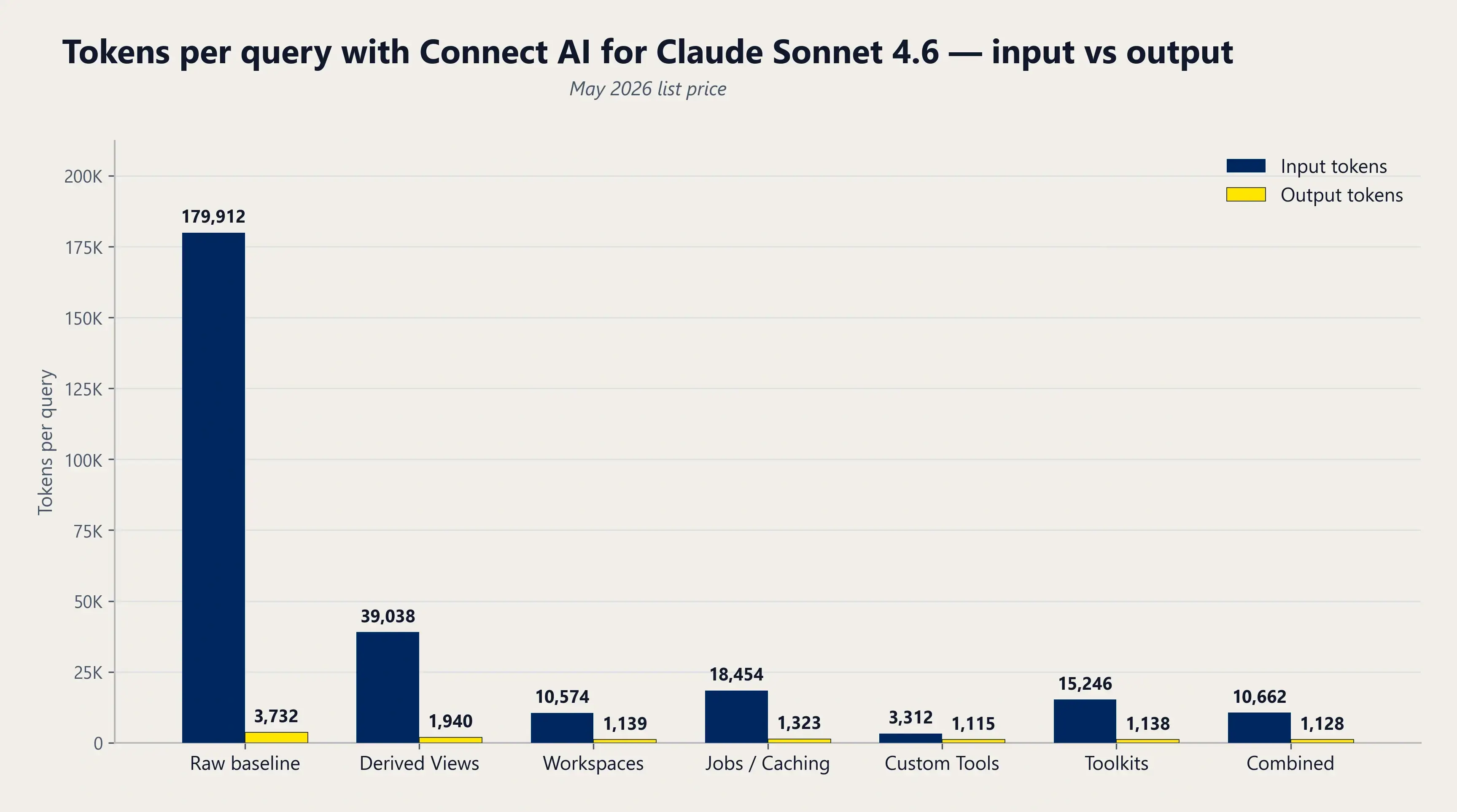
クエリあたりの総トークン数:生のベースラインと各Connect AI機能の比較。
よくある質問
Claudeが企業データをクエリする際、トークン使用量が高くなる原因は何ですか?
主な要因は3つです。接続しているデータソースが多いほど膨らむツール定義のリスト、Claudeが発見とクエリを順番に繰り返す多段階のチェーン、そしてツールごとに返ってくる冗長な生のAPIレスポンスです。トークン量は、プロンプトの言い回しよりもアーキテクチャの選択に大きく左右されます。
トークンの最適化は、Claudeの回答の質に影響しますか?
正しく使えば、むしろノイズが減って回答の質は上がります。スコープを絞ったツール一覧や、あらかじめ結合しておいた派生ビューがあれば、Claudeが推論時に振り回される無関係な情報が減るからです。
現在のClaude環境におけるトークン使用量を測定するにはどうすればよいですか?
Connect AIのどの機能が最大の節約効果をもたらしますか?
単一機能としては「カスタムツール」が97.6%で最大でした。ただし最適解はワークフロー次第です。接続するデータソースが多いチームは「ワークスペース」と「ツールキット」、複数のデータソースをまたぐ結合が多いチームは「派生ビュー」、安定して同じ処理を繰り返すチームは「キャッシュ」と「AIスキル」が、それぞれいちばん効きます。
最適化を行わず、ユニバーサルツールを使い続けるべきなのはどのような場合ですか?
ワークフローが本当に探索的なとき(スキーマの発見、その場限りの分析、試作、クエリの形が事前に読めないタスクなど)は、ユニバーサルツールが適しています。今回のベンチマークの最適化機能は、あくまで繰り返しのパターンが固まったワークフロー向けです。パターンがまだ定まらないうちはClaudeに自由に探索させ、形が見えてから最適化に移ってください。自社のワークフローがどの段階かを見極める方法は、「自律性のスペクトラムのどこにいても、AIエージェントに必要な条件」で解説しています。
これらのパターンは他のLLMにも適用されますか?
このアーキテクチャの考え方は、トークン課金型のLLMすべてに当てはまります。Connect AIはMCP準拠の設計なので、Claude、Microsoft Copilot、Cursor、n8nなど、MCPに対応したクライアントであれば、どれでも同じ機能を使えます。
CData Connect AIによるクエリごとのトークン削減
エンタープライズAIが採算に乗る規模までスケールできるかどうかは、アーキテクチャで決まります。そして最適なアーキテクチャは、ワークフローごとに違います。汎用ツールはエージェントに探索の自由を与え、ワークスペース・ツールキット・カスタムツール・派生ビュー・AIスキルは、本番ワークフローへスケールさせるための効率をもたらします。
CData Connect AIは、マルチソースのデータ統合を、ガバナンスの効いた単一のMCPエンドポイントに集約します。350以上のコネクタ、アイデンティティ起点のセキュリティ、そして本記事で紹介した機能を、一度設定すればあらゆるClaudeワークフローで再利用できます。
Web完結のデモを試して、ご自身の業務データで同じベンチマークを実行してみてください。
業務データをAIで使える形に。
CData Connect AI を使えば、AIアシスタントやエージェントが、350 以上の業務システムへリアルタイムに、しかも管理された形でアクセスできます。AI は学習データだけに頼らず、自社の実データにもとづいて判断できるようになります。





